AutoMQ: Next Gen Kafka with 1GB_s Cold Read, Elastic Cloud Streaming
Catch-up Read (cold read) is a common and critical scenario in messaging and streaming systems.
-
Peak Shaving and Valley Filling: Messages are typically used to decouple services and achieve peak shaving and valley filling. This process requires the message queue to buffer the data sent from upstream, allowing downstream systems to consume within their capacity. During this period, the data that downstream systems catch up on will be cold data not stored in memory.
-
Batch Processing Scenarios: For streams, periodic batch processing tasks need to start scanning and computing data from several hours or even a day ago.
-
Fault Recovery: If a consumer goes down and comes back online after several hours, or if there’s a consumer logic issue that needs fixing, the consumer will have to consume historical data retrospectively.
Catch-up Reading mainly focuses on two aspects:
-
- Catch-up Reading Speed: The faster the catch-up reading speed, the faster the business can recover from failures, reducing the impact time of the failure. Batch processing tasks can produce analysis results, reports, and decisions more quickly.
-
Isolation of Reads and Writes: Catch-up reads should minimally impact the rate and latency of message sends.
Apache Kafka® has long been favored by developers and users for its remarkable throughput capabilities. Building on this foundation, AutoMQ guarantees 100% compatibility with Apache Kafka® while providing unparalleled elasticity and cost-reduction capabilities. It not only achieves superior throughput compared to Kafka but also addresses the degradation in write throughput performance during cold reads. In this article, we will explain how AutoMQ achieves extreme throughput of 1GB/s for single-node catch-up reads across 1K partitions concurrently and avoids performance degradation of sending traffic during catch-up reads.
AutoMQ has designed a BlockCache layer, inspired by the Linux PageCache, to cater to the sequential and continuous read characteristics of streaming data. The BlockCache abstracts the details of interactions with object storage from the upper layers. Upper layers need only issue read requests for specific offsets; BlockCache will handle request merging, data prefetching, data caching, and cache eviction to optimize catch-up read throughput, cache utilization, and API invocation costs.
So why is it called BlockCache instead of PageCache or RecordCache?
To answer this question, we first need to introduce the storage format of an object in AutoMQ on object storage. An object consists of three main parts:
-
Data Block: Stores a segment of Records data for a Stream. An object can contain Data Blocks from multiple different Streams.
-
Index Block: Stores the indexing information of the Data Block {streamId, startOffset, endOffset, recordCount, blockPosition, blockSize}. When reading data from an object, the process first performs a binary search on the Index Block to locate the corresponding Data Block index, and then executes the actual data block read.
-
Footer: Stores the format version and the Index Block position, among other information.
<beginning>
[data block 1]
[data block 2]
...
[data block N]
[index block]
[Footer]
<end>
AutoMQ reads and caches data from object storage using Data Blocks as the smallest unit. The cache for catch-up reads is referred to as BlockCache.
The BlockCache architecture consists of four main components:
-
- KRaft Metadata: This stores the relationship between the offset segment of the stream and the objects.
-
- StreamReader: This is a read window; each consumer consuming each partition will have its own independent read window. This window primarily maintains the index information of Data Blocks that have not yet been read and triggers pre-reading acceleration at appropriate times.
-
- DataBlockCache: This is the Data Block data cache. It caches data blocks read from object storage using off-heap memory and adopts the focus and LRU (Least Recently Used) mechanism for cache management.
-
ObjectStorage: The API abstraction layer of Object Storage eliminates the differences among various cloud object storage services and provides accelerated read and merge capabilities.
