AutoMQ: Cloud Native Kafka for Cost Effective Flink Stream Processing
The combination of Apache Kafka® and Apache Flink provides a powerful solution for building real-time stream processing applications [1]. Kafka, as a high-throughput, low-latency distributed message queue, handles data collection, buffering, and distribution; while Flink is a robust stream processing engine responsible for real-time computation and analysis. Together, they complement each other and form a solid foundation for real-time stream processing applications.
The Flink Kafka Source serves as a bridge between Kafka and Flink, providing Apache Flink® with the capability to read data streams from Apache Kafka®. Acting as the starting point for data input in Flink, it efficiently and reliably ingests message data from Kafka Topics into Flink stream processing programs, forming the data foundation for subsequent real-time calculations, analysis, and processing.
Notably, AutoMQ, as a community fork project of Apache Kafka, has redesigned and implemented the storage layer while completely retaining the Apache Kafka computational layer code. It ensures 100% compatibility with Apache Kafka. This means that within the Flink ecosystem, Flink Kafka Source/Sink, specifically developed for Kafka, can be fully compatible with AutoMQ.
Since Flink 1.12, KafkaSource and KafkaSink, developed based on the new source API ([FLIP-27])[2] and new sink API ([FLIP-143])[3], are the recommended Kafka connectors. FlinkKafkaConsumer and FlinkKafkaProducer have been deprecated.
In [FLIP-27: Refactor Source Interface], the aim is to address numerous issues and drawbacks in the current streaming source interface (SourceFunction) and to unify the source interface between batch and streaming APIs.
In [FLIP-27], the issues present in SourceFunction are elaborately discussed and can be summarized as follows:
-
Inconsistent implementation between batch and stream sources: Flink provides different Source interfaces for batch and stream processing, leading to code duplication and maintenance challenges.
-
Logical coupling: The "work discovery" (such as discovering Kafka's partitions or filesystem splits) and the actual data reading logic are intertwined within the SourceFunction interface and DataStream API, complicating implementations, such as Kafka and Kinesis's Source implementations.
-
Lack of explicit support for partitions/splits: The current interface does not clearly express the concept of partitions or splits. This makes it challenging to implement certain functionalities independently of the Source, such as event-time alignment, per-partition watermarking, dynamic split assignment, and work stealing. For instance, while both Kafka and Kinesis consumers support per-partition watermarking, as of Flink 1.8.1, only the Kinesis consumer supports event-time alignment (selectively reading from splits to ensure event time progresses evenly).
-
Checkpoint lock issues:
-
The `SourceFunction` holds a checkpoint lock, necessitating that implementing elements be sent and states updated under the lock, thereby restricting Flink's ability to optimize lock usage.
-
The lock is not a fair lock, causing certain threads (such as checkpoint threads) to potentially fail in acquiring the lock promptly under heavy contention.
-
The current locking mechanism also hinders the implementation of operators based on the lock-free Actor/Mailbox model.
-
-
Lack of a unified threading model: Each Source has to implement its own complex threading model, making it difficult to develop and test new Sources.
In Flink, a Record Split refers to an ordered collection of records with a unique identifier, representing a contiguous segment of data from the source. Record Splits are fundamental units in Flink for parallel processing, fault-tolerant recovery, and state management.
The definition of a Split can be flexible and variable. Taking Kafka as an example:
-
A Split can be an entire partition.
-
A Split can also be a portion of a partition, such as records from offset 100 to 200.
Using Kafka as an example, let's explain the characteristics of a Split:
-
Ordered Collection of Records: Records within a shard are ordered, for instance, sorted by offset in Apache Kafka®.
-
Unique Identifier: Each shard has a unique ID for distinguishing different shards, like Topic-PartitionId.
-
Progress Trackable: Flink records the processing progress of each shard to allow recovery in case of failure, such as the consumption offset of a partition.
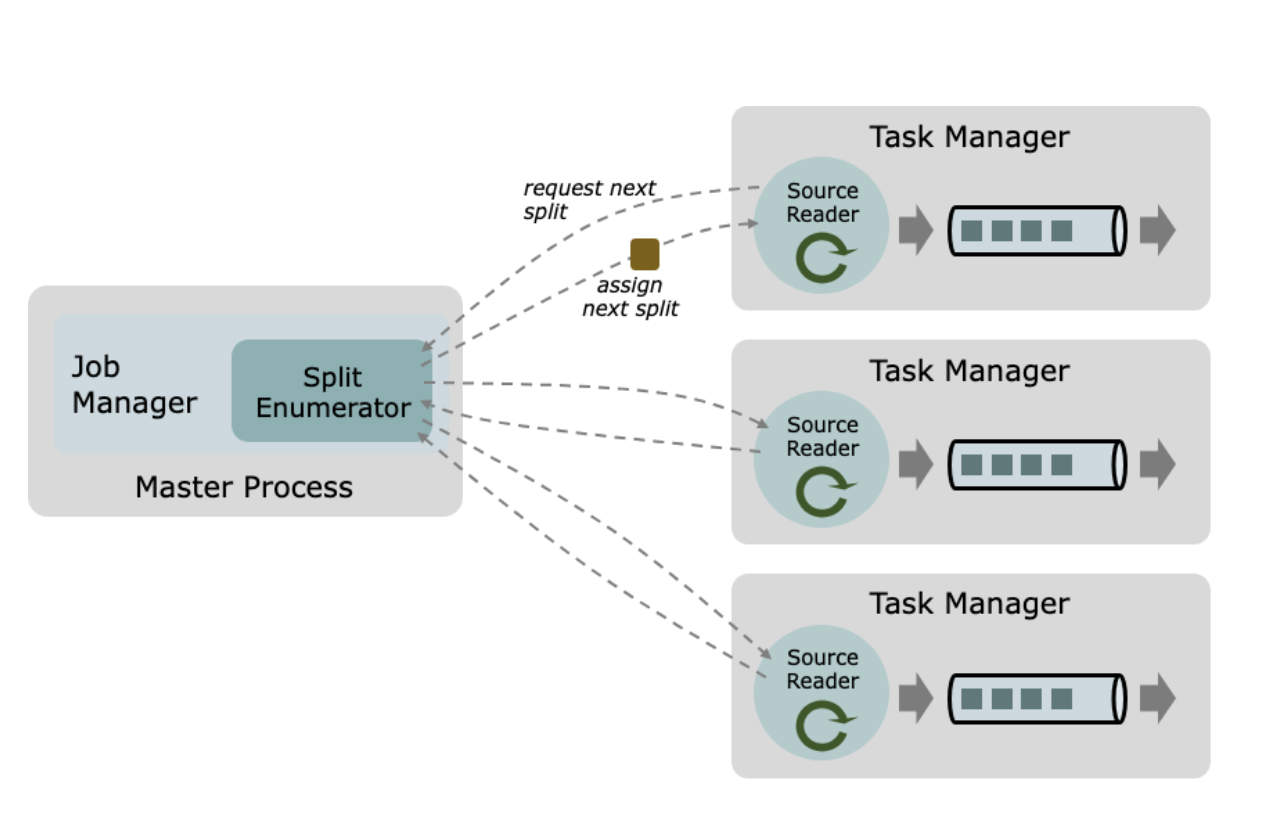
In Flink, the split enumerator (Split Enumerator) is responsible for managing and assigning record shards from the data source to Source Readers for data reading. It acts as the "commander" in the Flink data reading process.
