Understanding Kafka Producer Part 1
Today, we present a comprehensive analysis of Kafka Producer (based on [Apache Kafka 3.7][2]). Due to space limitations, this article is divided into two parts: the first part will introduce the usage and implementation principles of Kafka Producer, while the second part will discuss the implementation details and common issues of Kafka Producer.
Before delving into the specific implementation details of the Kafka Producer, let's first take a look at how to use it. The following example code demonstrates how to send a message to a specified Topic using Kafka Producer:
// Configure and create a Kafka Producer
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", "localhost:9092"); // Kafka cluster address
kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // Key serializer
kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // Value serializer
Producer<String, String> producer = new KafkaProducer<>(kafkaProps); // Create producer instance
// Send a message to target topic
ProducerRecord<String, String> record =
new ProducerRecord<>("my-topic", "my-key", "my-value"); // Message record (Topic, Key, Value)
producer.send(record, (metadata, exception) -> { // Asynchronous send
if (exception != null) {
// Failed to send
exception.printStackTrace(); // Print exception stacktrace
} else {
// Successfully sent
System.out.println("Record sent to partition "
+ metadata.partition() // Target partition
+ " with offset " + metadata.offset()); // Message offset
}
});
// Release producer resources
producer.close(); // Graceful shutdown
Next, we will provide a detailed introduction to the main interfaces of the Kafka Producer.
public class ProducerRecord<K, V> {
private final String topic;
private final Integer partition;
private final Headers headers;
private final K key;
private final V value;
private final Long timestamp;
}
public interface Callback {
void onCompletion(RecordMetadata metadata, Exception exception);
}
public interface Producer<K, V> {
// ...
Future<RecordMetadata> send(ProducerRecord<K, V> record);
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback);
void flush();
void close();
// ...
}
Note: In the Producer interface, there are additional transaction-related interfaces such as beginTransaction and commitTransaction. These are elaborately discussed in our other article on the principles: Kafka Exactly Once Semantics: Idempotence and Transactional Messaging, and will not be repeated here.
A message sent by the Producer contains the following attributes:
-
topic: Required. It specifies the Topic to which the record is sent. -
partition:Optional. Used to specify the partition number (zero-indexed) to which the record will be sent. If not set, the user-specified partitioner or the BuiltInPartitioner will be used to select the partition (see [below] for details). -
headers: Optional. Custom user-defined additional key-value information. -
key: Optional. The key of the message. -
value:Optional. The content of the message. -
timestamp: Optional. The timestamp when the message is sent. The generation logic is as follows:-
If the
message.timestamp.typefor the Topic is configured asCreateTime,-
If the user specifies a timestamp, use the specified value.
-
If not, use the time the message was created (approximately the time the send method was called).
-
-
If the topic's message.timestamp.type is set to "LogAppendTime", the time the message is written on the broker is used regardless of whether the user specified a timestamp or not.
-
The callback after the message is acknowledged for sending. Possible exceptions include:
-
Non-retriable
-
InvalidTopicException: The topic name is invalid, such as being too long, empty, or containing illegal characters.
-
OffsetMetadataTooLarge: The metadata string used is too long when calling Producer#sendOffsetsToTransaction (controlled by offset.metadata.max.bytes, default 4 KiB).
-
RecordBatchTooLargeException: The size of the sent batch.
-
Exceeded the maximum allowed size (broker configuration message.max.bytes or topic configuration max.message.bytes, default 1 MiB + 12 B)
-
Exceeded the segment size (broker configuration log.segment.bytes or topic configuration segment.bytes, default 1 GiB)
-
Note: This error is likely to occur only in older versions of the Client
-
RecordTooLargeException: The size of a single message
-
Exceeded the producer's maximum request size (producer configuration max.request.size, default 1 MiB)
-
Exceeded the producer buffer size (producer configuration buffer.memory, default 32 MiB)
-
Exceeded the maximum allowed size (broker configuration message.max.bytes or topic configuration max.message.bytes, default 1 MiB + 12 B)
-
-
TopicAuthorizationException, ClusterAuthorizationException: Authorization failed
-
UnknownProducerIdException: The PID has expired or all records associated with the PID have expired in a transactional request.
-
InvalidProducerEpochException: The epoch is invalid in a transactional request.
-
UnknownServerException: Unknown error
-
-
Retriable
-
CorruptRecordException: CRC check failed, usually caused by network errors.
-
InvalidMetadataException: Client-side metadata has expired.
-
UnknownTopicOrPartitionException: The topic or partition does not exist, possibly due to expired metadata.
-
NotLeaderOrFollowerException: The requested broker is not the leader, possibly in the process of leader election.