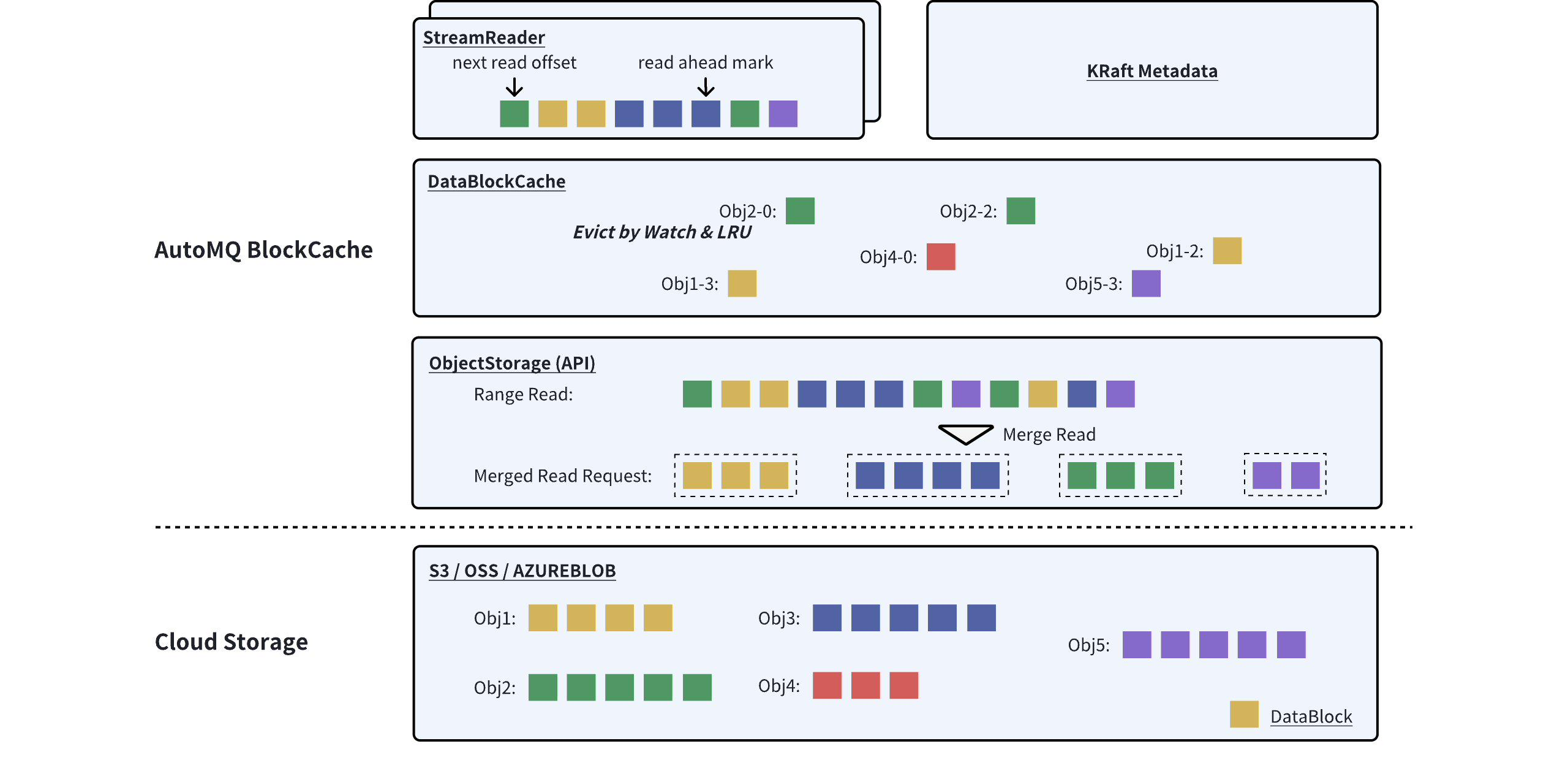
The interaction flow for a catch-up read initiated by BlockCache is briefly described as follows:
-
Firstly, based on the {streamId, startOffset}, locate the StreamReader;
-
Then, the StreamReader requests the metadata of the object responsible for the {startOffset, endOffset} from KRaft Metadata;
-
Based on the object metadata, the StreamReader reads the object's IndexBlock and performs a binary search to find the corresponding DataBlock index (if index information is already present in memory, steps 2 and 3 are skipped).
-
StreamReader requests a DataBlock from the DataBlockCache;
-
DataBlockCache sends a #rangeRead request to the ObjectStorage (if already cached, it returns directly);
-
ObjectStorage reads the corresponding data segment and returns it to the upper layer.
With the basic concepts and process introduction completed, let's analyze "how AutoMQ achieves single-machine 1K partition concurrent tail-read throughput of up to 1GB/s."
