Benchmark: AutoMQ vs. Apache Kafka
-
300 Times Faster Partition Reassignment Compared to Apache Kafka®: AutoMQ's partition reassignment speed is approximately 300 times faster than Apache Kafka®. AutoMQ transforms Kafka’s high-risk routine operational tasks into automated, low-risk operations with minimal impact.
-
4 Minutes from Zero to 1 GiB/s Elasticity: AutoMQ clusters can automatically scale from 0 MiB/s to 1 GiB/s within just 4 minutes. This allows the system to quickly scale out and respond to sudden traffic spikes.
-
200 Times More Efficient Cold Read Compared to Apache Kafka®: With AutoMQ's read-write separation, the sending time is reduced by 200 times compared to Apache Kafka®, and the catch-up throughput is increased by 5 times. AutoMQ can easily handle scenarios such as online message burst absorption and offline batch processing.
-
Twice the Throughput Limit Compared to Apache Kafka®: With the same hardware specifications, AutoMQ's maximum throughput is twice that of Apache Kafka®, and the P999 latency for sending is only 1/4 of Apache Kafka®. In real-time stream processing scenarios, using AutoMQ can achieve faster results at a lower cost.
-
1/11th the Billing Cost Compared to Apache Kafka®: AutoMQ fully leverages Auto Scaling and object storage, achieving an 11-fold cost reduction compared to Apache Kafka®. With AutoMQ, there is no need to provision capacity for peak usage, enabling true pay-as-you-go computing and storage.
The benchmark is enhanced based on the Linux Foundation's OpenMessaging Benchmark to simulate real user scenarios with dynamic workloads. All test scenarios and configurations can be found in the Github repository.
AutoMQ defaults to flushing data to disk before responding, with the following configuration:
acks=all
flush.message=1
AutoMQ ensures high data durability through the EBS underlying multi-replica mechanism, eliminating the need for multi-replica configuration on the Kafka side.
Apache Kafka version 3.6.0 was chosen, and based on Confluent's recommendations, flush.message = 1 is not set. Instead, a three-replica memory asynchronous flush to disk is used to ensure data durability (power failures in data centers can cause data loss), with the following configuration:
acks=all
replicationFactor=3
min.insync.replicas=2
From a cost-effectiveness perspective, smaller instance types with EBS are more advantageous than larger instances with SSD.
Using the example of small-scale r6in.large + EBS vs. large-scale i3en.2xlarge + SSD:
-
i3en.2xlarge, 8 vCPUs, 64 GB memory, network baseline bandwidth of 8.4 Gbps, comes with two 2.5 TB NVMe SSDs, maximum disk throughput of 600 MB/s; price $0.9040/h.
-
r6in.large * 5 + 5 TB EBS, 10 vCPUs, 80 GB memory, network baseline bandwidth of 15.625 Gbps, EBS baseline bandwidth of 625 MB/s; price (compute) 0.1743 * 5 + (storage) 0.08 * 5 * 1024 / 24 / 60 = $1.156/h.
At first glance, the price and performance of both options are quite similar. Considering that in actual production, we aim to retain data for a longer period, using i3en.2xlarge would require horizontally scaling the compute nodes to increase the storage space of the cluster, wasting compute resources. If we use r6in.large + EBS, we only need to adjust the capacity of EBS.
Therefore, from a cost and performance perspective, both AutoMQ and Apache Kafka choose r6in.large as the smallest elastic unit for Brokers, with storage options being GP3 type EBS and Standard S3.
-
r6in.large: 2 vCPUs, 16 GB memory, network baseline bandwidth of 3.125 Gbps, EBS baseline bandwidth of 156.25 MB/s; price $0.1743/h.
-
GP3 EBS: free tier includes 3000 IOPS, 125 MB/s bandwidth; price for storage $0.08 per GB per month, additional bandwidth $0.040 per MB/s per month, additional IOPS $0.005 per IOPS per month.
AutoMQ and Apache Kafka have different positioning for EBS:
-
AutoMQ uses EBS as a write buffer, so EBS only needs to be configured with 3 GB of storage, and IOPS and bandwidth can use the free tier.
-
Apache Kafka data is stored on EBS, and the EBS space is determined by the traffic and retention time of the specific test scenario. Additional EBS bandwidth of 31 MB/s can be purchased to further improve the unit cost throughput of Apache Kafka.
In a production environment, a Kafka cluster typically serves multiple businesses. The fluctuations in business traffic and partition distribution may cause cluster capacity shortages or machine hotspots. Kafka operators need to expand the cluster and reassign the hot partitions to idle nodes to ensure the availability of the cluster's service.
The time for partition reassignment determines emergency response and operational efficiency.
-
The shorter the partition reassignment time, the shorter the time from cluster expansion to meeting capacity demands, and the shorter the service disruption time.
-
The faster the partition reassignment, the less observation time for operators, allowing for quicker operational feedback and subsequent actions.
300x efficiency improvement: AutoMQ compared to Apache Kafka reduces the 30 GiB partition reassignment time from 12 minutes to 2.2 seconds.
This test measures the reassignment time and impact of moving a 30 GiB partition from one node to another, where no replica of the partition exists, under regular send/consume traffic conditions for both AutoMQ and Apache Kafka. The specific test scenarios are:
-
Two r6in.large instances as brokers, on which:
-
Create a single-partition, single-replica Topic A with continuous read/write throughput of 40 MiB/s.