Primary Responsibilities:
-
Split Discovery:
-
Conduct regular scans of external data sources such as Kafka and file systems to identify newly added record splits.
-
For instance, Kafka's Split Enumerator monitors changes in the Topic partitions and creates new splits when new partitions are added.
-
-
Split Assignment:
-
Distribute the discovered shards to Source Readers for reading.
-
Coordinate shard assignment among multiple Source Readers to ensure load balancing.
-
Monitor the progress of Source Readers and dynamically adjust shard allocation. For example, transfer some shards from an overloaded reader to an idle reader.
-
-
Coordinate Source Readers:
-
Controlling the reading speed of the Source Reader to avoid individual Readers from reading too fast or too slow, which can affect the overall watermark advancement and data processing progress.
-
Handling Source Reader failures, such as reassigning the shards managed by a failed Reader to other Readers.
-
The Source Reader is the component in Flink that actually performs the data reading operations. It is responsible for reading data from the record shards assigned by the Split Enumerator and passing the data to downstream operators for processing.
Primary Responsibilities:
-
Reading Data from Record Shards:
-
Connect to the external data source according to the record slice information assigned by the Split Enumerator.
-
Read data from the specified location, such as consuming messages from a specified Kafka offset.
-
Continue reading data until the slice ends or a stop signal is received.
-
-
Event-time watermark processing:
-
Extract event time information from the read records.
-
Generate watermarks based on event time and send them to downstream operators for handling out-of-order data and event time windows.
-
-
Data deserialization:
- Deserializing raw data read from external data sources (e.g., byte streams) into data structures that Flink can process internally (such as elements in a DataStream).
-
Data Dispatch:
- Sending deserialized data to downstream operators for processing.
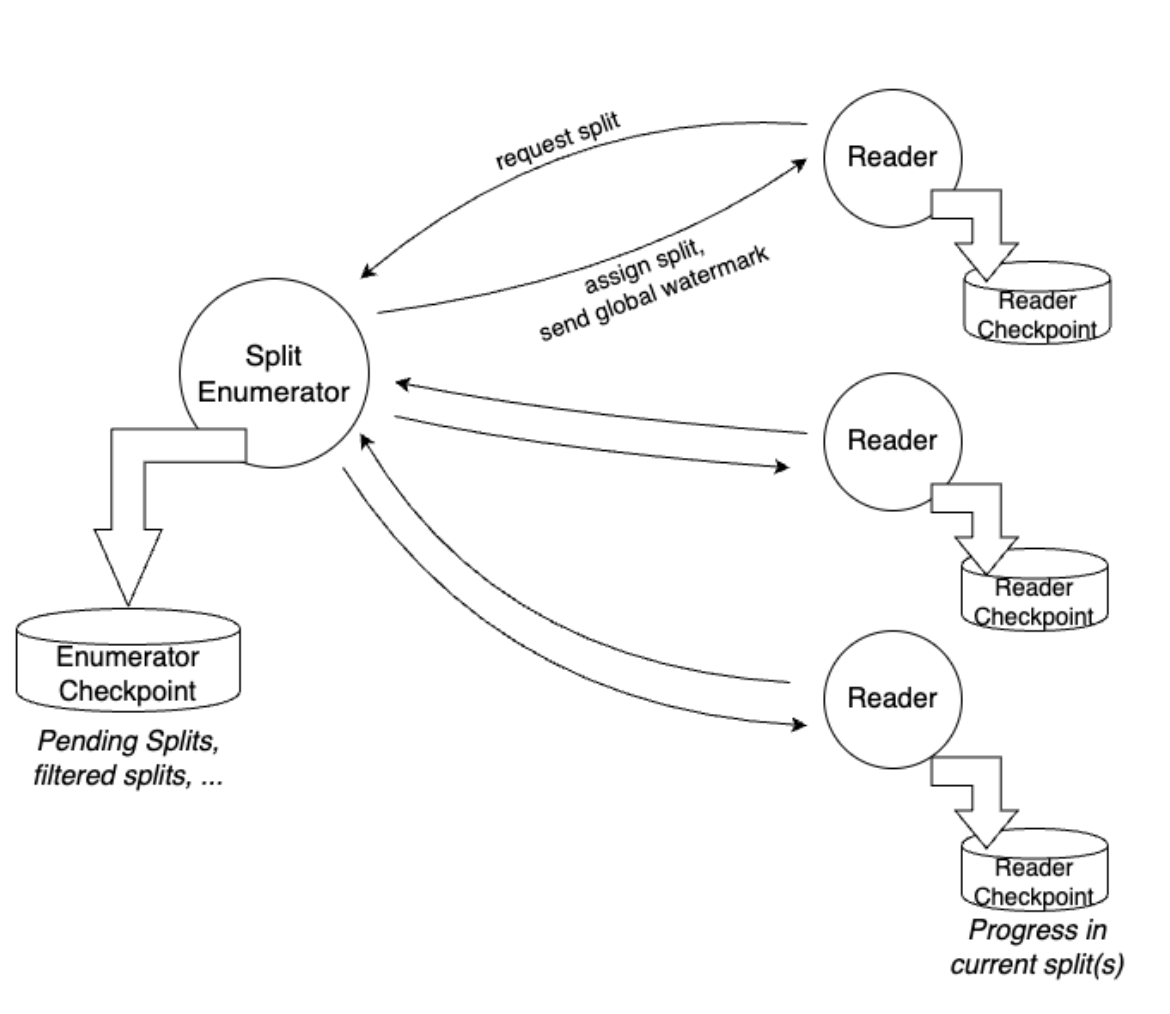
Split the functionality of Source into two main components:
-
SplitEnumerator:
-
Responsible for discovering and assigning Splits, such as files, Kafka partitions, etc.
