Introducing AutoMQ: a cloud native replacement of Apache Kafka
In the world of data, the need for efficient, reliable, and scalable data streaming services is more crucial than ever. As the volume, velocity, and variety of data increase, organizations are seeking more advanced solutions to manage and utilize their data effectively. Enter AutoMQ - a cloud-native replacement for Apache Kafka, designed to meet the evolving demands of modern data architectures.
This article aims to provide a comprehensive overview of AutoMQ, its origins, its community, and its role in the transformation of stream storage over the past decade. We'll delve into the details of AutoMQ's cloud-native architecture, its support for multi-cloud environments, and the empirical data that underscores its performance.
Finally, we'll peer into AutoMQ's future, where it plans to transition from the traditional shared-storage model to a more dynamic shared-data approach by integrating stream data into data lakes. This paradigm shift promises to enhance AutoMQ's capabilities, breaking down data silos and enabling comprehensive data access.
Whether you're a data engineer, a developer, or just someone interested in the latest advancements in data streaming technology, this article will provide you with valuable insights into the world of AutoMQ. So, let's embark on this journey of discovery and see what makes AutoMQ a game-changer in the realm of data streaming services.

The story of AutoMQ begins with a team of pioneers in the open-source community and the cloud computing industry. The team is composed of the founding members of two significant open-source projects: Apache RocketMQ and Linux LVS. Coming from China, the team has a deep passion for open-source initiatives and has made substantial contributions to the field.
One of the co-founders, WenSong Zhang, wrote the first line of code for Linux Virtual Server (LVS) 26 years ago. As the original author of LVS, this marked the beginning of his journey of relentless innovation. The other two co-founders, XiaoRui Wang and Xinyu Zhou, are members of the Apache Software Foundation. XiaoRui penned down the first line of code for RocketMQ on GitHub in 2012, and together with Xinyu, they donated the project to the Apache Foundation in 2016.
As early participants in China's open-source movement and witnesses to the growth of the cloud computing industry, the team has unique insights and experiences. XiaoRui, as the former head of messaging middleware at Alibaba Group, supported the company's annual Singles' Day shopping festival for several years using RocketMQ. The creation of RocketMQ was motivated by Kafka's inability to meet the transactional requirements of Taobao, as Kafka's performance significantly decreases under a large number of partitions and frequently causes distributed system avalanches due to tail latency.
With the rapid development of cloud computing in China, messaging middleware began to be listed on Alibaba Cloud in 2014. Our team developed a full range of messaging and streaming products on Alibaba Cloud, including Kafka, RocketMQ, RabbitMQ, MQTT, and EventBridge. These products have been adopted by tens of thousands of enterprise customers and applied in their production environments across a multitude of industries. These industries span from traditional businesses to internet companies, online education, gaming, finance, healthcare, logistics, retail, telecommunications, and more. This extensive journey in enterprise service has inspired the team to establish a startup focusing on the Messaging and Streaming area.
Since its establishment in 2023, AutoMQ has experienced two seed rounds of financing, raising nearly $10 million, and has successfully brought on board four strategic investors. GSR Ventures and Vision Plus Capital were the pioneering investors who saw potential in AutoMQ during our first round of financing. We are particularly grateful for the support from Vision Plus Capital, whose chairman, Eddie Wu, is the incumbent CEO of Alibaba Group. His belief in our mission and vision has been a strong testament to our capabilities and potential. We deeply appreciate Eddie Wu's support and continue to strive to make our investors proud.
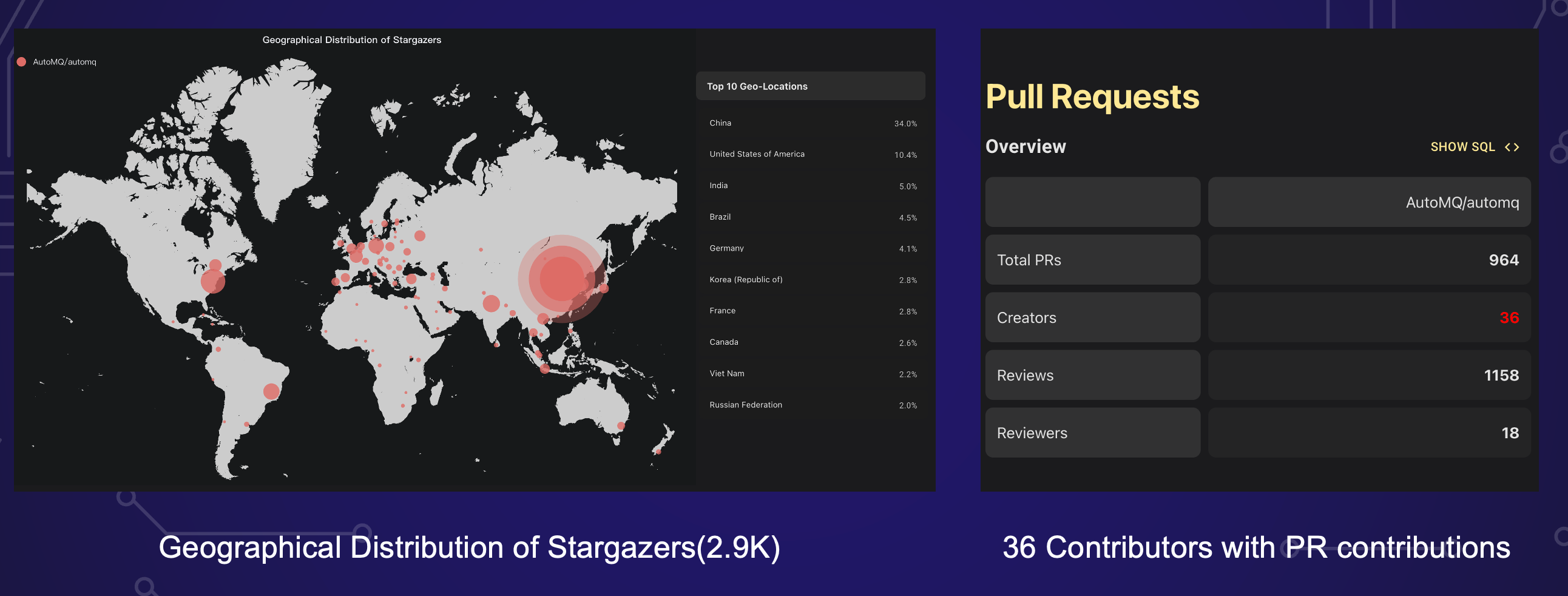
The AutoMQ community is a vibrant and diverse group of individuals and organizations committed to the growth and development of AutoMQ. As a source-available software on GitHub, AutoMQ has amassed an impressive following. With 2900+ stargazers and counting, the community's enthusiasm for our project is palpable. What's even more exciting is the international reach of our community, with over 65% of our stargazers hailing from outside China.