-
Create a four-partition, single-replica Topic B with continuous read/write throughput of 10 MiB/s as background traffic.
-
-
After 13 minutes, reassign the only partition of Topic A to another node, with a reassignment throughput limit of 100 MiB/s.
Each Apache Kafka broker additionally mounts a 320GB 156MiB/s gp3 EBS for data storage.
Driver files: apache-kafka-driver.yaml, automq-for-kafka-driver.yaml
Load file: partition-reassignment.yaml
AutoMQ installation configuration file: partition-reassignment.yaml
| Comparison |
AutoMQ |
Apache Kafka |
|---|---|---|
| Reassignment duration |
2.2s |
12min |
| Reassignment impact |
Maximum send latency 2.2s |
Continuous send latency jitter 1ms ~ 90ms within 12min |
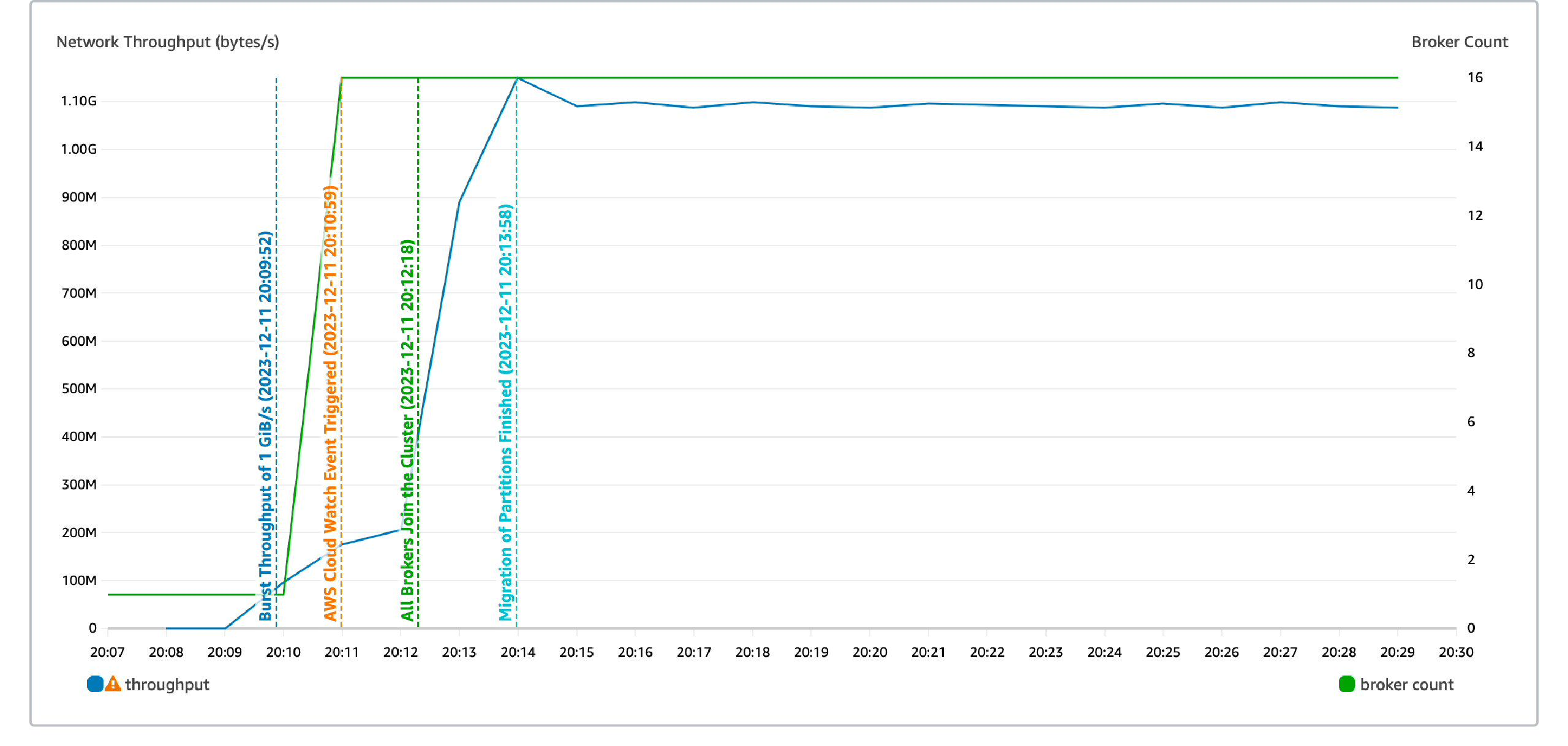
The cluster capacity of AutoMQ is typically maintained at 80% using the target tracking strategy of Auto Scaling. In unexpected traffic surge scenarios, the target tracking strategy may fail to meet capacity demands promptly. Auto Scaling provides an emergency strategy that elastically scales the cluster to the target capacity when the cluster water level exceeds 90%.
In this test, the emergency strategy of Auto Scaling scaled the cluster capacity to the target capacity in just 4 minutes:
-
70s: AWS CloudWatch monitoring has a maximum precision of 1 minute. It collects data indicating that the cluster's water level exceeds 90% and triggers an alarm.