-
Can be run on either JobManager or TaskManager.
-
-
Reader:
-
Responsible for reading actual data from assigned splits.
-
Incorporates most of the current Source interface functionalities.
-
Capable of sequentially reading a series of bounded splits as well as reading multiple (unbounded) splits in parallel.
-
Previously, the design of [FlinkKafkaConsumerBase] [4] centralized logic for Kafka partition discovery (KafkaPartitionDiscoverer), data reading (KafkaFetcher), and a producer-consumer model based on a blocking queue, etc. Overall, the design was relatively complex, making it difficult to maintain and extend.
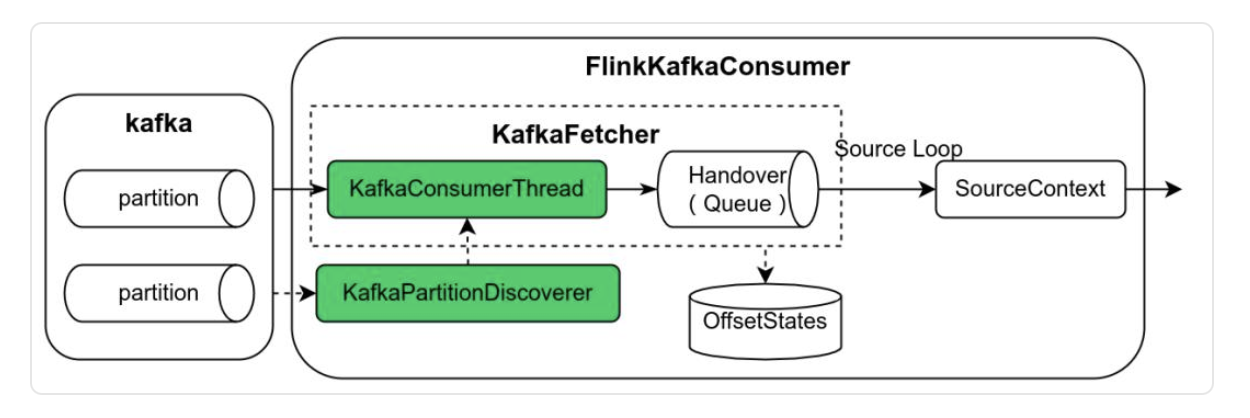
@Override
public void run(SourceContext<T> sourceContext) throws Exception {
// ... (initialization code omitted)
// ... (logic omitted)
this.kafkaFetcher =
createFetcher(
// ... (parameters omitted)
);
// ... (logic omitted)
// Choose execution path based on whether partition discovery is enabled
if (discoveryIntervalMillis == PARTITION_DISCOVERY_DISABLED) {
// Directly run the data fetch loop
kafkaFetcher.runFetchLoop();
} else {
// Run with partition discovery logic
runWithPartitionDiscovery();
}
}
Under this approach, it can be [separated and designed] as:
KafkaSourceEnumerator:
-
Discover partitions: Periodically or one-time identification of all partitions within an Apache Kafka® Topic.
-
Initialize partitions: Retrieve the start and end offsets for each partition.
-
Assign partitions: Distribute partitions to different Source Readers and manage the assignment state of the partitions.
KafkaSourceReader handles reading data from the assigned Kafka partitions and processes checkpoint-related logic.
-
Receive and process partitions assigned by the SplitEnumerator.
-
Processing the read data
-
Handling checkpoint
Separated "Work Discovery" from the data reading logic, which improves the modularity and reusability of the code. For instance, different SplitEnumerator implementations can be created for different partition discovery strategies without modifying the Reader's code.