The AutoMQ community is continually growing and evolving, with 36 contributors and counting. While the top contributors are from AutoMQ, we're thrilled to see participation from a variety of other companies. A notable example is Zhihu, often likened to the Chinese version of Quora. Their active involvement underscores the diverse range of contributors we're attracting.
Our community's diversity and engagement are testaments to the broad appeal and applicability of AutoMQ. We're excited to continue fostering this dynamic community, driving innovation, and shaping the future of "Data in Motion" together.
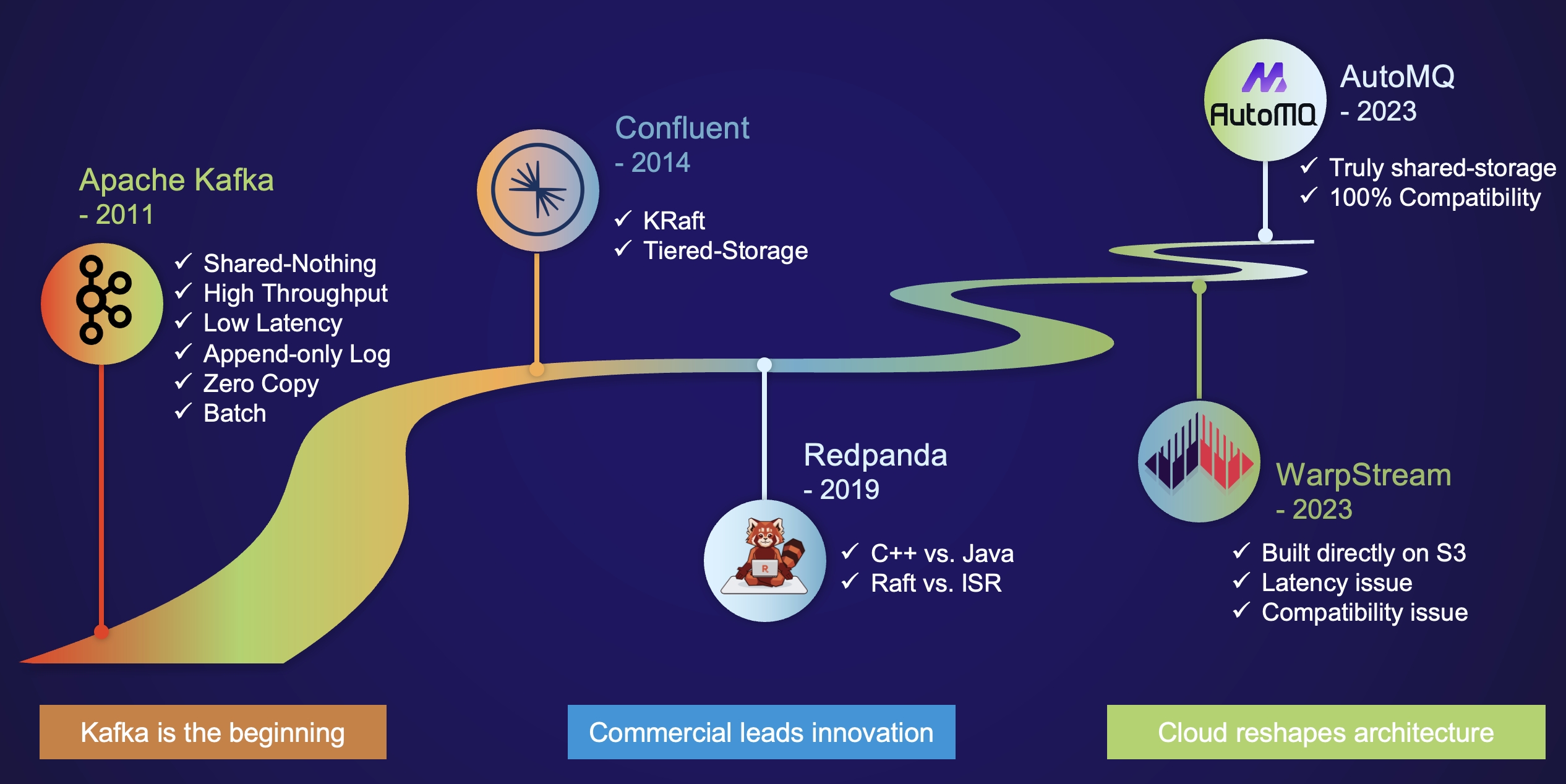
The stream storage industry has undergone a significant transformation over the past decade, marked by technical evolution and the emergence of innovative solutions.
Apache Kafka, birthed a decade ago, marked the beginning of a new era in stream storage. Its open-source availability, exceptional performance, and shard architecture led to a significant industry shift.
Kafka integrated advanced technologies of its era, such as the append-only log and zero-copy technique, which dramatically enhanced data writing efficiency and throughput. Its end-to-end batch processing further improved data transmission and minimized data loss, providing Kafka with a performance edge over its peers.
These technological breakthroughs, combined with Kafka's solution to scalability issues, led to its widespread adoption. Despite its age, Kafka remains the de facto standard for stream storage, testament to its enduring impact and relevance.