-
80s: AWS scales out the nodes to the target capacity in batch mode, and the Broker completes node registration.
-
90s: AutoMQ's Auto Balancing detects traffic imbalance among nodes and completes automatic traffic self-balancing.
-
The cluster capacity meets the requirement of 1 GiB/s, and the send latency returns to the baseline.
Catch-up read is a common scenario in messaging and streaming systems:
-
For messaging, messages are often used for decoupling and smoothing traffic spikes between services. Smoothing traffic spikes requires the message queue to buffer the data sent by upstream services, allowing downstream services to consume slowly. In this case, the downstream services are reading catch-up data, which is cold data not in memory.
-
For streaming, periodic batch processing tasks need to start scanning and computing data from several hours or even a day ago.
-
Additional failure scenarios include a consumer crashing and being offline for several hours before coming back online, and consumer logic issues that, once fixed, require replaying historical data.
Catch-up reads mainly focus on two points:
-
Speed of catch-up reads: The faster the catch-up read speed, the quicker the consumer can recover from failure, and the quicker batch processing tasks can produce analytical results.
-
Isolation of reads and writes: Catch-up reads should ideally not affect the production rate and latency.
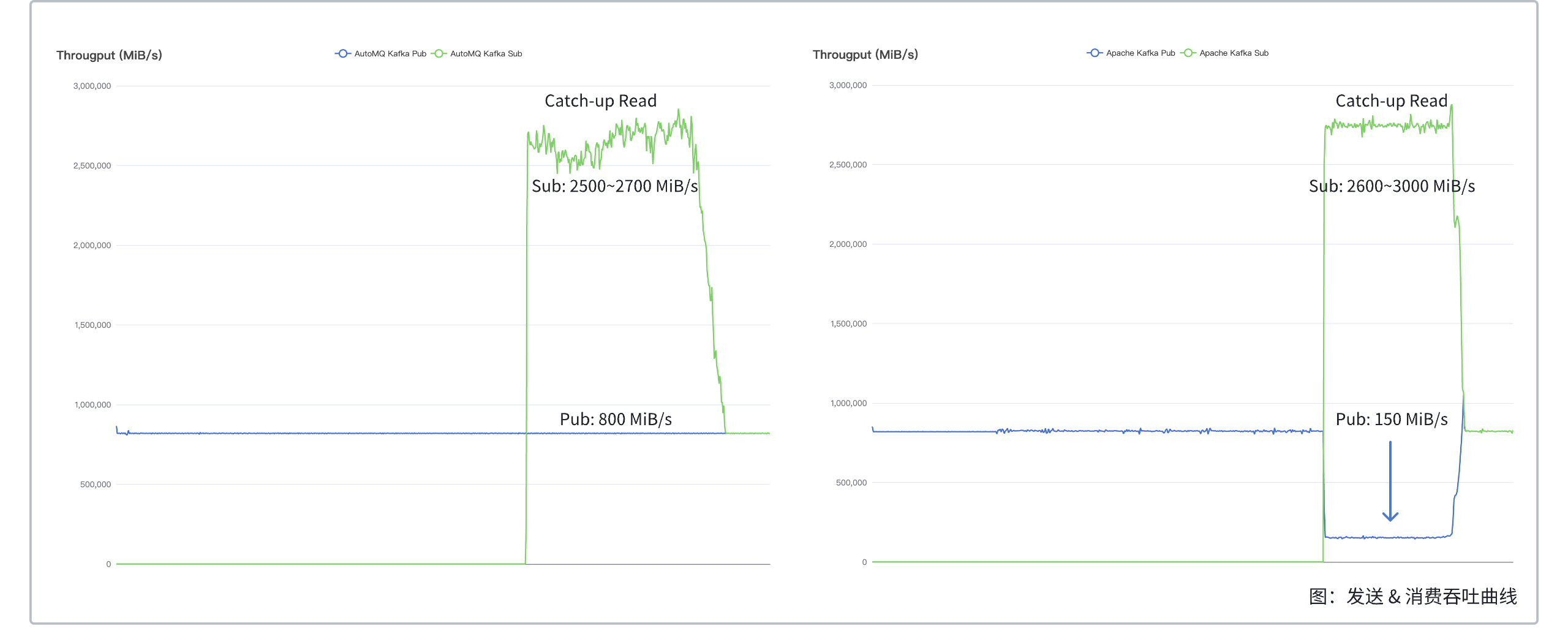
200x efficiency improvement: AutoMQ’s read-write separation compared to Apache Kafka in catch-up read scenarios reduces the send latency from 800ms to 3ms and catch-up time from 215 minutes to 42 minutes.
This test measures the catch-up read performance of AutoMQ and Apache Kafka under the same cluster scale. The test scenario is as follows:
-
A cluster deployment of 20 Brokers, creating a Topic with 1000 partitions.
-
Continuously send data at a throughput of 800 MiB/s.
-
After sending 4 TiB of data, start the consumer to consume from the earliest offset.
Apache Kafka® attaches an additional 1000GB 156MiB/s gp3 EBS to each broker for data storage.
