How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
Author: Wang Jinlong, Zhihu Online Architecture Team
Zhihu, established on August 10, 2010 and officially launched on January 26, 2011, is a high-quality Q&A community and original content platform within the Chinese internet.
Zhihu began as a Q&A platform, but it has evolved beyond that. With a strategy focused on "ecology first" and a core positioning in "professional discussions", Zhihu has built an inclusive and vibrant community ecosystem. It covers a variety of products and features, including trending topics, Zhihu Direct Answers, ideas, Salt Talks stories, Zhihu Knowledge College, and content commercialization solutions, providing diverse and rich experiences for users, creators, and business partners.
Based on its deep accumulation in the application layer and data layer, Zhihu has always been at the forefront of technological innovation. It has formed R&D and application advantages in NLP, artificial intelligence, and large Chinese language models, and has successively launched the "Intelligent Community", "Zhuhai AI" large model, Zhihu Direct Answers and other technical strategies and products, continuously empowering the community ecosystem and user experience.
We previously partitioned the message queue resource pool based on the bare metal machines provided by cloud vendors. In scenarios where business traffic increases, Kafka nodes responsible for hot spot traffic can quickly bring the disk space of storage nodes to the watermark. At this point, it is necessary to scale up the storage resource pool.
Two issues arose during the scaling process:
-
Data balancing is required for the storage resource pool: During this process, a significant amount of data needs to be relocated within the resource pool, which is time-consuming and incurs substantial operational costs. The data migration process triggers a large number of cold data reads, and due to the limitations of Kafka's native storage model, data from a single partition can only be stored on one disk. During data migration, a significant amount of disk bandwidth is consumed, resulting in over 10-second write latency due to the inability to utilize sufficient disk bandwidth for new message entries. Simultaneously, massive historical data read requests lead to frequent Page Cache misses. Normal business traffic also frequently reads from the disk, further contending for disk bandwidth, resulting in a large accumulation of consumer backlog. Data migration operations significantly impact the cluster's read-write latency and overall stability.
-
Idle compute resources in storage resource pool: Kafka, being an IO-intensive storage middleware, does not make compute resources the primary bottleneck of the resource pool. Although isolation of the resource pool enhances service stability, it also raises new challenges in how to make full use of the remaining compute resources.
In the face of large-scale sudden traffic, as a service maintenance party, it's essential to ensure service stability. **There are generally two ways to address this: **
-
**Method 1: ** Rapidly scale up resources and disperse the hotspot partitions onto new machines.
-
**Method 2: ** Pre-allocate additional resources to ensure sufficient cluster capacity during peak business traffic.
**Each choice also generates new issues: **
-
**Method 1: ** Under Kafka's native architecture model, Method 1 requires data migration when scaling up nodes, which may miss the window of sudden traffic by the time migration is completed. It does not provide a more stable message queue service effectively.
-
**Method 2: ** Method 2, by reserving more extra resources in the resource pool, can ensure business stability. However, it may lead to lower utilization of the resource pool, thus increasing the technical costs for the company.
- Low Resource Cost & Low Operational Cost & High Resource Utilization Rate:
Separation of storage and compute allows for flexible, on-demand configuration of computing and storage resources. Ideally, it should operate like a stateless service, leveraging a unified resource pool of the company, eliminating the need to maintain a separate storage resource pool. This approach reduces overall resource pool redundancy and enhances its utilization rate. Ideally, it should also eliminate operational costs introduced by data migration.
- Elastic Service Capabilities:
Our service can rapidly scale under high traffic loads, providing increased capacity. Once traffic peaks subside, corresponding resources are released to further minimize costs. Moreover, the time taken for expansion is kept as short as possible to avoid missing traffic surges due to slow data migration.
- Low Migration Cost & High Stability & High Compatibility:
The company heavily relies on the Kafka API for asynchronous link communication, online business decoupling, recommendation effect log burying, data sample concatenation, and many other scenarios. Switching to another messaging middleware would require changing the SDK interface, which would considerably increase human resource costs during the migration. We hope to enable business departments to migrate without having to modify any code.