As the industry matured, commercial opportunities began to surface. Companies like Confluent and Redpanda emerged, driving technical innovations in the Kafka ecosystem. Confluent introduced significant architectural innovations, namely KRaft and Tiered Storage, which streamlined the architecture and substantially reduced storage costs. However, these innovations did not fully address Kafka's challenges, as the first level of storage still relied on ISR replication, resulting in issues like difficult partition reassignments, high IaaS costs, and limited scalability.
Redpanda took a different approach, rewriting Kafka in the native language CPP and replacing the ISR with the Raft replication protocol. This led to performance improvements, and by avoiding the Java garbage collector, Redpanda achieved lower tail latency than Confluent. However, both Redpanda and Confluent are based on a Shared-Nothing replication architecture and have adopted tiered storage optimization, so it's unlikely that Redpanda would hold a significant cost advantage over Confluent in terms of technical architecture.
The advent of cloud-native technologies has further reshaped the stream storage industry. Over the past two years, two companies, WarpStream and AutoMQ, have made their mark by successfully implementing cloud-native Kafka, claiming an impressive tenfold reduction in cost.
WarpStream has drawn attention with its innovative approach of constructing Kafka directly on S3, leading to a streamlined architecture. However, this comes with a trade-off of increased latency, with P99 latency exceeding 600ms. This significant latency increase necessitates client-side adjustments to parameters, memory allocation strategy, and concurrency, posing a hurdle for migration from Apache Kafka. Furthermore, this latency issue challenges real-time processing requirements in scenarios like recommendations and risk control.
Compatibility is another concern with WarpStream. Kafka, composed of a million lines of code, presents a significant challenge for a complete rewrite and full compatibility. Despite WarpStream's substantial efforts, it has only managed to implement 26 out of the 74 Kafka APIs so far. While these APIs cover the core data link, they lack in Admin and transactional APIs, which are crucial for Exactly Once Semantics (EOS). The absence of these APIs could potentially affect certain operations and compromise the guarantees of data consistency.
Lastly, WarpStream may struggle to keep up with the pace of adopting new features from the Apache Kafka upstream community, such as KIP-932: Queues for Kafka.
AutoMQ, on the other hand, also stores data entirely on S3, but we've adopted a different architecture. By decoupling storage and computation, we offload storage to EBS and S3, maintaining full Kafka compatibility without compromising on latency. This approach allows us to leverage the benefits of cloud-native technologies while addressing the challenges posed by other solutions in the market.
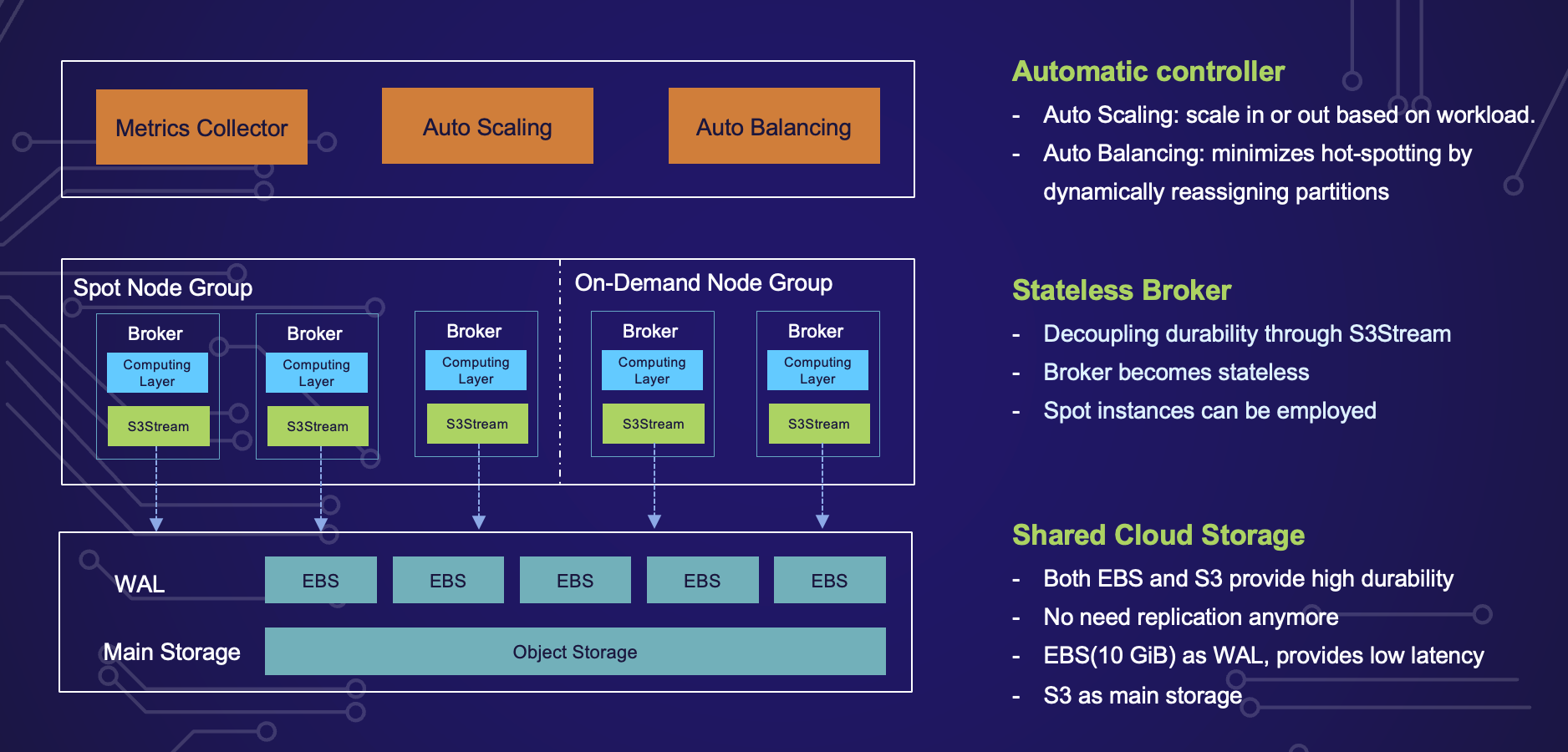
The cloud-native architecture of AutoMQ is a result of careful design decisions, innovative approaches, and the strategic use of cloud storage technologies. We aimed to create a system that could leverage the benefits of the cloud while overcoming the limitations of traditional stream storage solutions.
