Lnsight: Metadata Management in AutoMQ
This article describes the metadata management mechanism of AutoMQ, based on AutoMQ Release 1.1.0 [1].
As a next-generation Apache Kafka® distribution redesigned with cloud-native concepts, AutoMQ replaces traditional local disk storage with shared storage services, primarily based on object storage. While object storage offers significant cost advantages for AutoMQ, the differences in interface and billing compared to traditional local disks present challenges in implementation. To address this, AutoMQ extends KRaft to implement a stream storage metadata management mechanism tailored for object storage environments, balancing cost efficiency and ensuring high read and write performance based on object storage.
In a previous article (How AutoMQ Achieves 100% Apache Kafka Protocol Compatibility [2]), we introduced how AutoMQ's storage layer utilizes S3Stream [3] to achieve streaming read and write on object storage services. Each partition has multiple streams corresponding to it, responsible for storing partition metadata, messages, Time Index, Txn Index, etc.
AutoMQ uses KV metadata to save the StreamId of the MetaStream corresponding to the partition, ensuring that the partition can correctly obtain the mapping relationship with the Stream when opened on different nodes.
Due to the one-to-many mapping relationship between partitions and Streams, events such as partition reassignment, data writes, and offset trims can cause corresponding changes in the Stream state. Therefore, AutoMQ maintains corresponding metadata for each Stream, mainly consisting of the following components:
-
Stream Epoch: When a partition reassignment occurs, the corresponding Stream Epoch is incremented. All subsequent operations on the Stream must check the Epoch to ensure that only the current node holding the Stream can perform operations on it.
-
Start Offset: Indicates the starting offset of the Stream. When a partition is trimmed, the starting offset of the corresponding Stream is updated accordingly.
-
End Offset: Indicates the maximum offset of the Stream. When a partition message is successfully written and committed, the maximum offset of the Stream is advanced accordingly.
-
Ranges: As partitions are reassigned, Streams generate data on different nodes. Ranges store the offset changes of the Stream during its active periods on various nodes. The specific role of Ranges will be introduced later.
-
StreamObjects: Used to store the ObjectId of the StreamObject corresponding to the Stream and the offset range on the respective Object.
Whenever the Controller receives operations related to the Stream (such as create, open, commit, trim, etc.), it generates a corresponding S3StreamRecord. After persisting through the KRaft layer, the state is updated in memory and synchronously updated in the metadata cache of each Broker.
Node metadata consists of the following parts:
-
Node Id: The node's Id
-
Node Epoch: The node's Epoch, which functions similarly to the Stream Epoch. When a node restarts, its Node Epoch is incremented to ensure that only nodes with the latest Epoch can perform Stream-related operations
-
Failover Mode: Indicates whether the current node is in Failover mode (AutoMQ's failover capabilities will be introduced in subsequent articles)
-
StreamSetObjects: Stores various StreamSetObjects generated by the current node, along with the offset information for different Streams on each Object
Among these, Node Epoch and Failover Mode are updated when the node first starts by generating a NodeWALMetadataRecord through the open streams interface. StreamSetObjects are updated by an S3StreamSetObjectRecord when the node submits a StreamSetObject to the Controller.
Object metadata is responsible for managing the lifecycle of all object storage objects, including the object's status, size, Key, expiration time, submission time, and the time it was marked for deletion.
This section will introduce how AutoMQ efficiently utilizes the aforementioned metadata at various stages to manage object storage.