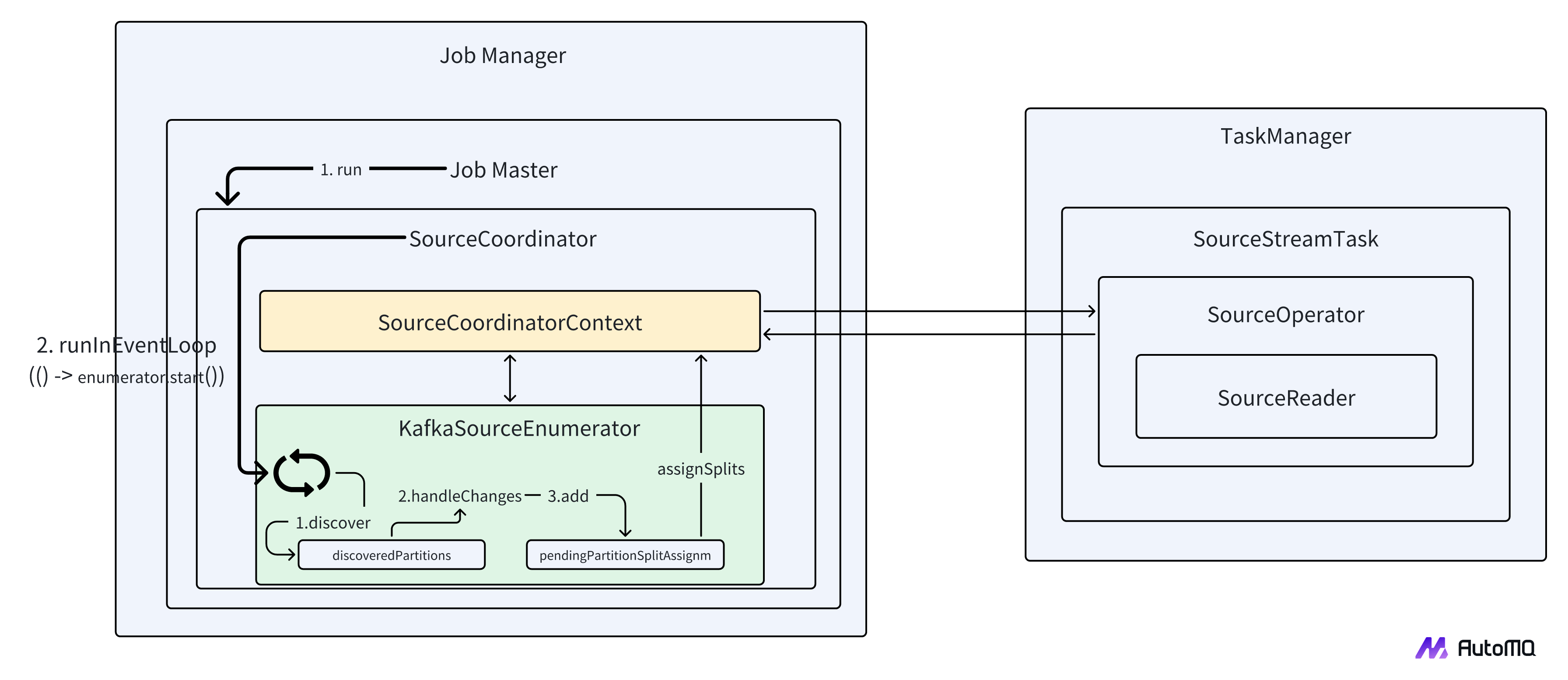
-
When a Flink job starts, a SourceCoordinator instance is created for each Kafka Source task.
-
The `start()` method of `SourceCoordinator` will be called, initiating the following operations:
-
If it is the first startup (not restored from Checkpoint), `source.createEnumerator()` is called to create a `KafkaSourceEnumerator` instance.
-
Call `enumerator.start()` to start the `KafkaSourceEnumerator`.
-
-
The start() method of KafkaSourceEnumerator will be invoked:
-
Initialize the Kafka consumer and Kafka admin client.
-
Determine the partition discovery mode based on the configuration (periodic or one-time).
-
Asynchronously invoke the discoverAndInitializePartitionSplit() method for initial partition discovery.
-
-
The discoverAndInitializePartitionSplit() method performs the following actions:
-
Retrieve Kafka partition change information.
-
Get the starting and ending offsets of the new partitions (for bounded streams).
-
Create a KafkaPartitionSplit object for each new partition.
-
Add the new splits to the pendingPartitionSplitAssignment list.
-
Invoke the assignPendingPartitionSplits() method to assign the splits.
-
-
The assignPendingPartitionSplits() method performs the following actions:
-
Assign pending partitions to available Source Readers.
-
If periodic partition discovery is disabled, the NoMoreSplitsEvent is sent to the Source Reader after the initial shard assignment is completed.
-
In Flink's new Source design, the SplitEnumerator and SourceReader are two independent components responsible for split management and data reading, respectively. However, in practical applications, these two components often need to communicate, such as in the Kafka Source scenario:
-
KafkaSourceReader needs to request the KafkaSplitEnumerator to register the KafkaSourceReader.
-
KafkaSplitEnumerator needs to notify the KafkaSourceReader that there is a new KafkaPartitionSplit to read.
General Communication Mechanism:
To meet the communication needs between the SplitEnumerator and SourceReader, Flink introduces a general message passing mechanism. The core of this mechanism is the SourceEvent interface.
-
SourceEvent: Defines the type of messages exchanged between the SplitEnumerator and the SourceReader.
-
OperatorEvent: This is the interface for passing messages between the OperatorCoordinator and the Operator.