The first step in realizing the cloud-native architecture of AutoMQ was to decouple durability to cloud storage. Unlike the typical decoupling of storage, where we refer to separating the storage to a distributed and replicated storage software, decoupling durability takes it a step further. In the former case, we are left with two types of clusters that need to be managed, as seen in Apache Pulsar, where you need to manage both the broker cluster and the bookkeeper cluster.
However, AutoMQ has taken a different route, opting to decouple durability to cloud storage, with S3 serving as the epitome. S3 already offers a durability rate of 99.999999999%, making it a reliable choice for this purpose. In the realm of cloud computing, merely decoupling storage is insufficient; we must also decouple durability to cloud storage.
The essence of the Decoupling Durability architecture lies in its reliance on cloud storage for durability, eliminating the need for replication protocols such as Raft. This approach is gaining traction over the traditional Decoupling Storage architecture. Guided by this philosophy, we developed S3Stream, a stream storage library that combines the advantages of EBS and S3.
With S3Stream in place, we replaced the storage layer of the Apache Kafka broker, transforming it from a Shared-Nothing architecture to a Shared-Storage architecture, and in the process, making the Broker stateless. This is a significant shift, as it reduces the complexity of managing the system. In the AutoMQ architecture, the Broker is the only component. Once it becomes stateless, we can even deploy it using cost-effective Spot instances, further enhancing the cost-efficiency of the system.
The final step in realizing the cloud-native architecture of AutoMQ was to automate everything to achieve an elastic architecture. Once AutoMQ became stateless, it was straightforward to automate various aspects, such as auto-scaling and auto-balancing of traffic.