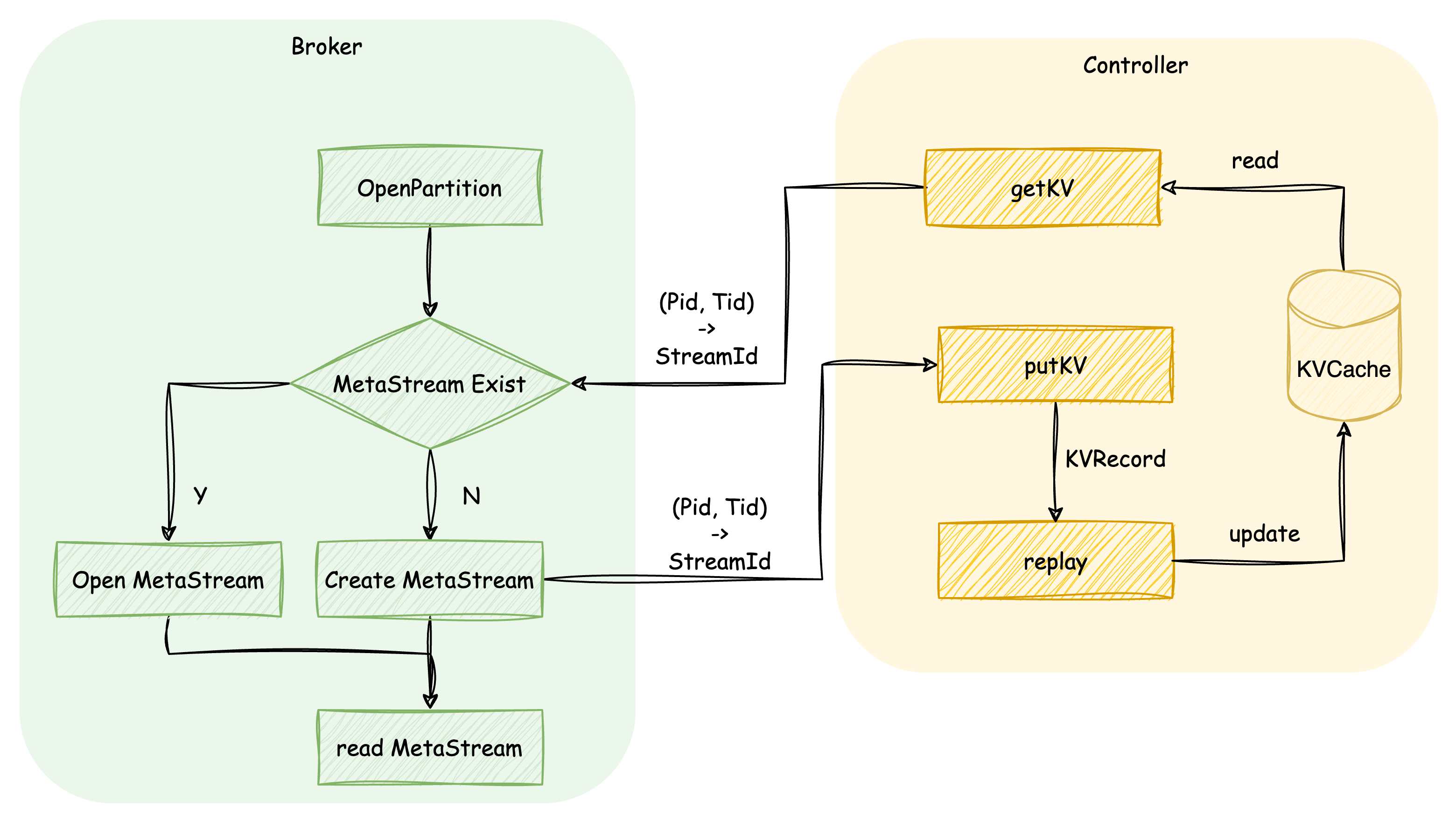
When a partition is opened, the node first requests the MetaStream Id corresponding to that partition from the Controller. If the MetaStream does not exist, it means the partition is being created for the first time. At this point, the node will create a MetaStream for the partition and send the mapping relationship between the partition and the MetaStream to the Controller. After receiving this, the Controller will create a KVRecord based on the Key and Value. This mapping relationship will then be written into memory after being persisted through the KRaft layer. If the MetaStream exists, the information of each Segment corresponding to the partition will be read from the MetaStream, allowing subsequent reads and writes to the partition to be correctly translated into reads and writes to the Stream.