The key to AutoMQ achieving concurrent tail reads on 1K partitions within a single machine lies in controlling the cache space occupied by each Stream's reads. This prevents the total cache demands from exceeding the cache space limit, thereby avoiding the issue where caches from different Streams evict each other, resulting in wasted network bandwidth and API costs due to reads from object storage.
AutoMQ can limit the cache space occupied by each Stream's reads to under 2MB, meaning that only 2GB of BlockCache is needed to support concurrent tail reads on 1K partitions.
Previously, it was mentioned that the smallest cache granularity for BlockCache is the DataBlock of an object. The default size of a DataBlock is 512KB (a soft limit), so the cache space occupied by Stream reads is 512KB * N (the number of cached DataBlocks). Therefore, reducing the cache space occupation involves minimizing the value of N, which is mainly determined by the cache eviction policy.
Typically, general-purpose caches use the Least Recently Used (LRU) policy for cache eviction. However, practical tests have shown that this policy is not particularly suitable for sequential read stream scenarios, still resulting in a significant number of unnecessary evictions. For example, suppose there are two partitions with concurrent tail reads, and their read rates are 10MB/s and 1MB/s respectively. The DataBlocks in the 1MB/s partition are accessed and updated less frequently than those in the 10MB/s partition. Consequently, due to LRU, the DataBlocks in the 1MB/s partition might be evicted by the newly loaded DataBlocks from the 10MB/s partition before they are fully read.
To address this issue, AutoMQ has introduced a watch-based eviction policy on top of LRU. Within the read window (StreamReader), DataBlocks that are being read or are about to be read are marked with a +1 watch count. Once the read window completes reading a DataBlock, the watch count for that DataBlock is decremented by 1. BlockCache will prioritize the watch-based eviction policy; when a DataBlock’s watch count drops to 0, it will be immediately evicted from the cache, even if there is still cache space available.
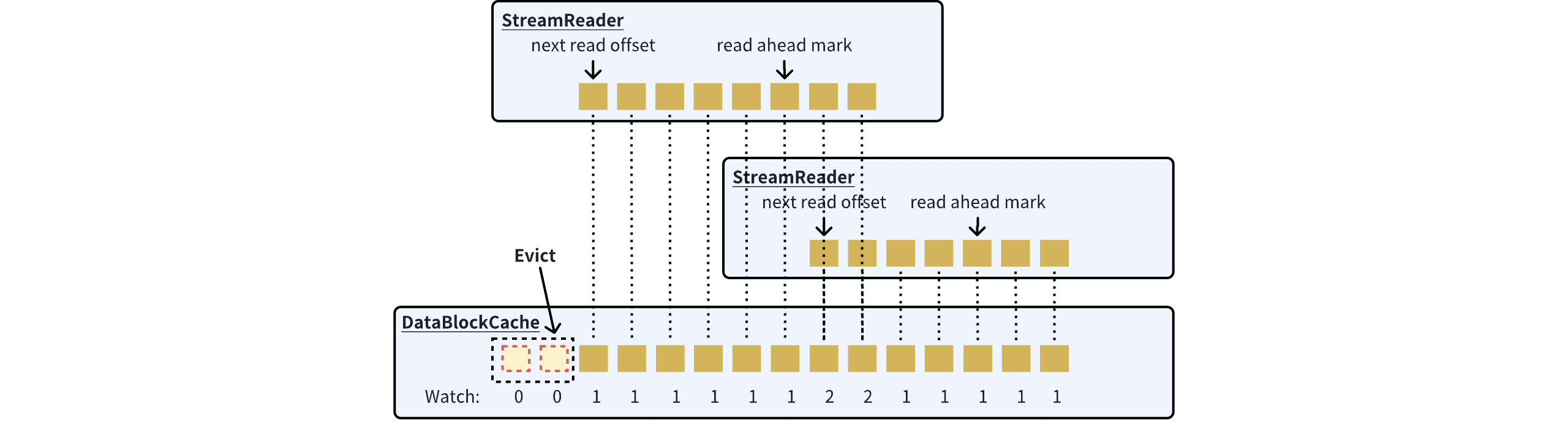
Through the focus-driven eviction strategy, without considering prefetch scenarios, each read window of the Stream can occupy up to 1.5MB (512KB * 3). This is because the default `max.partition.fetch.bytes` for Kafka is 1MB, and if the read cursor is in the middle of a DataBlock, it can read up to 3 DataBlocks. Similarly, in scenarios with 2 partitions having concurrent reads at 10MB/s and 1MB/s, AutoMQ's tail read cache usage will stabilize at 4MB, with the 2 read windows being isolated from each other, preventing any mutual cache eviction.