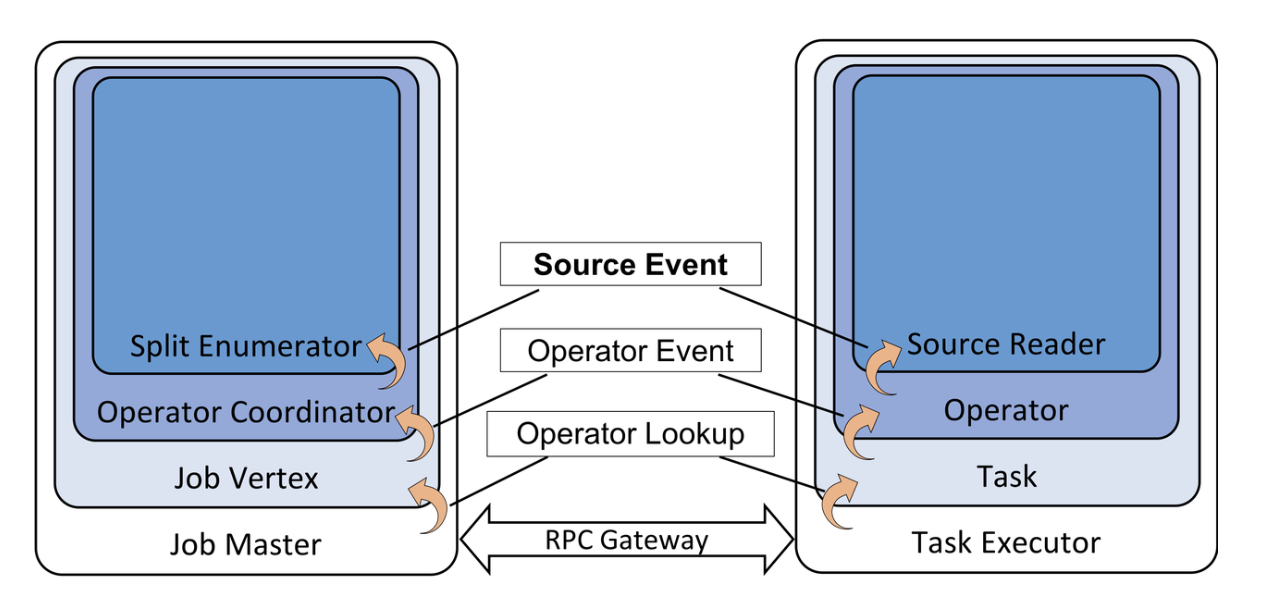
Message passing chain:
-
OperatorEventGateway: Receives OperatorEvents and adds OperatorID information.
-
TaskOperatorEventGateway: Receives events from OperatorEventGateway, adds ExecutionAttemptID information, and forwards them to JobMasterOperatorEventGateway.
-
JobMasterOperatorEventGateway: Acts as an RPC interface between the Task Manager and JobManager, responsible for ultimately sending events to the OperatorCoordinator on the JobManager.
public interface JobMasterOperatorEventGateway {
CompletableFuture<Acknowledge> sendOperatorEventToCoordinator(
ExecutionAttemptID task,
OperatorID operatorID,
SerializedValue<OperatorEvent> event);
}
public interface OperatorCoordinator extends CheckpointListener, AutoCloseable {
...
void handleEventFromOperator(int subtask, OperatorEvent event) throws Exception;
...
}
For SourceCoordinator, the processing logic inside handleOperatorEvent is as follows:
-
RequestSplitEvent: Requests allocation of a new Split by calling enumerator.handleSplitRequest().
-
SourceEventWrapper: Events from SourceReader are processed by calling enumerator.handleSourceEvent().
-
ReaderRegistrationEvent: Reader registration events are processed by calling handleReaderRegistrationEvent().
-
Other Event Types: An exception is thrown, indicating that the event type is not recognized.
(In actual implementations, OperatorEvent can sometimes be directly passed to SourceReader/SplitEnumerator without converting to SourceEvent.)
For SourceOperator, the processing logic within handleOperatorEvent is as follows:
-
AddSplitEvent: A new Split event, indicating that the SplitEnumerator has assigned a new Split to the SourceReader.
-
SourceEventWrapper: Invokes sourceReader.handleSourceEvents() to pass the event to the SourceReader for processing.
-
NoMoreSplitsEvent: Indicates that the SplitEnumerator has assigned all splits.
In the new Flink Source API, the SourceReader interface is responsible for reading data from Source Splits and interacting with the SplitEnumerator. The SourceReader interface code is as follows:
public interface SourceReader<T, SplitT extends SourceSplit>
extends AutoCloseable, CheckpointListener {
void start();
InputStatus pollNext(ReaderOutput<T> output) throws Exception;
CompletableFuture<Void> isAvailable();
void addSplits(List<SplitT> splits);
void notifyNoMoreSplits();
default void handleSourceEvents(SourceEvent sourceEvent) {}
List<SplitT> snapshotState(long checkpointId);
@Override
default void notifyCheckpointComplete(long checkpointId) throws Exception {}
}
The SourceReader is designed as a lock-free, non-blocking interface to support operator implementations in the Actor/Mailbox/Dispatcher style. All methods are called in the same thread, so implementers do not need to handle concurrency issues.
-
The SourceReader reads data asynchronously and notifies the runtime whether the data is readable through the isAvailable() method.
-
pollNext can read the next record in a non-blocking manner and send the record to ReaderOutput. It returns an InputStatus enum value that indicates the read status, such as MORE_AVAILABLE (more data available) or END_OF_INPUT (end of data).
-
The underlying SourceReader interface is quite generic, but it is complex to implement, especially for sources like Kafka or Kinesis that require multiplexing and concurrent reads.
-
Most of the I/O libraries used by connectors are blocking and require additional I/O threads to achieve non-blocking reads.
Therefore, this FP proposes a solution:
- High-level abstraction: Provides a simpler interface, allowing the use of blocking calls and encapsulating complex logic such as multiplexing and event time processing.
Most Readers belong to one of the following categories:
-
Single Reader Single Splits: The simplest type, such as reading a single file.
-
Single Reader Multiple Splits: A Reader can read multiple Splits, for example:
- Sequential Single Split Reading: A single I/O thread sequentially reads each Split, such as a file or database query result.