Driver files: apache-kafka-driver.yaml, automq-for-kafka-driver.yaml
Workload files: catch-up-read.yaml
AutoMQ installation configuration file: catch-up-read.yaml
| Comparison Item |
Latency during catch-up read |
Impact on send throughput during catch-up read |
Peak throughput during catch-up read |
|---|---|---|---|
| AutoMQ |
Less than 3ms |
Read-write isolation, maintains 800 MiB/s |
2500 ~ 2700 MiB/s |
| Apache Kafka |
Approximately 800ms |
Mutually affecting, dropping to 150 MiB/s |
2600 to 3000 MiB/s (at the cost of write throughput) |

-
With the same cluster size, during catch-up reads, AutoMQ's send throughput remains unaffected, whereas Apache Kafka's send throughput drops by 80%. This is because Apache Kafka reads from disk during catch-up reads and lacks IO isolation, which occupies AWS EBS read/write bandwidth, reducing write bandwidth and consequently send throughput. In contrast, AutoMQ separates read and write operations; during catch-up reads, it reads from object storage rather than disk, thereby not occupying read/write bandwidth and not affecting send throughput.
-
With the same cluster size, during catch-up reads, AutoMQ's average send latency increases by approximately 0.4 ms compared to sending only, while Apache Kafka's latency soars by approximately 800 ms. The reasons for the increased send latency in Apache Kafka are twofold: firstly, as previously mentioned, catch-up reads occupy AWS EBS read/write bandwidth, leading to reduced write throughput and increased latency; secondly, reading cold data from the disk during catch-up reads pollutes the page cache, similarly increasing write latency.
-
It is worth noting that during catch-up reads of 4 TiB data, AutoMQ took 42 minutes, while Apache Kafka took 29 minutes. The shorter duration for Apache Kafka is due to two factors:
-
During catch-up reads, Apache Kafka's send throughput drops by 80%, reducing the amount of data it needs to catch up.
-