The concurrent reading capability of partitions determines how many applications Kafka can support concurrently reading. The read throughput impacts the efficiency of business decisions. AutoMQ provides a single-machine tail read throughput of 1GB/s, primarily determined by two factors: object storage and prefetching.
Object storage: Although object storage operations typically take hundreds of milliseconds, as long as sufficient concurrency is provided by the client side, it can easily offer GB/s read/write throughput even without any read/write optimization, thanks to the massive resource pool at the backend of object storage. For example, with S3, assuming a 4MB read takes 100ms, achieving a 1GB/s read speed would only require 25 concurrent reads.
Prefetching: Kafka's tail-read consumption can be viewed as a loop of reading data -> processing data -> reading data. Directly transmitting requests to object storage results in high latency, which prevents sufficient utilization of read concurrency, ultimately leading to suboptimal read throughput. Therefore, AutoMQ reduces the latency of handling tail read fetch requests through cached prefetching, ensuring that subsequent tail read requests are primarily covered by the prefetch window, thereby enhancing read throughput.
Attentive readers might wonder: Does AutoMQ's prefetching strategy lead to excessive Stream read window usage, resulting in the mutual eviction of 10MB and 1MB concurrent reads?
To prevent such scenarios, AutoMQ adopts the following prefetching strategy:
-
The initial prefetch size is set to 512KB. The prefetch window size will only increase when a Cache Miss occurs during the upper-level read within the reading window. If a Cache Miss does not occur, it indicates that the current prefetch speed can meet the demands of read catch-up.
-
The prefetch window within the read window will not exceed a maximum size of 32MB.
-
Prefetching is only initiated when there is available space in the BlockCache, which avoids unnecessary prefetching that would lead to false evictions under memory pressure.
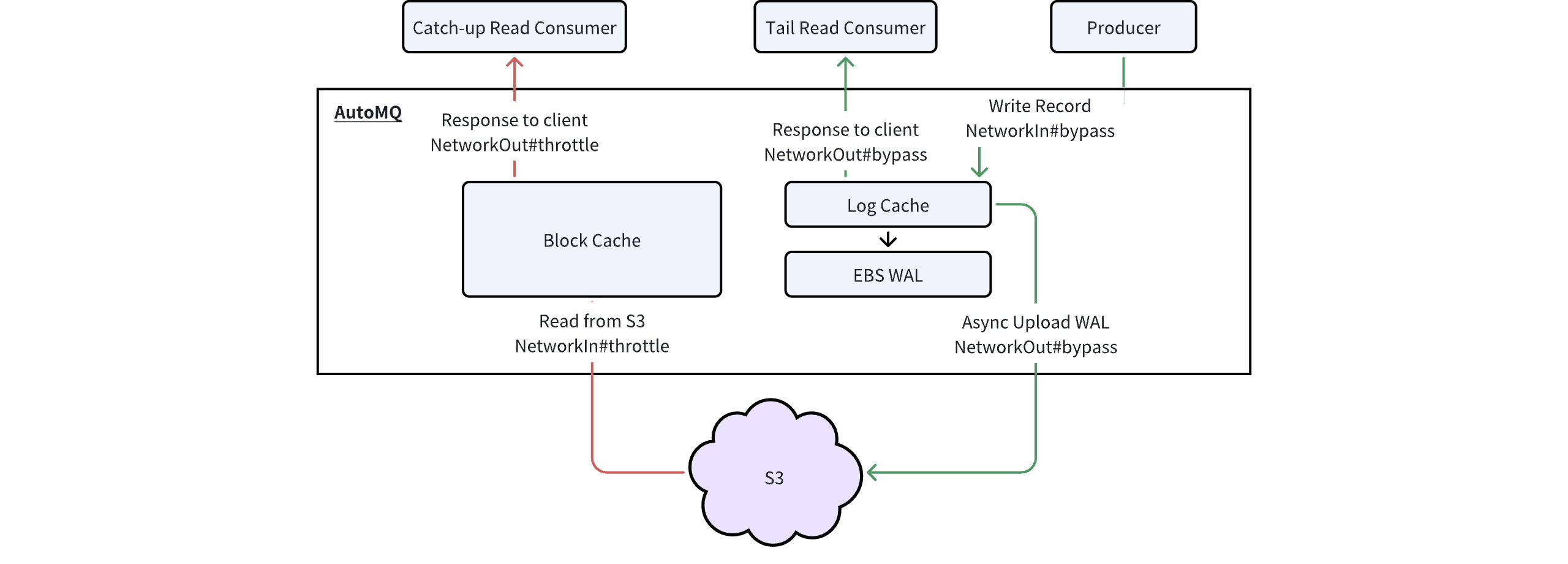
AutoMQ ensures that sending traffic is not affected by read operations while also supporting high concurrency and high throughput for tailing reads. As illustrated below, the read-write isolation in AutoMQ is guaranteed by two main aspects:
-
- Read-Write Path Isolation : In the write path, messages sent by the Producer are stored to the EBS Write-Ahead Log (WAL) and then acknowledged back to the client as successful. In the tailing read path, data for tailing reads comes from S3, avoiding competition for disk bandwidth and IOPS on the EBS WAL.