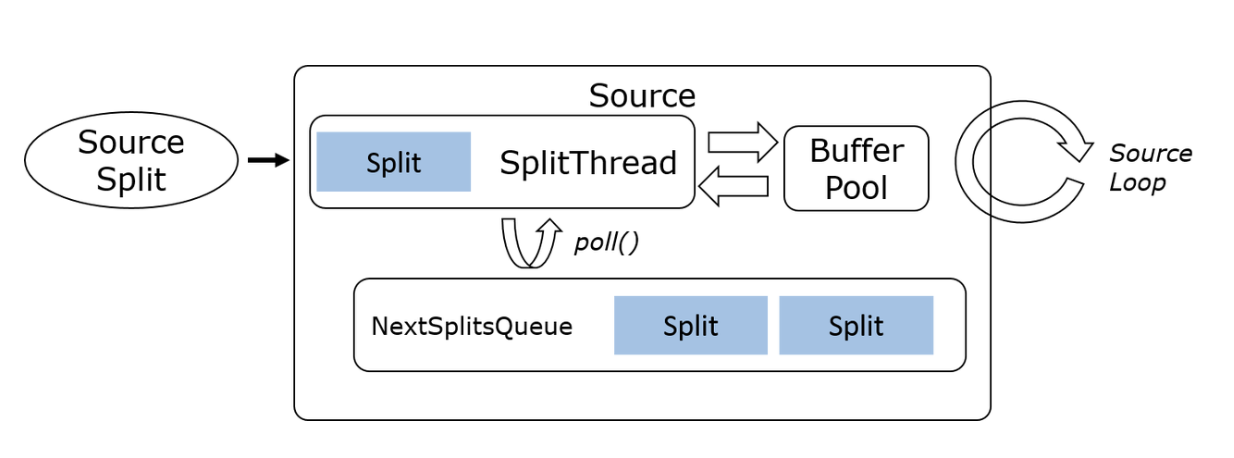
Sequential Single Split
- Multiplexed Multi-Split Reading: A single I/O thread utilizes multiplexing techniques to read multiple splits from sources such as Kafka, Pulsar, Pravega, etc.
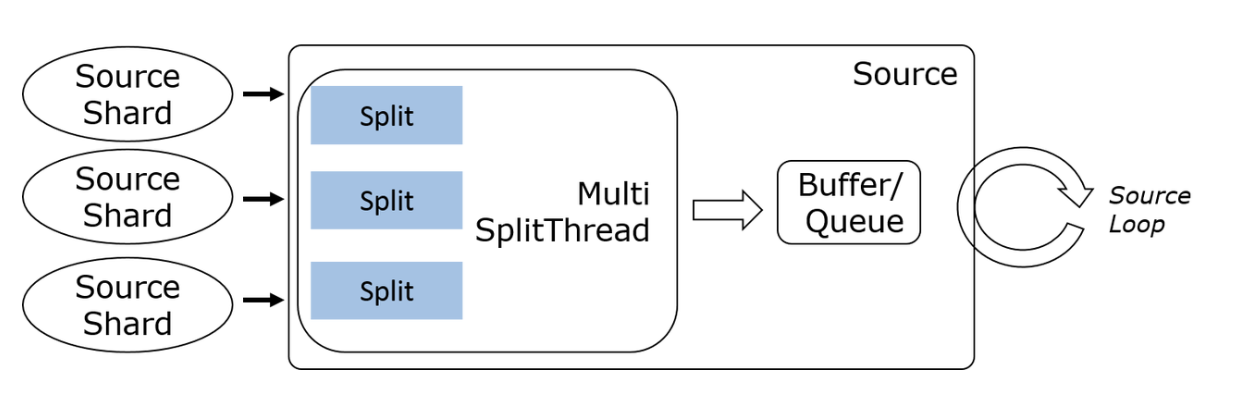
Multi-split Multiplexed
- Multi-threaded Multi-splits Reading: Utilize multiple threads to concurrently read from multiple splits, such as Kinesis.
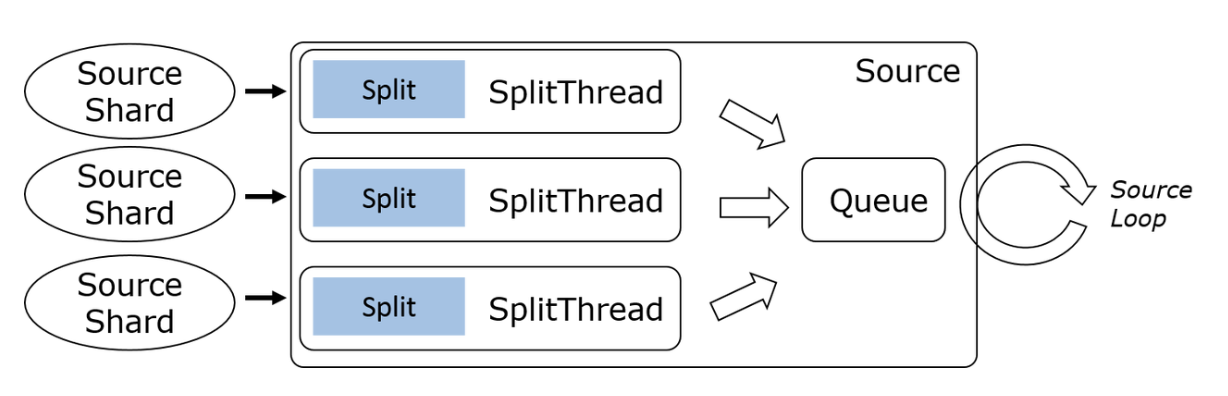
Multi-split Multi-threaded
Based on the above analysis, we abstract the following interface. Developers can choose different high-level Reader types according to actual requirements and create custom Source Readers by implementing a simple interface.
public interface SplitReader<E, SplitT extends SourceSplit> {
RecordsWithSplitIds<E> fetch() throws InterruptedException;
void handleSplitsChanges(Queue<SplitsChange<SplitT>> splitsChanges);
void wakeUp();
}
-
fetch\(): Reads data from a Split and returns aRecordsWithSplitIdsobject, which contains the retrieved records along with the corresponding Split ID. -
handleSplitsChanges\(): Manages changes to Splits, such as the addition or removal of Splits. -
wakeUp\(): Wakes up any blockingfetch\()operation, for example, when a new Split becomes available.
public interface RecordEmitter<E, T, SplitStateT> {
void emitRecord(E element, SourceOutput<T> output, SplitStateT splitState) throws Exception;
}
-
emitRecord: Responsible for transforming raw records (E) read by the SplitReader into the final record type (T).