Apache Kafka lacks IO isolation, sacrificing send throughput to improve read throughput.
Assuming Apache Kafka had IO isolation, i.e., performing reads while ensuring send throughput as much as possible, the calculation is as follows:
-
Assuming that the send rate of Apache Kafka® during a catch-up read is 700 MiB/s, considering the three-replica write takes up EBS bandwidth of 700 MiB/s * 3 = 2100 MiB/s.
-
The total EBS bandwidth in the cluster is 156.25 MiB/s * 20 = 3125 MiB/s.
-
The bandwidth available for reading is 3125 MiB/s - 2100 MiB/s = 1025 MiB/s.
-
In a scenario where reading and sending occur simultaneously during a catch-up read, reading 4 TiB of data would take 4 TiB * 1024 GiB/TiB * 1024 MiB/GiB / (1025 MiB/s - 700 MiB/s) / 60 s/min = 215 min.
Apache Kafka® would need 215 minutes to catch up and read 4 TiB of data without significantly impacting the send operations, which is 5 times longer than AutoMQ.
-
The cost of Kafka primarily consists of computation and storage. AutoMQ has theoretically optimized these two aspects to achieve the lowest cloud costs, resulting in a 10x cost saving compared to Apache Kafka®:
-
Computation
-
Spot instances save up to 90%: AutoMQ benefits from broker statelessness, enabling large-scale use of spot instances to save on single-node computing costs.
-
High durability with EBS multi-replica saves up to 66%: AutoMQ ensures high data durability through EBS multi-replicas. Compared to ISR triple-replica, computing instances can perform up to 3x more efficiently.
-
Auto Scaling: AutoMQ uses target tracking policies to scale the cluster in real-time according to cluster traffic.
-
-
Storage
- Object storage saves up to 93%: AutoMQ stores almost all data in object storage, saving up to 93% on storage costs compared to triple-replica EBS.
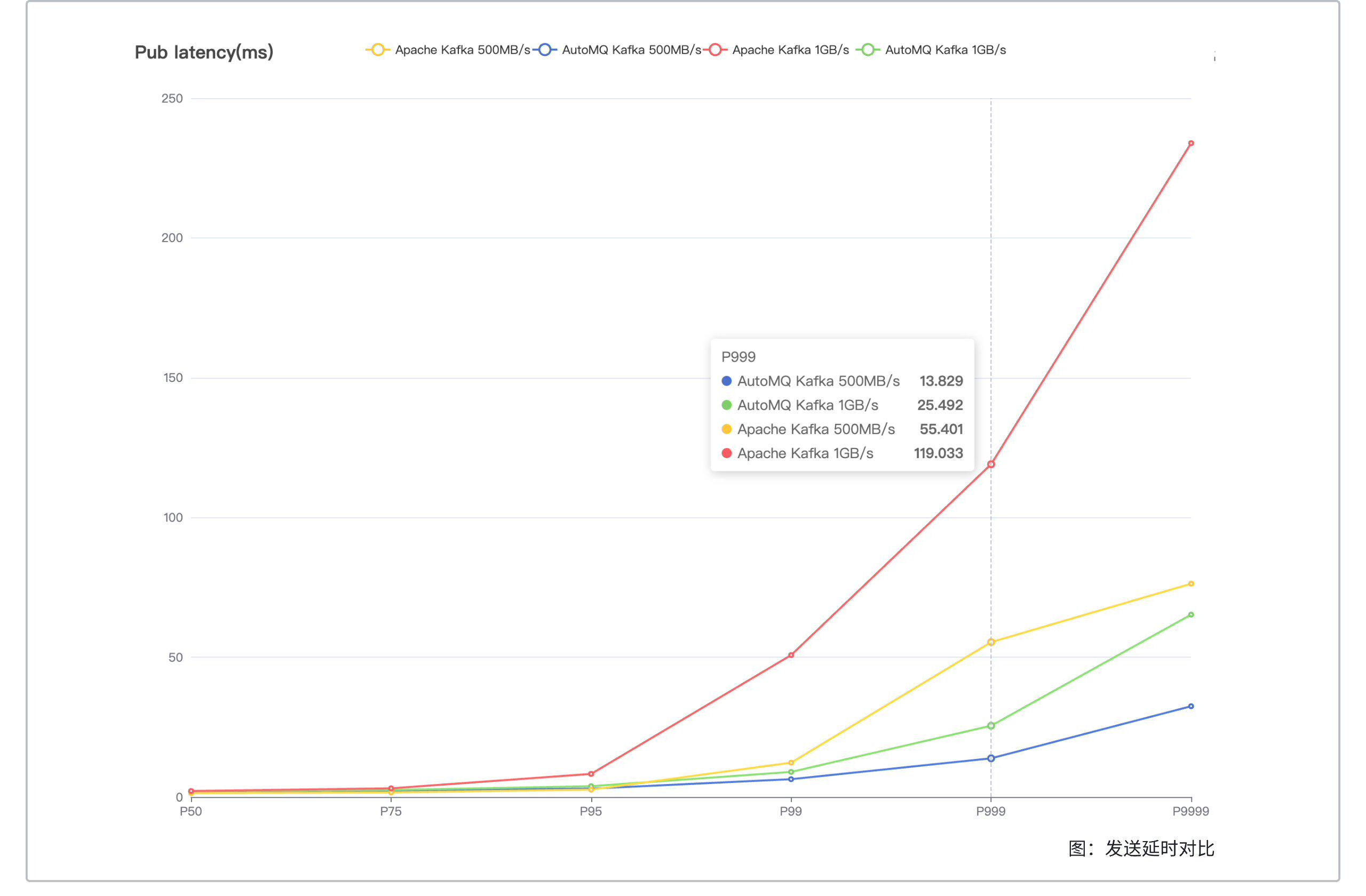
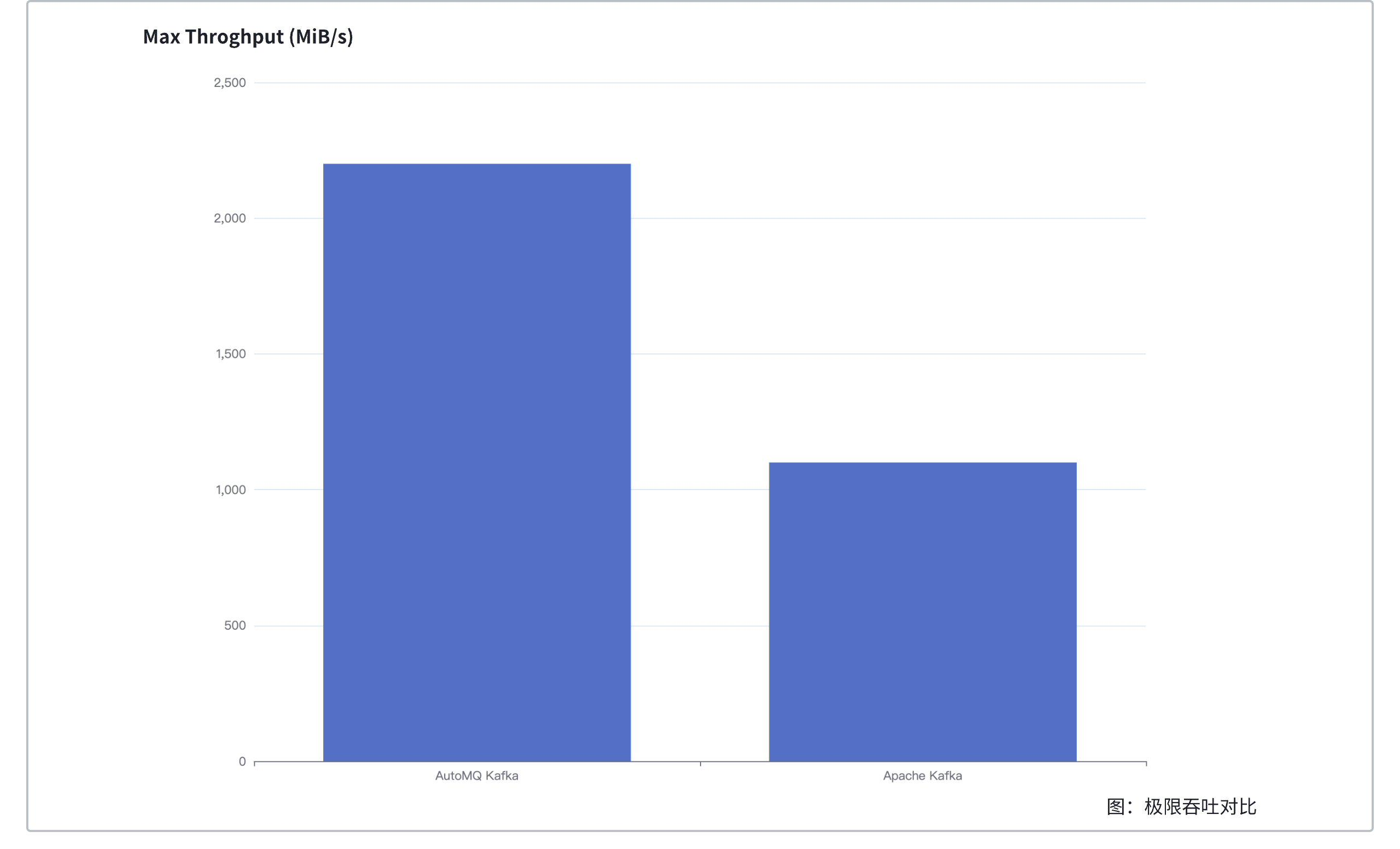
AutoMQ's maximum throughput is 2x that of Apache Kafka, with P999 send latency being 1/4 of Apache Kafka's.