-
FencedLeaderEpochException: The leader epoch in the request has expired, possibly due to slow metadata refresh.
-
-
NotEnoughReplicasException, NotEnoughReplicasAfterAppendException: Insufficient number of in-sync replicas (configured via broker setting min.insync.replicas or the same-named topic configuration, default is 1). Note that NotEnoughReplicasAfterAppendException occurs after records have been written, and retries by the producer may result in duplicate data.
-
TimeoutException: Processing timeout, with two possible causes:
-
Synchronously calling takes too long, for example, when the producer buffer is full, or metadata retrieval times out.
-
Asynchronous calls time out, such as when the producer is throttled and does not send, or the broker times out without responding.
-
-
Asynchronously send a message, and if necessary, trigger a Callback after this message is acknowledged.
Guarantee that the Callback for send requests to the same partition will be triggered in the order of the calls.
Mark all messages in the producer cache as immediately available for sending and block the current thread until all previous messages have been acknowledged.
Note: This will only block the current thread, allowing other threads to continue sending messages normally. However, the completion timing of messages sent after calling the flush method is not guaranteed.
Close the producer and block until all messages are sent.
Note:
-
Calling close within the Callback will immediately close the producer.
-
The send method still in the synchronous call phase (fetching metadata, waiting for memory allocation) will be terminated immediately and throw a KafkaException.
The following section introduces the specific implementation of the Kafka Producer, which consists of several core components:
-
ProducerMetadata&MetadataResponsible for caching and refreshing the metadata needed by the Producer, including all metadata of the Kafka Cluster, such as broker addresses, the distribution status of partitions in topics, and leader and follower information.
-
RecordAccumulatorResponsible for maintaining the Producer buffer. It batches messages to be sent based on partition dimensions, accumulates them into RecordBatch based on time (linger.ms) and space (batch.size), and awaits sending.
-
SenderMaintains a daemon thread "kafka-producer-network-thread | {client.id}" responsible for driving the sending of Produce requests and processing Produce responses. It also handles timeout processing, error handling, and retries.
-
TransactionManagerResponsible for implementing idempotence and transactions. This includes assigning sequence numbers, handling message loss and out-of-order issues, maintaining transaction status, etc.
The process of sending a Message is illustrated in the diagram below:

It is divided into the following steps:
-
Refresh Metadata
-
Use the specified Serializer to serialize the Message
-
Using a user-specified Partitioner or BuiltInPartitioner to select the target partition for sending messages
-
Inserting messages into the RecordAccumulator for batching
-
The sender asynchronously fetches sendable batches from the RecordAccumulator (grouped by node), registers callbacks, and sends them
-
The sender handles responses and returns results, exceptions, or retries based on the scenario
Next, we will introduce the details of each component
ProducerMetadata is responsible for caching and refreshing the metadata required by the Producer. It maintains a topic view that encompasses all topics required by the producer. It will
-
add topics in the following scenarios:
- When a message is sent, the specified topic is not found in the cached metadata.
-
Remove a topic in the following scenarios:
- When it is found that the metadata for a topic has not been used for the duration specified by metadata.max.idle.ms
-
Refresh metadata in the following scenarios:
-
When sending a message, the specified partition is not in the cached metadata (this can occur when the number of partitions for the topic increases).
-
When sending a message, the leader of the specified partition is unknown.
-
When a message is sent and an InvalidMetadataException response is received,
-
When metadata.max.age.ms continuously fails to refresh the metadata,
-
Relevant configurations include:
-
metadata.max.idle.ms
The cache timeout for topic metadata. Specifically, if no message is sent to a specific topic beyond the designated time, the metadata for that topic will expire. The default is 5 minutes.
-
metadata.max.age.ms
Metadata mandatory refresh interval: triggers an update if metadata has not been refreshed within the specified duration. Default is set to 5 minutes.
In KIP-794[3], to solve the issue in previous versions where the Sticky Partitioner led to sending more messages to the slower broker, a new Uniform Sticky Partitioner was proposed (and became the default built-in Partitioner). In the absence of a key constraint, it will send more messages to the faster broker.
When selecting partitions, there are two scenarios:
-
If the user specifies a Partitioner, the specified Partitioner is used to select the partition.
-
If not, the default BuiltInPartitioner is used.
-
If a record key is set, a unique partition is chosen based on the key's hash value. Specifically,
-
Records with the same key will always be assigned to the same partition.
-
However, if the number of partitions for a topic changes, it does not guarantee that the same key will still be assigned to the same partition before and after the change.
-
-
If no key is set, or if partitioner.ignore.keys is set to "true," the default strategy will be used—sending more messages to the faster broker.