SourceReaderBase: Provides a foundational implementation of the SourceReader, encapsulating common logic such as event queue handling, Split state management, and SplitFetcher administration.
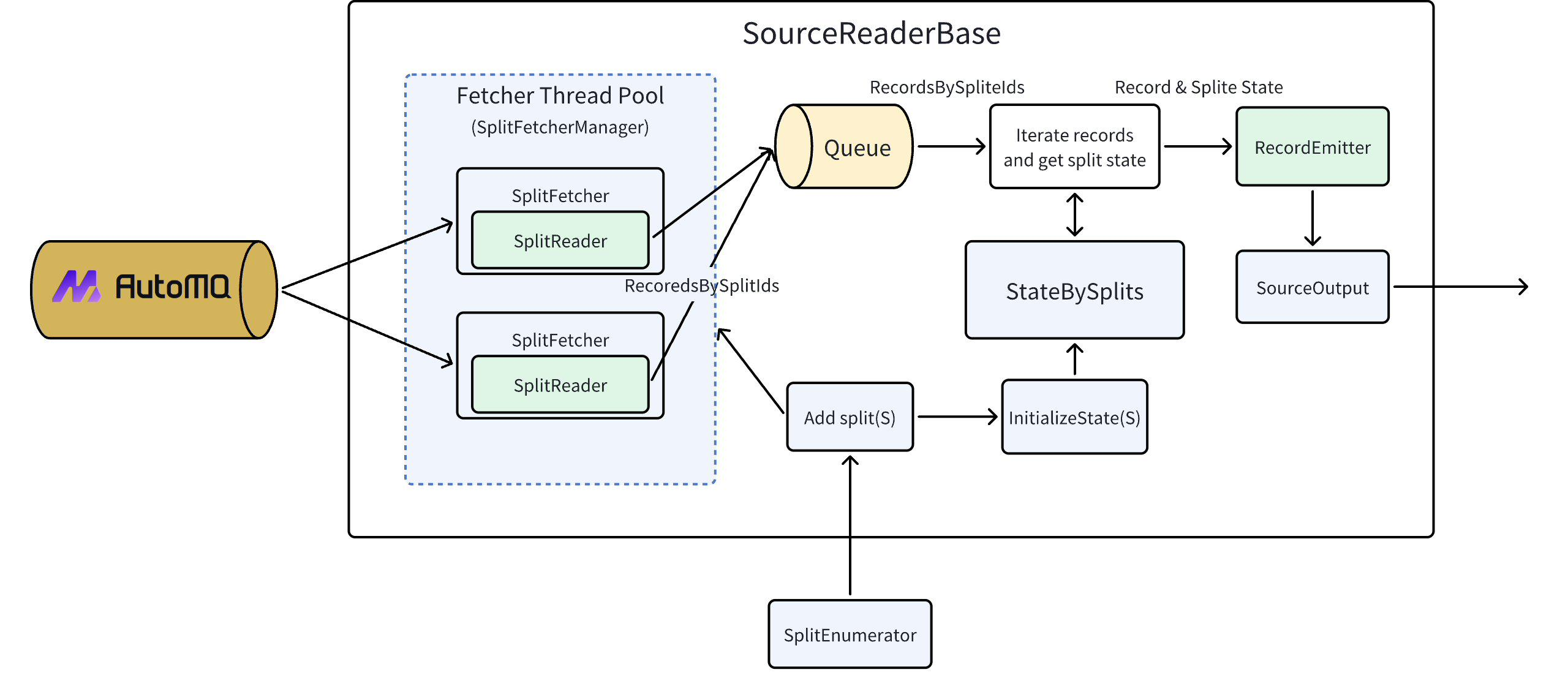
Split Allocation Process
-
SplitEnumerator Allocates Splits: The SplitEnumerator identifies new splits and assigns them to the corresponding SourceReader.
-
SourceReader Receives Splits: Upon receiving new splits, the SourceReader initializes the state and invokes the
addSplits\()method of the SplitFetcherManager. -
SplitFetcherManager Manages Splits: SplitFetcherManager retrieves or creates a SplitFetcher and adds the splits to it. It then adds an AddSplitsTask to the task queue and notifies the SplitFetcher’s worker thread.
-
AddSplitsTask Notifies: The AddSplitsTask informs the SplitReader to handle the SplitsChanges.
-
SplitReader Updates Splits: The SplitReader updates the assigned splits.
Data Retrieval Process
-
SplitReader Reads Data: The SplitReader reads data from the split and packages it into a RecordsWithSplitIds object, which is returned to the SourceReader.
-
SourceReader Processes Data: The SourceReader iterates through each record in the RecordsWithSplitIds and retrieves the corresponding SplitState based on the record’s Split ID.
-
RecordEmitter Handles Records: The SourceReader passes records and SplitState to the RecordEmitter for processing.
-
RecordEmitter Transforms Records: The RecordEmitter transforms the raw record type (E) to the final record type (T). It also updates the SplitState, such as tracking the read progress, and adds the processed records to SourceOutput.