This test measures the performance and throughput limits of AutoMQ and Apache Kafka under the same cluster size but different traffic scales. The test scenarios are as follows:
-
Deploy a cluster with 23 Brokers and create a Topic with 1000 partitions.
-
Initiate 500 MiB/s and 1 GiB/s of 1:1 read-write traffic; additionally, test the maximum throughput for both (AutoMQ 2200 MiB/s, Apache Kafka 1100 MiB/s).
Each Apache Kafka broker additionally mounts a 500GB 156MiB/s gp3 EBS for data storage.
Driver files: apache-kafka-driver.yaml, automq-for-kafka-driver.yaml
Workload files: tail-read-500m.yaml, tail-read-1024m.yaml, tail-read-1100m.yaml, tail-read-2200m.yaml
AutoMQ installation configuration file: tail-read.yaml
| Comparison Item |
Maximum Throughput |
500 MiB/s Send Latency P999 |
1 GiB/s Send Latency P999 |
|---|---|---|---|
| AutoMQ |
2200 MiB/s |
13.829 ms |
25.492 ms |
| Apache Kafka |
1100 MiB/s |
55.401 ms |
119.033 ms |
Detailed data on transmission latency and E2E latency:
| Pub Latency(ms) |
500 MiB/s |
1 GiB/s |
Throughput Limit |
|||
|---|---|---|---|---|---|---|
| AutoMQ |
Apache Kafka |
AutoMQ |
Apache Kafka |
AutoMQ 2200 MiB/s |
Apache Kafka 1100 MiB/s |
|
| AVG |
2.116 |
1.832 |
2.431 |
3.901 |
5.058 |
4.591 |
| P50 |
1.953 |
1.380 |
2.118 |
2.137 |
3.034 |
2.380 |
| P75 |
2.271 |
1.618 |
2.503 |
3.095 |
3.906 |
3.637 |
| P95 |
2.997 |
2.618 |
3.859 |
8.254 |
9.555 |
10.951 |
| P99 |
6.368 |
12.274 |
8.968 |
50.762 |
37.373 |
60.207 |
| P999 |
13.829 |
55.401 |
25.492 |
119.033 |
331.729 |
134.814 |
| P9999 |
32.467 |
76.304 |
65.24 |
233.89 |
813.415 |
220.280 |
| E2E Latency(ms) |
1 GiB/s |
Throughput Limit |
||
|---|---|---|---|---|
| AutoMQ |
Apache Kafka |
AutoMQ 2200 MiB/s |
Apache Kafka 1100 MiB/s |
|
| AVG |
4.405 |
4.786 |
6.858 |
5.477 |
| P50 |
3.282 |
3.044 |
4.828 |
3.318 |
| P75 |
3.948 |
4.108 |
6.270 |
4.678 |
| P95 |
10.921 |
9.514 |
12.510 |
11.946 |
| P99 |
26.610 |
51.531 |
34.350 |
60.272 |
| P999 |
53.407 |
118.142 |
345.055 |
133.056 |
| P9999 |
119.254 |
226.945 |
825.883 |
217.076 |
- Under the same cluster size, AutoMQ's maximum throughput is twice that of Apache Kafka.
AutoMQ ensures high data durability through multiple replicas based on EBS, without unnecessary replication at the upper layer, whereas Apache Kafka ensures data durability through ISR with three replicas. Assuming no CPU and network bottlenecks, both AutoMQ and Apache Kafka fully utilize disk bandwidth, and AutoMQ's theoretical throughput limit is three times that of Apache Kafka.
In this test, AutoMQ's CPU usage is higher than Apache Kafka's due to the need to upload data to S3, causing AutoMQ to hit the CPU bottleneck first. With 23 r6in.large instances, the total disk bandwidth limit is 3588 MB/s. Apache Kafka's theoretical maximum throughput with three replicas is 1196 MB/s, causing Apache Kafka to hit the disk bottleneck first. Ultimately, the maximum throughput tested shows AutoMQ is twice that of Apache Kafka.
- Under the same cluster size and traffic (500 MiB/s), AutoMQ's P999 send latency is one-fourth of Apache Kafka's. Even at double the traffic (500 MiB/s to 1024 MiB/s), AutoMQ's P999 send latency is still half of Apache Kafka's.
-
AutoMQ uses Direct IO to bypass the file system and write directly to EBS raw devices, eliminating file system overhead and providing more stable sending latency.