We have two automated controllers that collect key metrics from the cluster. The auto-scaling controller monitors the load of the cluster and decides whether to scale in or scale out the cluster. The auto-balancing controller minimizes hot-spotting by dynamically reassigning partitions across the entire cluster. This level of automation is integral to the flexibility and scalability of AutoMQ, and it is also the inspiration behind its name.
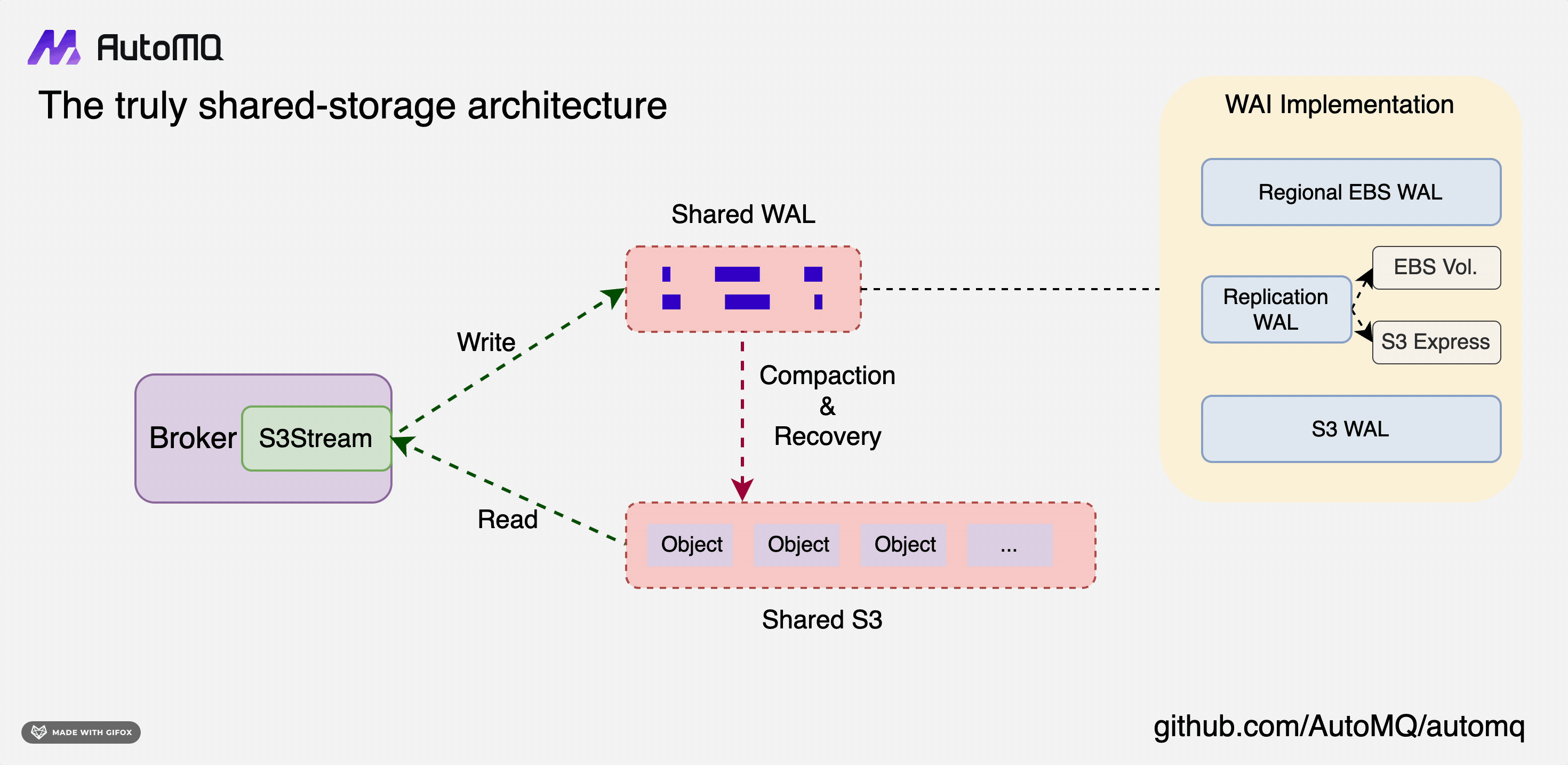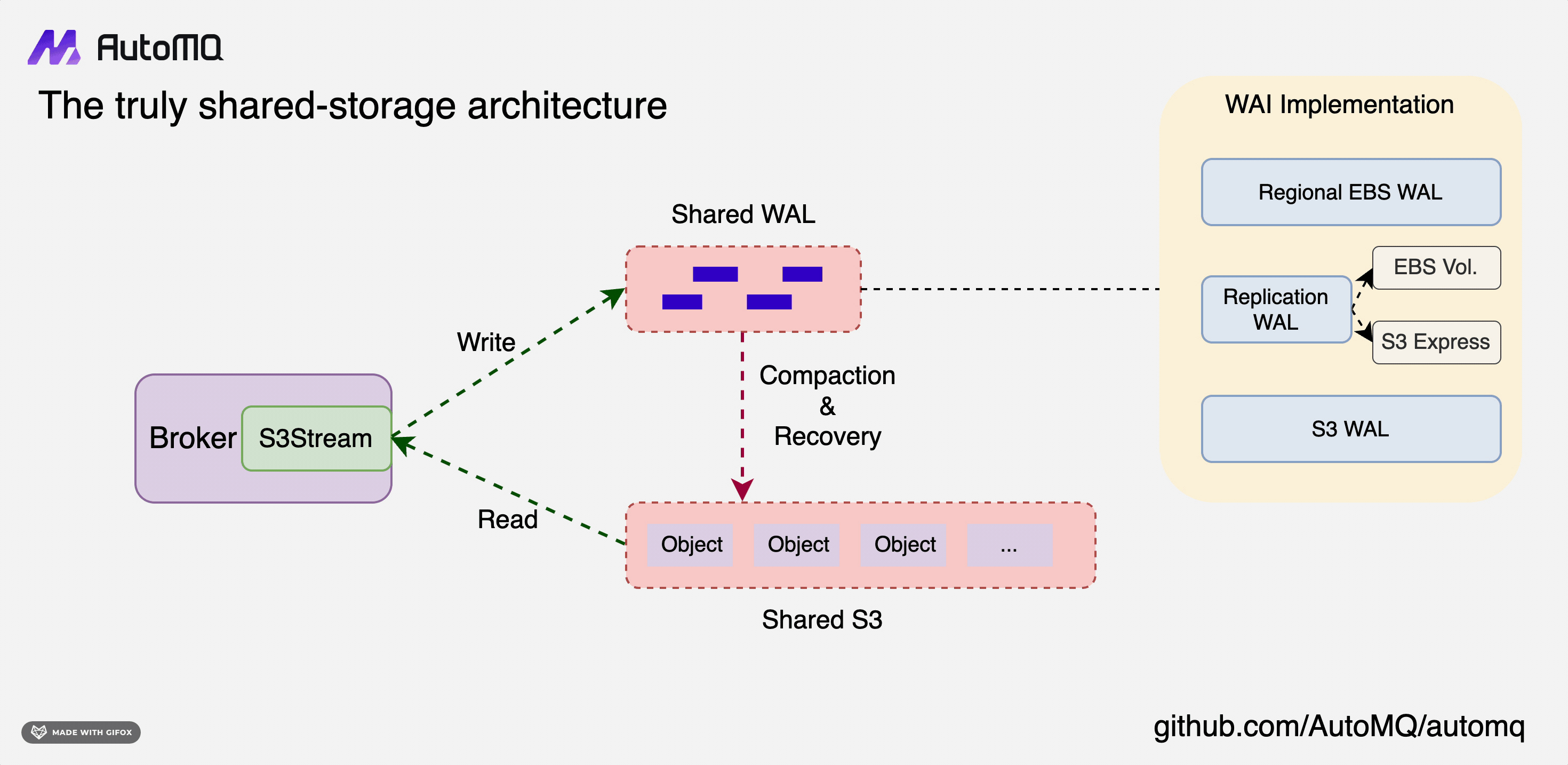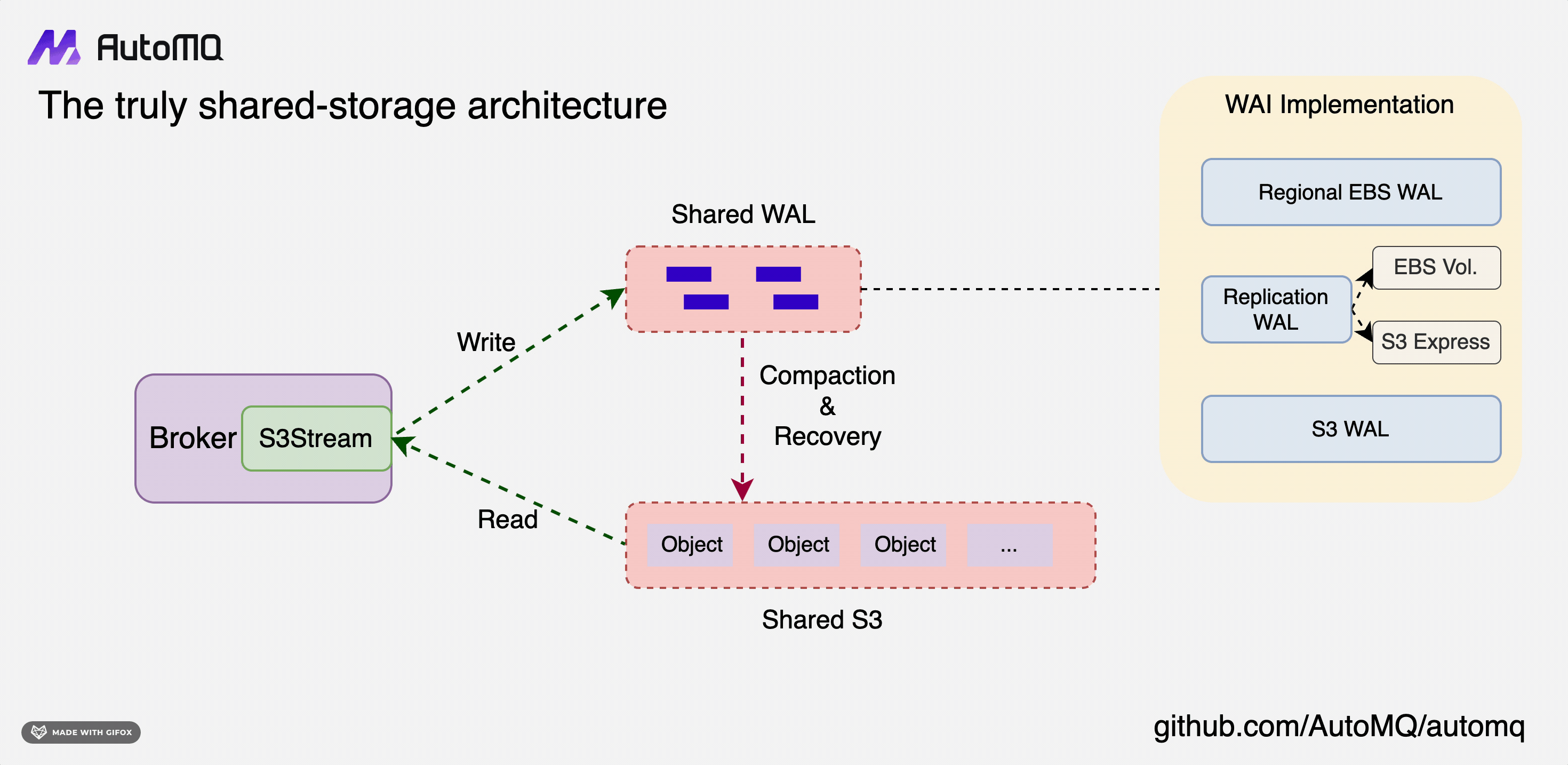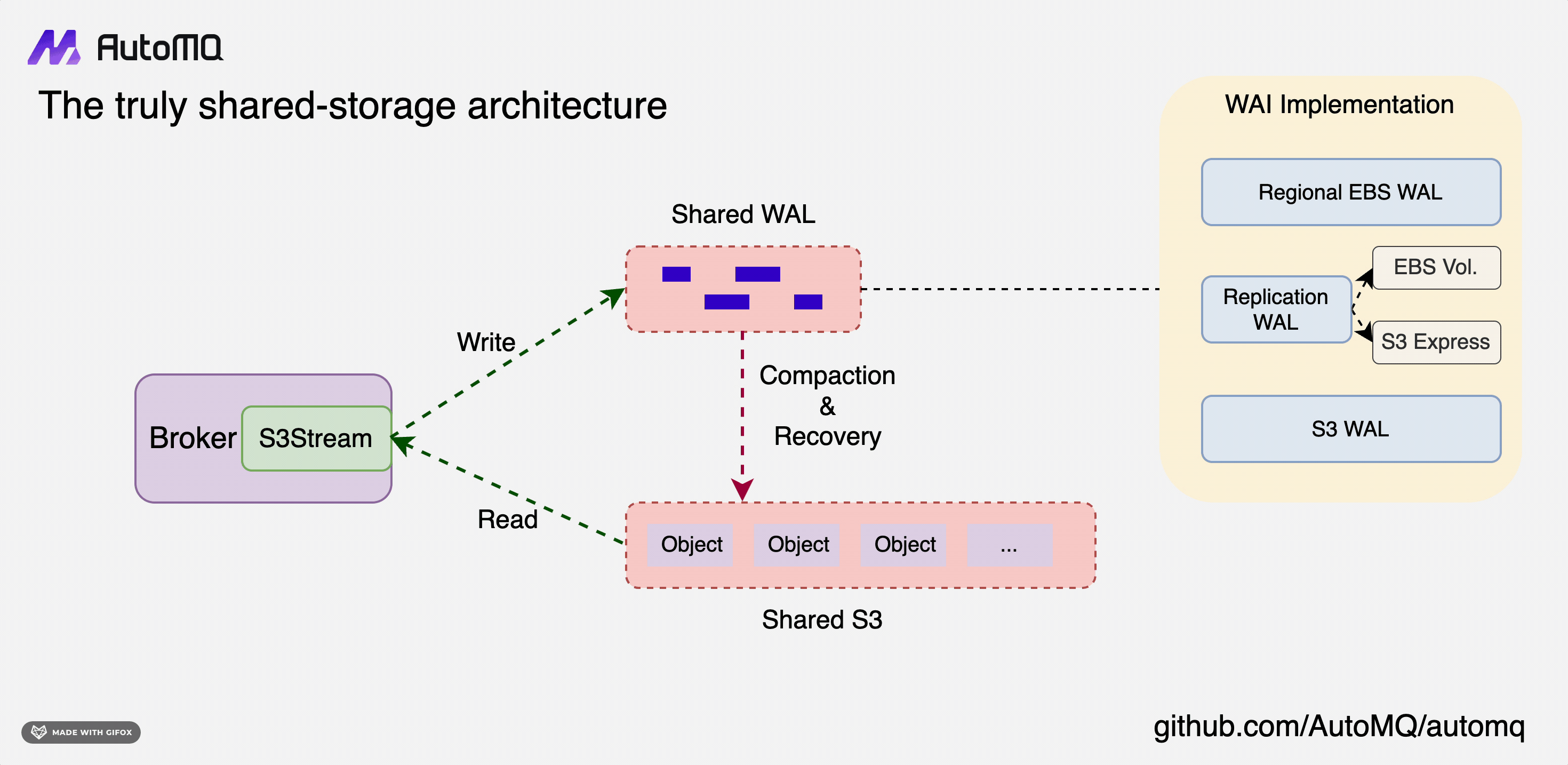
As we move toward a multi-cloud native architecture, the need for a flexible and adaptable storage solution becomes critical. AutoMQ's shared storage design is an embodiment of this flexibility, designed to integrate seamlessly with a variety of cloud providers.