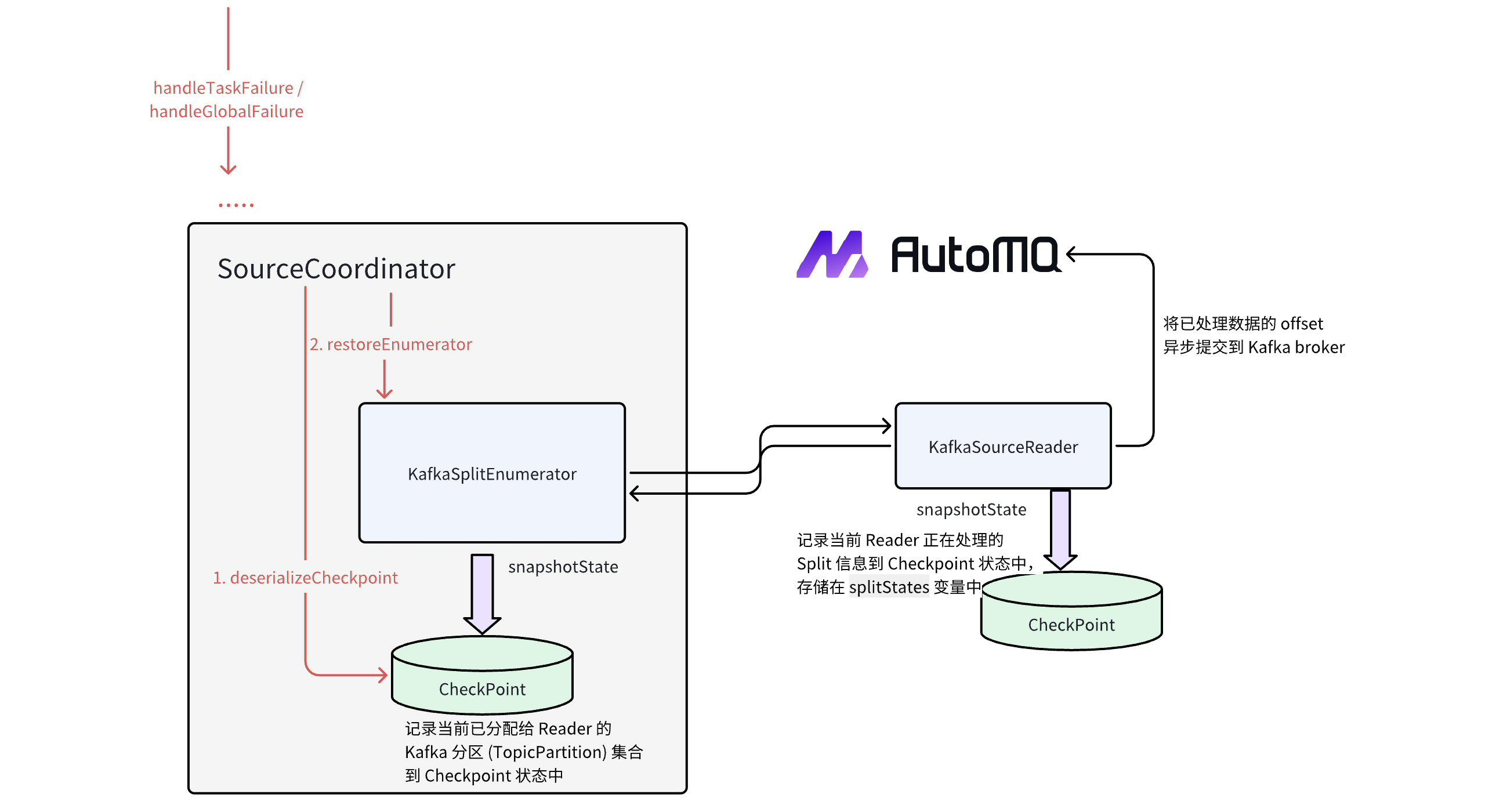
Flink’s fault tolerance mechanism relies on checkpoints, which periodically create snapshots of the data stream, including the source read positions and operator state information. In case of a failure, Flink can restore from the most recent checkpoint, ensuring Exactly-Once semantics.
In the Flink Kafka Source, both KafkaSourceEnumerator and KafkaSourceReader have distinct checkpoint and failover processes. As illustrated, the Flink Kafka Source leverages the checkpoint mechanism to record source read positions and the state of Source Readers. During failover, these records are used to restore the state and ensure no data loss or duplicate processing.
Combining Apache Flink with messaging queues is a powerful approach to building real-time stream processing applications. This article first introduces the integration of Flink with Kafka and delves into the restructuring of the Flink Kafka Source to address deficiencies in its original design.
The restructured Flink Kafka Source includes:
-
Introduction of Split Enumerator and Source Reader to separate "Work Discovery" and Reading, enhancing modularity and reusability.
-
Implementation of asynchronous communication between Enumerator and Reader through the Source Event mechanism, improving code maintainability.
-
Provision of high-level abstractions such as SplitReader and RecordEmitter, and implementation of SourceReaderBase to allow Kafka Source to focus on implementing SplitReader and RecordEmitter.
The restructured Flink Kafka Source ensures Exactly-Once semantics by recording data source read positions and Source Reader state information through the Checkpoint mechanism. However, traditional Shared Nothing architecture messaging queues (e.g., Kafka) face challenges like high storage costs, complex maintenance, and difficult scaling in high data volume and high concurrency scenarios.
AutoMQ, as a new generation cloud-native messaging queue, employs a Shared Storage architecture with cost-effective storage based on object storage, and is 100% compatible with Kafka. The future integration of AutoMQ and Flink will offer the following advantages for cloud-native real-time stream processing applications:
-
Lower Costs: Particularly cost-effective when handling cold data.
-
Higher Elasticity: Supports automatic cluster scaling and traffic self-balancing, flexibly adapting to business changes and ensuring system stability.
-
Simplified Maintenance: Shared Storage architecture simplifies cluster deployment and maintenance.
-
Seamless Integration with the Kafka Ecosystem: Facilitates smooth enterprise migration.
The combination of AutoMQ and Flink will be a key development direction for future cloud-native real-time stream processing applications, providing enterprises with more cost-effective, efficient, and convenient stream processing solutions.
[1]: Apache Kafka (including Kafka Streams) + Apache Flink = Match Made in Heaven
[2]: https://cwiki.apache.org/confluence/display/FLINK/FLIP-27%3A+Refactor+Source+Interface
[3]: https://cwiki.apache.org/confluence/display/FLINK/FLIP-143%3A+Unified+Sink+API