-
Relevant configurations include:
-
partitioner.classThe class name of the partition selector can be customized by the user according to their needs. Some default implementations are provided.
-
DefaultPartitioner and UniformStickyPartitioner: These "stickily" assign Messages to each partition, meaning they switch to the next partition after one partition accumulates a full batch. However, there are issues with their implementation that lead to more Messages being sent to slower brokers. They are now marked as deprecated.
-
RoundRobinPartitioner: This implementation ignores the record key and assigns Messages to each partition in a round-robin fashion. Note that it has a known issue: it causes uneven distribution when creating new batches.
It is currently recommended to use the built-in partitioners or implement your own.
-
-
partitioner.adaptive.partitioning.enable
Determines whether to adjust the number of messages sent based on broker speed. If disabled, messages will be randomly assigned to partitions. This setting only takes effect if
partitioner.classis not configured. Default is "true". -
partitioner.availability.timeout.ms
This setting is effective only when
partitioner.adaptive.partitioning.enableis set to "true". When the "time of batch creation for the specified broker" and the "time of sending messages to the specified broker" exceed this configuration, messages will no longer be allocated to the specified broker. Setting it to 0 means this logic is disabled. This setting is applicable only whenpartitioner.classis not configured. The default value is 0. -
partitioner.ignore.keys
When selecting a partition, whether to ignore the message key. If set to "false", the partition is chosen based on the hash value of the key. Otherwise, the key is ignored. This only takes effect if partitioner.class is not configured. The default value is "false".
In the RecordAccumulator, all pending batches to be sent are maintained by partition. The following are several important methods:
public RecordAppendResult append(String topic,
int partition,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
AppendCallbacks callbacks,
long maxTimeToBlock,
boolean abortOnNewBatch,
long nowMs,
Cluster cluster) throws InterruptedException;
public ReadyCheckResult ready(Metadata metadata, long nowMs);
public Map<Integer, List<ProducerBatch>> drain(Metadata metadata, Set<Node> nodes, int maxSize, long now);
-
append: Inserts a message into the buffer, registers a future, and returns it. This future will be completed when the message is sent (successfully or unsuccessfully).
-
ready: Selects a list of nodes that have messages ready to be sent. The following are the scenarios:
-
Already accumulated messages have reached the batch.size.
-
The batching has continued for longer than linger.ms.
-
The memory allocated to the producer is exhausted, i.e., the total size of messages in the buffer exceeds buffer.memory.
-
The batch needing retries has already waited for at least retry.backoff.ms.
-
The user invoked Producer#flush to force-send messages.
-
Shutting down producer
-
-
drain: For each node, iterate over each partition on the node and retrieve the earliest batch from each partition (if available), until either the max.request.size of messages is aggregated or all partitions have been traversed.
Relevant configurations include:
-
linger.ms
The maximum time each batch will wait. Defaults to 0.
It is worth noting that when set to 0, it does not mean batching will not occur, but rather that no waiting will take place before sending. If you wish to disable batching, batch.size should be set to 0 or 1.
Increasing this configuration will:
-
Improve throughput (the overhead for sending each message will be reduced, and the compression effect will be better)
-
Slightly increase latency
-
-
batch.size
The maximum size of each batch. Default is 16 KiB.
When set to 0 (equivalent to setting it to 1), batching is disabled, meaning each batch contains only one message.
If an individual message exceeds the batch.size setting, it will be sent as a single batch.
Increasing this configuration will:
-
Increase throughput
-
Waste more memory (each time a new batch is created, a chunk of memory the size of batch.size is allocated).
-
-
max.in.flight.requests.per.connection
The maximum number of batches a producer can send to each broker before receiving a response. Default is 5.
-
max.request.size
The maximum total size of messages per request, which is also the maximum size for an individual message, defaults to 1 MiB.
Note that the broker configuration
message.max.bytesand the topic configurationmax.message.bytesalso impose limits on the maximum size of a single message.