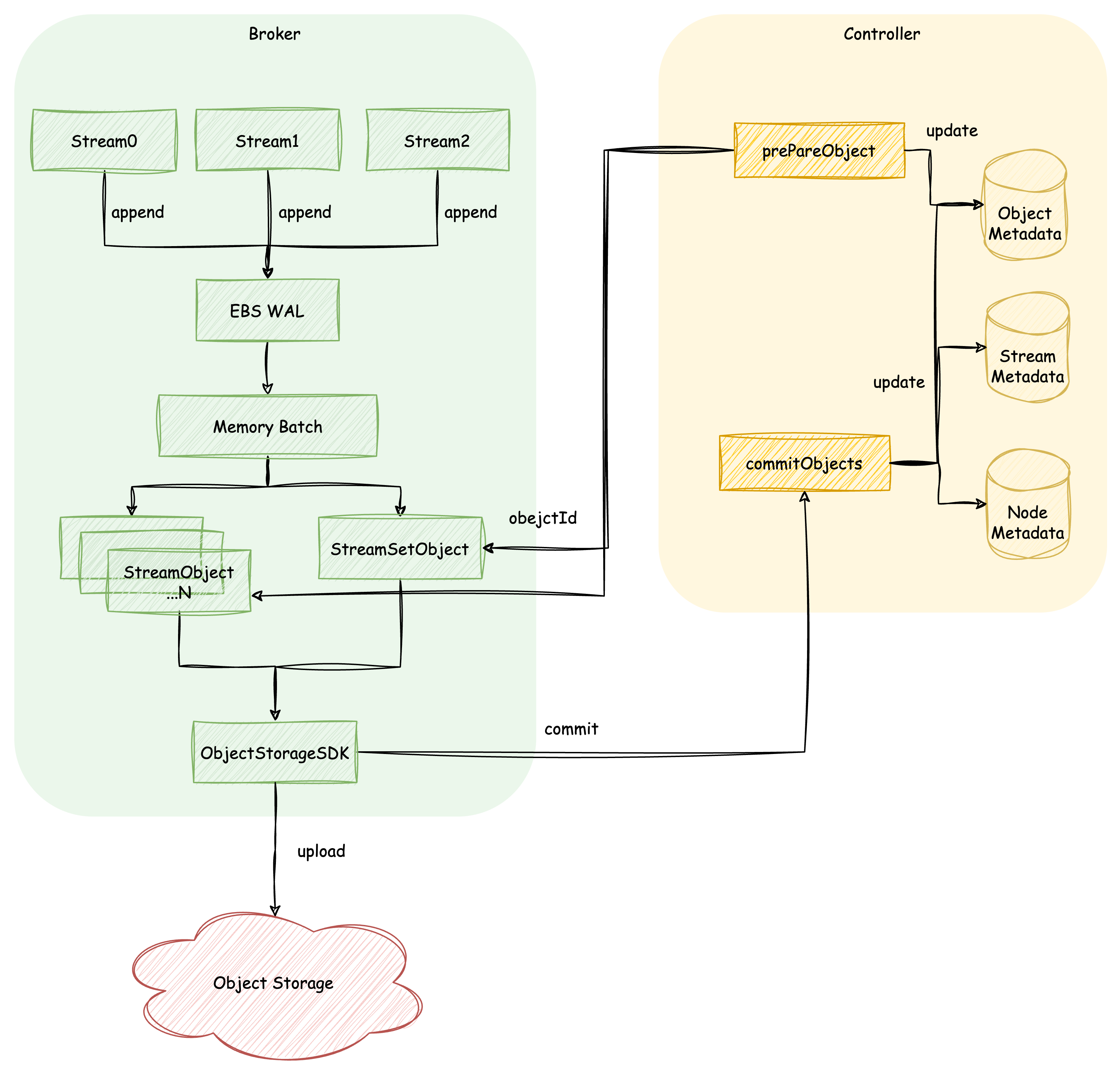
All writes to the partition, through the mapping relationship parsed from the aforementioned MetaStream, will ultimately be transformed into writes to the Stream. All data written to the Stream is first written to the EBS WAL, and after successful persistence, the result is returned to the upper layer. Meanwhile, the written data will continue to be batch-mixed in memory until the batch size exceeds a threshold, triggering an upload.
Once the upload is triggered, the node traverses the data in the current batch for each Stream, uploading continuous data segments that exceed a certain size threshold as StreamObjects, while the remaining data is uploaded as StreamSetObjects. When uploading each Object, the node first requests a globally unique Object Id from the Controller. At this point, the Object's status and expiration time will be recorded in the Controller's Object metadata. The node then generates the write path for the object storage using the Object Id and uploads the data.