-
Apache Kafka uses Buffered IO to write data to the page cache. Once the data is in the page cache, it is considered successfully written, and the operating system flushes dirty pages to the hard drive in the background. File system overhead, consumer cold reads, and page cache misses can all contribute to sending latency jitter.
When scaled to a throughput of 1 GiB/s, AutoMQ offers up to 20x computational cost savings and 10x storage cost savings compared to Apache Kafka.
-
Computation: AutoMQ uses EBS solely as a write buffer for S3, uploading data to S3 during shutdown within 30 seconds. Therefore, AutoMQ can fully leverage Spot instances, which are up to 90% cheaper than On-Demand instances. Combined with AutoMQ's per-node throughput being twice that of Apache Kafka, AutoMQ can achieve up to 20x computational cost savings compared to Apache Kafka.
-
Storage: Almost all data in AutoMQ is stored in S3, which charges based on the actual data stored. Apache Kafka, on the other hand, stores data with three hard drive replicas and typically reserves at least 20% additional hard drive space in production environments. This results in AutoMQ offering storage cost savings of up to 1 / (S3 unit price 0.023 / (3 replicas * 0.08 EBS unit price / 0.8 hard drive utilization)) = 13x compared to Apache Kafka. Adding the cost of S3 API calls, AutoMQ ultimately offers up to 10x storage cost savings compared to Apache Kafka.
Additionally, in extreme throughput tests, Apache Kafka maxes out hard drive bandwidth. In production environments, additional hard drive bandwidth must be reserved for partition reassignments and cold data catch-up reads, resulting in a lower write utilization limit. In contrast, AutoMQ reads catch-up data from S3 using network bandwidth, enabling a separation of read and write operations. This allows all hard drive bandwidth to be dedicated to writes, with the production write utilization limit matching that of the tests.
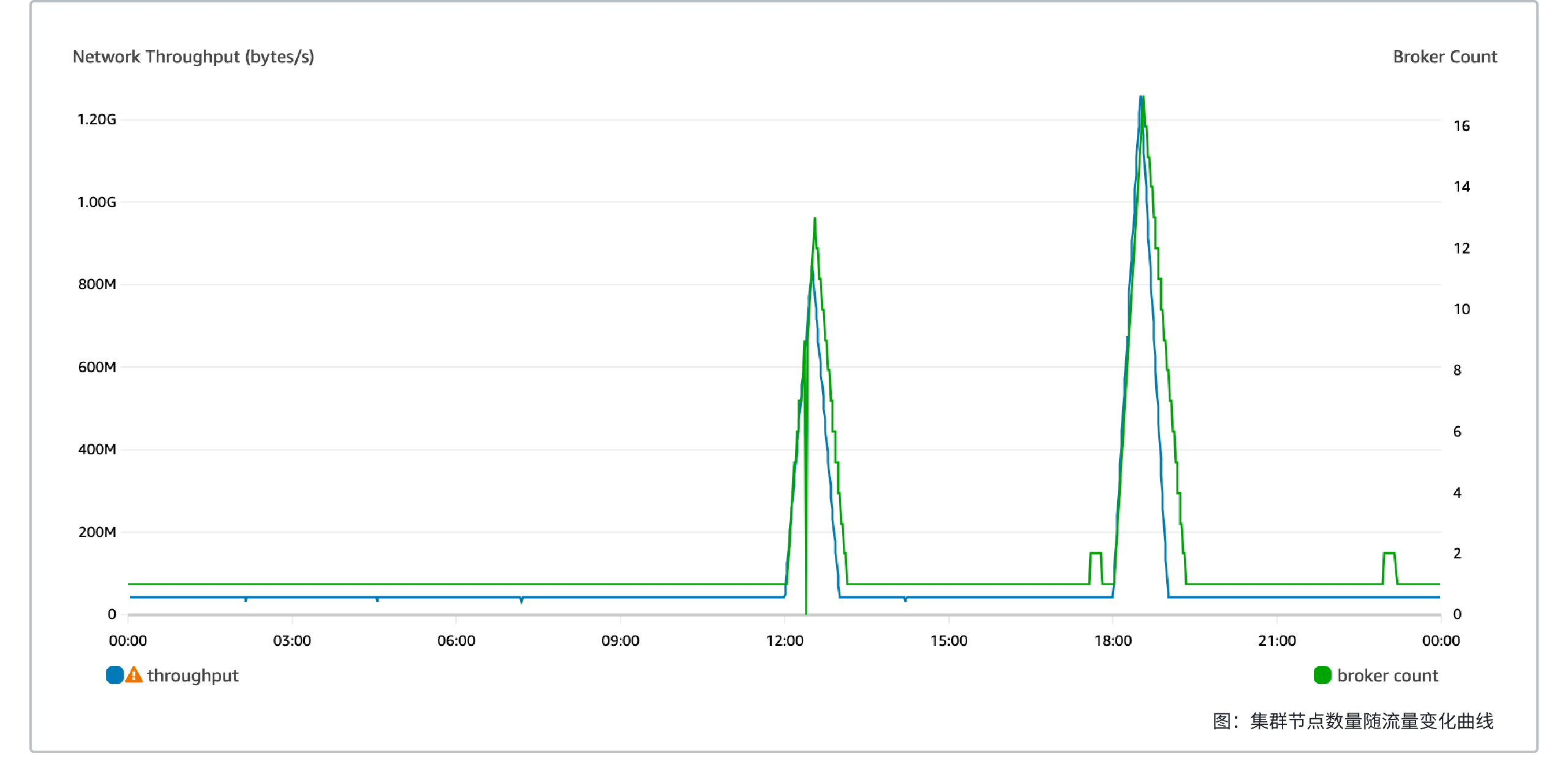
With up to 11x extreme cost savings, AutoMQ fully utilizes Auto Scaling and object storage to achieve true pay-per-use for both computation and storage.