The Kafka Producer defines a series of timeout-related configurations to control the maximum allowed duration for each stage of sending messages. These are illustrated in the figure below:
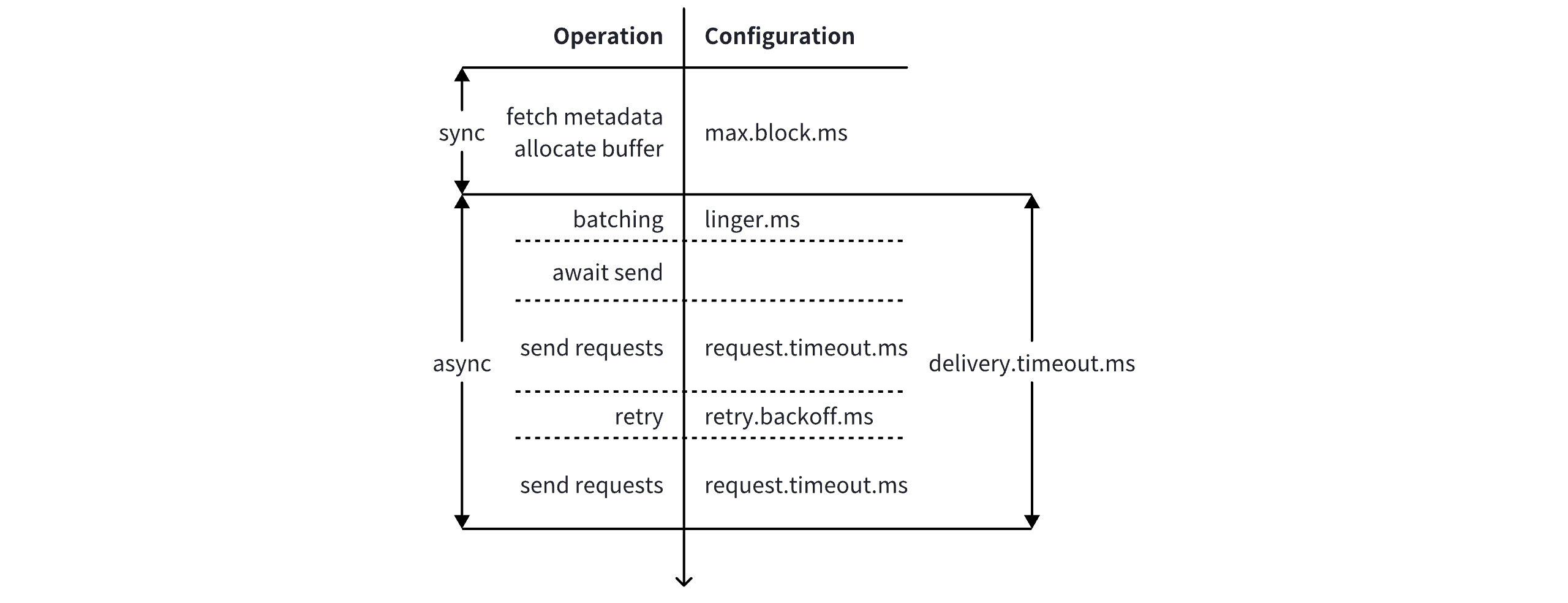
Specifically, the relevant configurations include:
-
buffer.memory: The maximum size of the producer buffer. Default is 32 MiB. When the buffer is exhausted, the producer will block for up to max.block.ms before throwing an error.
-
max.block.ms: The maximum time a call to the
sendmethod will block the current thread. The default is 60 seconds. This duration includes:-
The time taken to fetch metadata
-
The time spent waiting when the producer buffer is full
-
It does not include:
-
Serialization time of messages
-
Time taken by the Partitioner to select partitions
-
request.timeout.ms: The maximum time to wait for a response after sending a request. Default is 30 seconds.
-
delivery.timeout.ms: The maximum time for asynchronous message delivery, from the moment the
sendmethod returns to the invocation of theCallback.Default is 120 seconds. This includes:-
Time spent batching within the producer
-
Time to send the request to the broker and wait for the response
-
Time for each retry
Its value should be no less than linger.ms + request.timeout.ms.
-
-
retries: The maximum number of retry attempts. Default is
Integer.MAX_VALUE. -
retry.backoff.ms and retry.backoff.max.ms: These parameters together control the exponential backoff strategy for retrying failed sends. The backoff time starts at retry.backoff.ms and doubles with each attempt, adding a 20% jitter, up to a maximum of retry.backoff.max.ms. The default values are 100 ms and 1000 ms, respectively.
Our project AutoMQ[1] is dedicated to building the next-generation cloud-native Kafka system, addressing the cost and elasticity issues of traditional Kafka. As committed supporters and participants in the Kafka ecosystem, we will continue to bring high-quality Kafka technical content to Kafka enthusiasts. In the previous article, we introduced the usage methods and basic implementation principles of Kafka Producer; in the next article, we will delve into more implementation details and common issues encountered when using Kafka Producer. Stay tuned for more updates.
[1] AutoMQ: /~https://github.com/AutoMQ/automq
[2] Kafka 3.7: /~https://github.com/apache/kafka/releases/tag/3.7.0
[3] KIP-794: https://cwiki.apache.org/confluence/display/KAFKA/KIP-794%3A+Strictly+Uniform+Sticky+Partitioner