When all objects generated by the current upload task have been completely written, the node will initiate a Commit request to the Controller. The Controller will generate a series of KRaft Record updates to the metadata:
-
Object Metadata: Change the state of the submitted object from PREPARED to COMMITTED.
-
Stream Metadata: Advance the maximum offset of each stream in the batch data of this submission and update the corresponding StreamObjects.
-
Node Metadata: Update the corresponding node's StreamSetObjects.
If an exception occurs during the upload process causing the upload to terminate, the Controller will delete the objects that exceed the expiration time and are still not submitted through a scheduled task to avoid object leaks.
The read of partition data will also be converted to a read of the stream. When the segment of data to be read is no longer present in the node cache, it is necessary to initiate a read from object storage. Through the previously introduced partition write process, we already know that the metadata has saved the objects where each segment of stream data resides. At this point, it is only necessary to index the list of objects corresponding to the segment of data to be read from the metadata and then initiate a read request to object storage. It should be noted that since all metadata of AutoMQ is constructed based on the KRaft mechanism, the above metadata changes will be distributed to each node with the synchronization of KRaft Records. Therefore, each broker caches the latest metadata information, so the indexing process occurs entirely within the local cache. The specific indexing process is as follows:
-
First, obtain the StreamObjects corresponding to the stream from the local stream metadata cache. Since each StreamObject corresponds to a continuous segment of the stream, it is only necessary to traverse from the first StreamObject and add those within the range to the result until encountering the first StreamObject that exceeds the expected read range, or until all StreamObjects have been traversed.
-
When traversing the StreamObject exits and the expected read range has not yet been satisfied, it indicates that the subsequent data resides in the StreamSetObject. As mentioned in the metadata overview above, Stream metadata records the Ranges information, which corresponds to the positions of the Stream on different nodes. The Ranges is an ordered list arranged by position. At this point, a single binary search is sufficient to find the current expected data segment's Range and the corresponding Range's Node Id.
-
After finding the Node Id, you can obtain the StreamSetObjects corresponding to that Node in the Node metadata. Each StreamSetObject contains the position information of each Stream that makes up the Object. At this point, traversing the StreamSetObjects once will yield the StreamSetObject that matches the current expected data segment.
-
After completing the traversal of the StreamSetObjects, there might still be cases where the expected read data has not been fully satisfied. At this point, you will re-enter step 1 and continue the next round of search from the previous StreamObject traversal point until the request range is satisfied. If due to metadata synchronization delays or other reasons, all Objects have been traversed and the request still cannot be satisfied, the partially satisfied request will be returned, waiting for the next request retry.
As can be seen, due to the complexity of the StreamSetObject composition, the majority of indexing costs are spent on searching the StreamSetObject. To enhance indexing speed, AutoMQ has also implemented a Compaction mechanism, enabling most data of the Stream to reside within the StreamObject (interested readers can refer to: The Secret of Efficient Data Organization in AutoMQ Object Storage: Compaction [4]).
This article introduced AutoMQ's metadata management mechanism based on KRaft. Compared to traditional metadata management based on Zookeeper, the Controller, having become the processing node for all metadata, plays a crucial role in the system's normal operation. AutoMQ has further expanded the metadata related to object storage, which also imposes higher demands on the stability of the Controller node. To this end, the AutoMQ Team continues to optimize metadata scalability and indexing efficiency, ensuring efficient and stable operation in single ultra-large-scale clusters.
[1] AutoMQ Release 1.1.0:/~https://github.com/AutoMQ/automq/releases/tag/1.1.0
[2] How AutoMQ Achieves 100% Protocol Compatibility with Apache Kafka: https://mp.weixin.qq.com/s/ZOTu5fA0FcAJlCrCJFSoaw
[3] S3Stream: A Shared Streaming Storage Library:/~https://github.com/AutoMQ/automq/tree/main/s3stream
[4] The Secret of Efficient Data Organization in AutoMQ Object Storage: Compaction: https://mp.weixin.qq.com/s/z_JKxWQ8YCMs-fbC42C0Lg