-
- Network Prioritization and Rate Limiting : AutoMQ can set overall network ingress and egress limits, with Producer traffic given higher priority than tailing read Consumer traffic. This ensures that tailing read traffic does not saturate the network bandwidth and impact sending operations.
-
Server: Alibaba Cloud ecs.g8i.4xlarge, 16C64G, data disk PL1 300GB
-
Load Generator: Alibaba Cloud ecs.g8i.4xlarge, 16C64G
AutoMQ Startup Command: Heap memory 32G, off-heap memory 24G, BlockCache 14G, bandwidth limit 2GB/s.
# AutoMQ Version >= 1.2
KAFKA_S3_ACCESS_KEY=xxxx KAFKA_S3_SECRET_KEY=xxxx KAFKA_HEAP_OPTS="-Xmx32g -Xms32g -XX:MaxDirectMemorySize=24G" ./bin/kafka-server-start.sh -daemon config/kraft/server.properties \
--override node.id=0 \
--override cluster.id=M_automq-catchup_____w \
--override controller.quorum.voters=0@${ip}:9093 \
--override advertised.listener=${ip}:9092 \
--override s3.data.buckets='0@s3://xxx_bucket?region=oss-cn-hangzhou&endpoint=https://oss-cn-hangzhou-internal.aliyuncs.com' \
--override s3.wal.path='0@file:///dev/nvme1n1?capacity=21474836480&iodepth=32&iops=4000' \
--override s3.telemetry.metrics.exporter.uri='otlp://?endpoint=http://xxxx&protocol=grpc' \
--override s3.stream.allocator.policy=POOLED_DIRECT \
--override s3.wal.cache.size=6442450944 \
--override s3.wal.upload.threshold=1572864000 \
--override s3.block.cache.size=12884901888 \
--override s3.network.baseline.bandwidth=2147483648 \
--override s3.stream.object.split.size=1048576
Load Testing Script:Create 50 Topics, each with 20 partitions, totaling 1000 partitions. Continuously write at 200MB/s for 2 hours, then start consuming from the beginning while maintaining the 200MB/s write throughput.