At the heart of this design lies the concept of S3Stream, a shared stream storage repository. It is essentially composed of a shared Write-Ahead Log (WAL) and shared object storage.
Data is first persistently written to the WAL and then uploaded to object storage in near real-time. The WAL does not provide data reading capabilities. Instead, it serves as a recovery mechanism in the event of a failure. Consumers read data directly from S3. To enhance performance, a memory cache is implemented for acceleration, which means that tailing-read consumers do not need to access object storage directly.
This architecture of S3Stream is highly flexible due to the variety of mediums that can be used for the WAL. For instance, EBS, Regional EBS, S3, or even a combination of these can be used to form a Replication WAL. This flexibility is primarily due to the varying capabilities of cloud storage offered by different cloud providers. The aim is to pursue an architecture that is optimal across multiple cloud providers.
The architecture of AutoMQ's shared storage model is designed to be adaptable to the specific capabilities of different cloud providers. The choice of architecture depends primarily on the specific features and services offered by each cloud provider.
For instance, Azure, Google Cloud, and Alibaba Cloud all provide regional EBS. Given this feature, the best practice for these cloud providers is to use regional EBS as the WAL. This allows the system to tolerate zone failures, ensuring reliable and consistent performance.
In contrast, AWS does not offer regional EBS. However, AWS does provide S3 Express One Zone, which boasts single-digit millisecond latency. Although this service is limited to a single availability zone, AutoMQ can still ensure tolerance to zone failures by using a replication WAL. In this setup, data is written both to the S3 One Zone bucket and an EBS volume.
In cases where you have access to a low-latency alternative to S3 or your business can tolerate hundreds of milliseconds of latency, it is possible to use S3 as the WAL. This means the entire architecture relies solely on S3 for both WAL and data storage. Yes, AutoMQ also provides a warpstream-like architecture easily.
By understanding and leveraging the unique features of each cloud provider, AutoMQ ensures optimal performance and reliability across a variety of cloud environments. This flexibility and adaptability are key to the success of a multi-cloud native architecture.
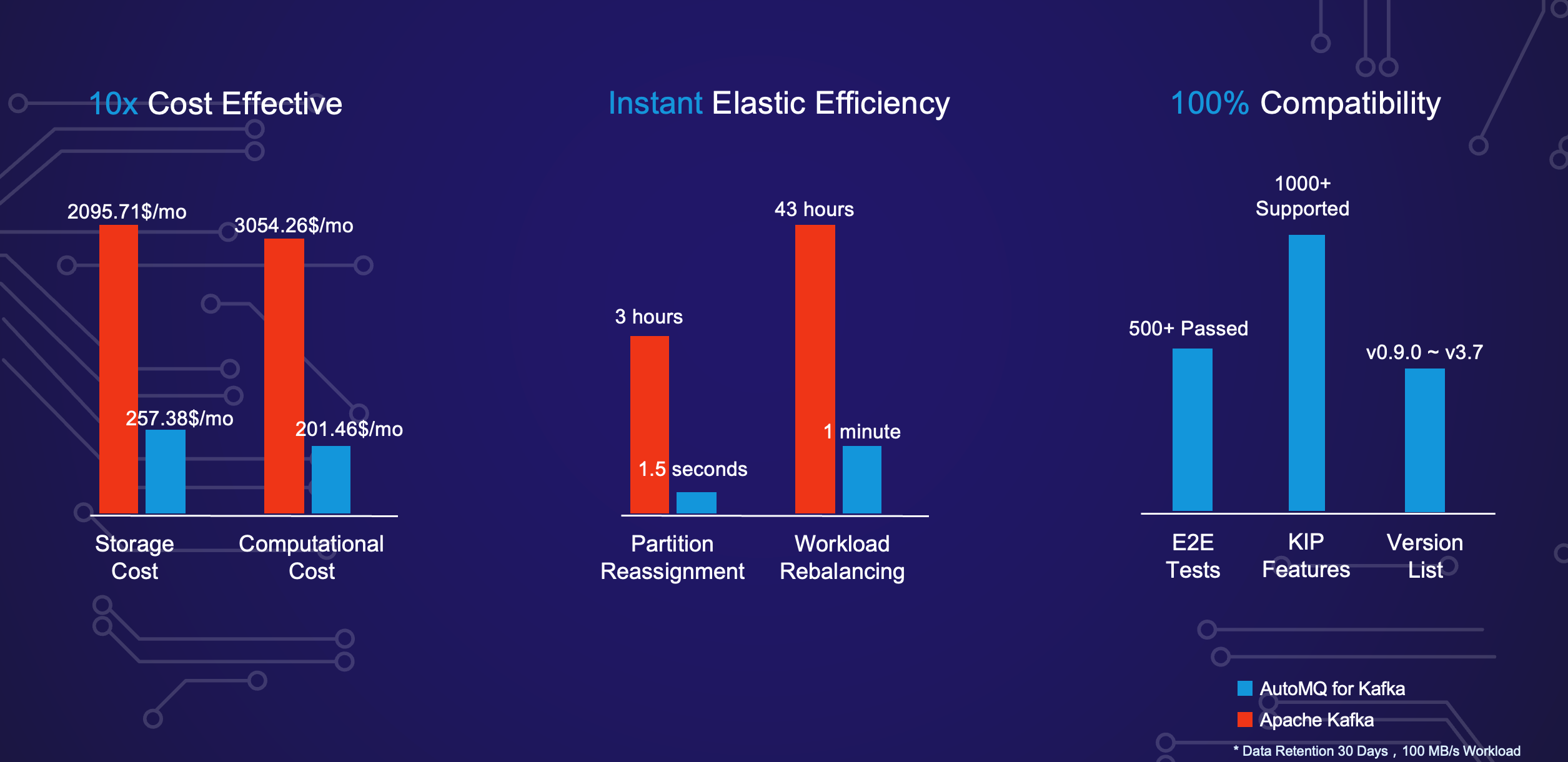
To fully appreciate the capabilities and advantages of AutoMQ, let's take a look at some key benchmark data and performance metrics.