This test simulates production peak and valley loads, measuring the cost and performance of AutoMQ under an Auto Scaling target tracking policy. The test scenario is as follows:
-
Install the cluster on AWS using the AutoMQ Installer.
-
Create a Topic with 256 partitions and a retention time of 24 hours.
-
Perform load testing with dynamic traffic at a 1:1 read/write ratio as follows:
-
Steady traffic at 40 MiB/s.
-
Traffic increases from 12:00 to 12:30 to 800 MiB/s, and returns to 40 MiB/s by 13:00.
-
Traffic increases from 18:00 to 18:30 to 1200 MiB/s, and returns to 40 MiB/s by 19:00.
-
Driver files: apache-kafka-driver.yaml, automq-for-kafka-driver.yaml
Load file: auto-scaling.yaml
AutoMQ installation configuration file: auto-scaling.yaml
Cost comparison between AutoMQ and Apache Kafka under the same workload:
| Cost Category |
Apache Kafka (USD / month) |
AutoMQ (USD / month) |
Multiplier |
|---|---|---|---|
| Compute |
3,054.26 |
201.46 |
15.2 |
| Storage |
2,095.71 |
257.38 |
8.1 |
| Total |
5,149.97 |
458.84 |
11.2 |
This test was conducted on AWS East Coast with a cost bill calculated on a pay-as-you-go basis for both compute and storage:
-
Compute: Compute nodes dynamically scale in and out based on cluster traffic under the Auto Scaling target tracking policy, maintaining the cluster utilization at 80% on a minute-level basis (AWS monitoring alerts progress on a minute-level basis, with monitoring delays resulting in a tracking accuracy of around 2 minutes).
-
Storage: Most of the data is stored on S3, with storage costs primarily consisting of S3 storage fees and S3 API call fees. S3 storage fees are positively correlated with the amount of data written and the duration of data retention, while S3 API call fees are positively correlated with the amount of data written. Both S3 storage fees and S3 API call fees are billed on a pay-as-you-go basis.
If using Apache Kafka® to build a three-replica cluster to handle a daily peak traffic of 1 GiB/s, under the same traffic model, Apache Kafka® would cost at least the following per month:
-
Compute: Difficulty in dynamic scaling requires preparing capacity for peak traffic, with Broker costs calculated as r6in.large at a rate of $0.17433 per hour * 730 hours per month * 23 instances = $2927.00.
-
Storage:
-
Storage costs: (total data volume 6890.625 GB x 3 replicas / 80% disk utilization) x EBS rate $0.08/GB per month = $2067.19.
-
Storage bandwidth costs: Bandwidth rate $0.04/MB x additional purchased bandwidth 31MB/s x 23 EBS volumes = $28.52.
-
| Cost Category |
Apache Kafka (USD / month) |
AutoMQ (USD / month) |
Multiplier |
|
|---|---|---|---|---|
| Compute |
Controller |
127.26 |
127.26 |
1.0 |
| Broker |
2,927.00 |
74.20 |
39.4 |
|
| Total |
3,054.26 |
201.46 |
15.2 |
|
| Storage |
EBS Storage |
2,067.19 |
0.43 |
- |
| EBS Throughput |
28.52 |
- |
- |
|
| S3 Storage |
- |
158.48 |
- |
|
| S3 API |
- |
98.47 |
- |
|
| Total |
2,095.71 |
257.38 |
8.1 |
|
| Total |
5,149.97 |
458.84 |
11.2 |
|
This benchmark demonstrates the significant optimizations AutoMQ achieves in efficiency and cost savings after reshaping Kafka for the cloud:
-
100x Efficiency Improvement:
-
In partition reassignment scenarios, AutoMQ reduces the 30GB partition reassignment time from Apache Kafka's 12 minutes to just 2.2 seconds, achieving a 300x efficiency improvement.
-
With extreme elasticity, AutoMQ can automatically scale-out from 0 to 1 GiB/s in just 4 minutes to meet the target capacity.
-
In historical data catch-up read scenarios, AutoMQ's read-write separation optimizes average send latency by 200x, reducing it from 800ms to 3ms, and catch-up read throughput is 5 times that of Apache Kafka.
-
-
10x Cost Savings:
-
At a fixed scale, AutoMQ's throughput ceiling reaches up to 2200 MiB/s, which is double that of Apache Kafka. Additionally, the send time P999 is only 1/4 that of Apache Kafka.
-
In dynamic load scenarios ranging from 40 MiB/s to 1200 MiB/s, AutoMQ's auto-scaling feature saves a significant amount of computing resources during off-peak periods. Real-world tests show that AutoMQ achieves an 11x reduction in billing costs compared to Apache Kafka.
-
- AutoMQ supports instances using AWS Graviton, and the performance comparison results are also applicable to Graviton-supported instances.