KAFKA_HEAP_OPTS="-Xmx32g -Xms32g" nohup ./bin/automq-perf-test.sh --bootstrap-server ${bootstrapServer}:9092 \
--producer-configs batch.size=0 \
--consumer-configs fetch.max.wait.ms=1000 \
--topics 50 \
--partitions-per-topic 20 \
--producers-per-topic 2 \
--groups-per-topic 1 \
--consumers-per-group 4 \
--record-size 65536 \
--send-rate 3200 \
--backlog-duration 7200 \
--group-start-delay 0 \
--warmup-duration 1 \
--reset &
-
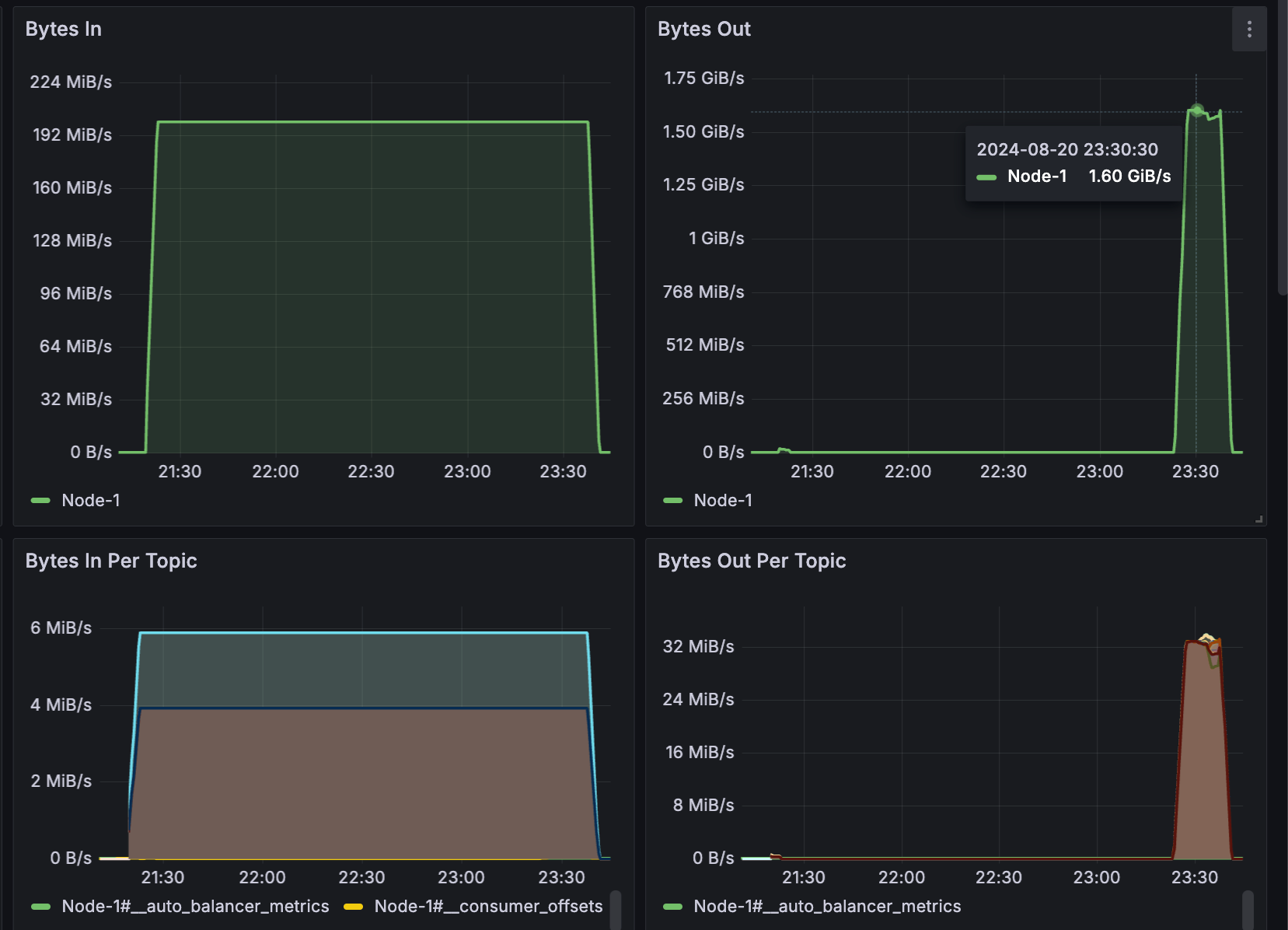
A total of 1.37 TB of data was produced in 2 hours across 1000 partitions.
-
The peak catch-up consumption rate was 1.6 GB/s, with each Topic maintaining a consumption rate of 32 MB/s. It took a total of 18 minutes to consume 1.37 TB of backlog data.
-
During the catch-up period, the sending throughput remained stable at 200 MB/s, the P99 latency for sending increased from 5 ms to 10 ms, while the average latency remained below 2 ms.
[1] AutoMQ: https://www.automq.com
[2] AutoMQ vs. Apache Kafka Benchmark: https://docs.automq.com/automq/benchmarks/benchmark-automq-vs-apache-kafka#catch-up-read