AutoMQ's innovative architecture brings unprecedented cost savings in the realm of data-intensive software. Its design focuses on optimizing both computational and storage resources, resulting in a cost advantage that's nearly tenfold compared to traditional solutions.
The first major advantage comes from the optimization of EC2 resources. By eliminating data replication, AutoMQ removes the need for extra resources to manage replication traffic. And, coupled with the platform's elastic nature that dynamically adjusts the cluster size in response to workload, results in a dramatic reduction of EC2 resources—up to 90%.
Furthermore, AutoMQ's stateless architecture allows the use of Spot instances. This strategy leads to a significant cost reduction, further enhancing computational resource savings.
On the storage front, AutoMQ also shines. Instead of adhering to the traditional three-replication EBS storage, it utilizes a single-replica object storage model. This innovative approach reduces storage costs by as much as 90%.
Our detailed cost comparison chart, based on real bill comparisons from stress testing on AWS, illustrates these savings. For more in-depth information, we invite you to access the complete report from our website.
AutoMQ's shared storage architecture greatly enhances operational efficiency. For example, reassigning partitions in AutoMQ no longer involves data replication and can be completed within seconds, unlike in Kafka where it could take up to several hours. Additionally, when it comes to cluster scaling, AutoMQ can balance the traffic of new nodes with the cluster in just about one minute by reassigning partitions in batches. In contrast, this process could take days with Kafka.
Perhaps one of the most important aspects of AutoMQ is its compatibility. We've replaced Kafka's storage layer with s3stream while keeping all the code from the computation layer. This ensures that AutoMQ is fully compatible with Kafka's protocols and features. For instance, newer versions of Apache Kafka that support features such as Compact Topics, Idempotent Producer, and Transactional Messages are fully supported by AutoMQ.
Furthermore, we replace Kafka's storage layer through a very small LogSegment aspect. This approach makes it very easy for us to synchronize code from the Kafka upstream, meaning that we can easily merge new features of Apache Kafka in the future. This is a significant advantage over solutions like WarpStream, where such compatibility and future-proofing can be a challenge.
In summary, AutoMQ's flexible architecture, cost savings, operational efficiency, and compatibility make it a powerful solution for stream storage in the cloud.

In this final section, we outline our vision for the future of streaming data into data lakes, a critical aspect of our roadmap.
We're witnessing a trend where all data-intensive software eventually stores data on object storage to leverage the benefits of shared storage. However, even with all data stored on object storage, there isn't a straightforward way to share data between different systems. This process typically requires Extract, Transform, Load (ETL) operations and data format conversions.
We believe the transition from shared storage to shared data will be the next critical evolution in modern data technology. Table storage solutions like Delta Lake and Iceberg have unified the data format in the data lake, making this transition feasible.
In the future, we envision data usage to be a seamless, interconnected process that maximizes data utility and operational efficiency.
The journey begins with data generation. As data is produced in a streaming manner, it is immediately stored in stream storage. This continuous flow of information forms the foundation of our data landscape.
Next, we unlock the real-time value of this data. Tools like Flink Jobs, Spark Jobs, or Kafka consumers dive into the data stream, extracting valuable insights on the fly through the Stream API. This step is crucial in keeping pace with the dynamic nature of the data.
As the data matures and loses its freshness, the built-in Compactor in AutoMQ steps in. Quietly and transparently, it transforms the data into the Iceberg table format. This conversion process ensures the data remains accessible and usable even after it has passed its real-time relevance.
Finally, we arrive at the stage of large-scale analysis. The entire big data technology stack can now access the converted data, using a zero ETL approach. This approach eliminates the need for additional data processing, allowing for direct, efficient analysis.
In conclusion, as we continue to innovate and evolve, our goal remains the same: to provide a powerful, efficient, and cost-effective solution for stream storage in the cloud. By streamlining the process of streaming data to data lakes, we aim to further enhance the value and utility of big data for businesses.
AutoMQ, our cloud-native solution, is more than an alternative to existing technologies—it's a leap forward in the realm of data-intensive software. It promises cost savings, operational efficiency, and seamless compatibility.
We envision a future where data effortlessly streams into data lakes, unlocking the potential of real-time generative AI. This approach will enhance the utility of big data, leading to more comprehensive analyses and insights.
Finally, we invite you to join us on this journey and contribute to the evolution of AutoMQ. Visit our website to access the GitHub repository and join our Slack group for communication: https://www.automq.com/. Let's shape the future of data together with AutoMQ.
Here are some useful links to deepen your understanding of AutoMQ. Feel free to reach out if you have any queries.
-
AutoMQ Website: https://www.automq.com/
-
AutoMQ Repository: /~https://github.com/AutoMQ/automq
-
AutoMQ Architecture Overview: https://docs.automq.com/automq/architecture/overview
-
AutoMQ S3Stream Overview: https://docs.automq.com/automq/architecture/s3stream-shared-streaming-storage/overview
-
AutoMQ Technical Advantages: https://docs.automq.com/automq/architecture/technical-advantage/overview
-
The Difference between AutoMQ and Kafka: https://docs.automq.com/automq/what-is-automq/difference-with-apache-kafka
-
The Difference between AutoMQ and WarpStream: https://docs.automq.com/automq/what-is-automq/difference-with-warpstream
-
The Difference between AutoMQ and Tiered Storage: https://docs.automq.com/automq/what-is-automq/difference-with-tiered-storage
-
AutoMQ Customers: https://www.automq.com/customer