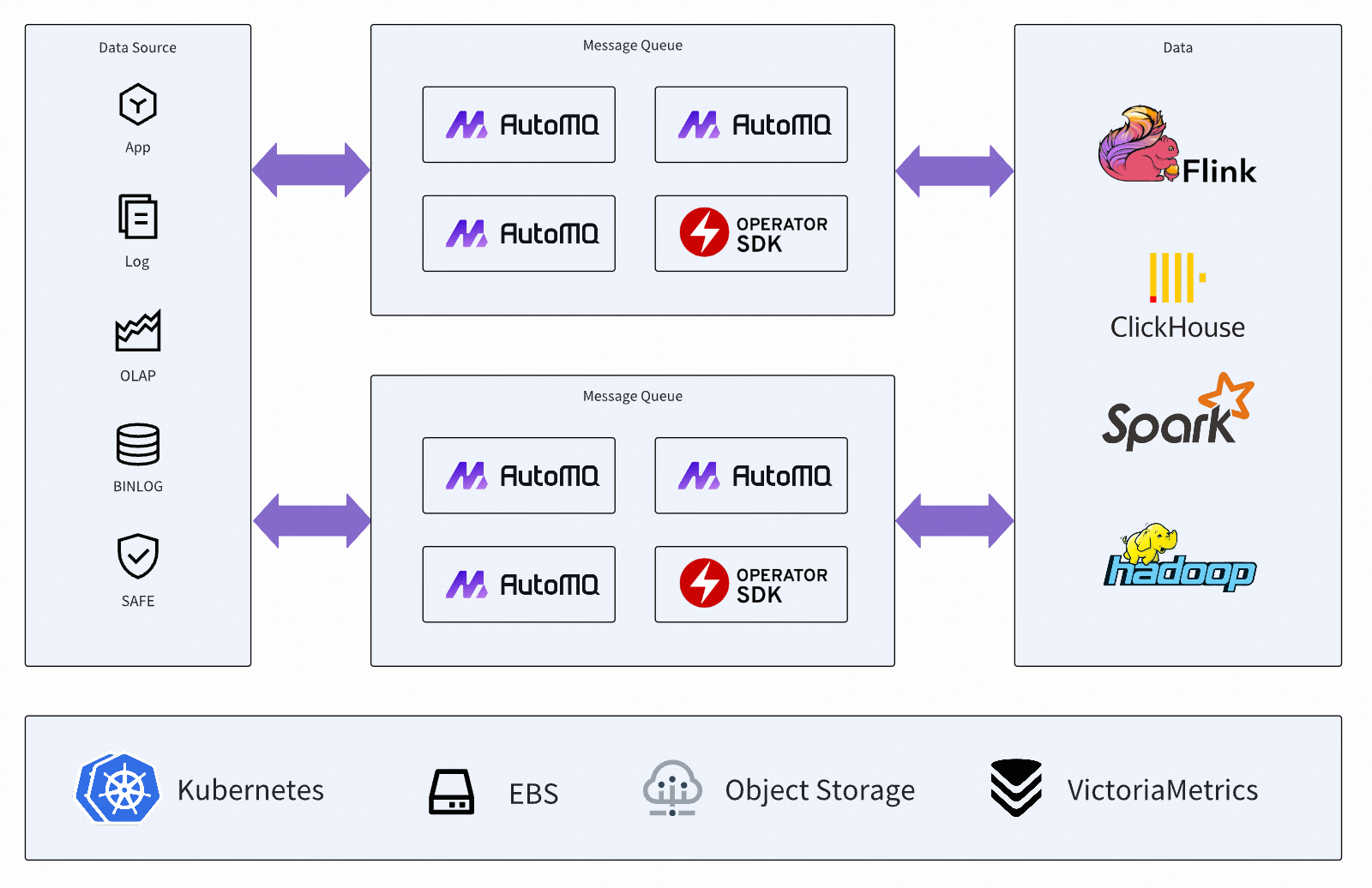
AutoMQ fully leverages the storage infrastructure provided by cloud vendors, implementing storage-compute separation for native Kafka, significantly reducing Kafka's resource and operation costs. AutoMQ, based on the service capabilities offered by EBS cloud disks and object storage, presents a next-generation message middleware that provides low-latency, high-throughput massive data storage to the outside world.
-
The significant cost benefits brought by the separation of storage and computation:
-
Upper-layer applications are no longer tightly bound to storage resource machines, eliminating the need for operations like data migration on storage nodes, significantly reducing cluster operation costs.
-
Existing resource pools can be configured with computational machines, relying on stable storage services provided by cloud vendors, without the need for additional storage resources, markedly reducing the cost of the message queue resource pool.
-
By fully utilizing object storage, higher scale storage bandwidth can be provided at a lower cost compared to self-built storage.
-
-
Empowering storage services with more flexible elasticity capabilities:
-
Cloud-native Compatibility: Transforming Kafka into an almost stateless service allows for full utilization of the standard capabilities provided by existing K8s infrastructure, significantly reducing operational costs.
-
Cluster scaling in seconds: AutoMQ's innovative architecture breaks down the responsibilities of Kafka's partition's data master nodes, retaining computational logic such as data reading and writing, and sinking storage logic to the self-developed S3Stream[1] architecture. This distributes underlying data flexibly across EBS cloud disks and object storage. Scaling actions do not require data migration; triggering partition migration to newly expanded nodes in the cluster Meta node can complete hotspot partition shuffling. The migration process has no loss of traffic and is transparent and unimpactful to the business.
-
-
100% Compatibility with Standard Kafka API:
-
Businesses need not modify their existing codes, and service maintenance teams are exempted from maintaining Kafka API compatibility layers, saving unnecessary manpower costs caused by service migration.
-
With seamless compatibility with the native Kafka ecosystem, you can directly reuse the company's existing Kafka peripheral infrastructure, thereby avoiding redundant construction.
-
After being deployed on a large scale at Zhihu, AutoMQ achieved the following results:
-
**Cost reduction of 80%: ** Thanks to the elastic architecture of AutoMQ and the full leverage of the cost advantages of object storage, in the business scenarios that have been deployed, the cluster cost of AutoMQ has been reduced by 80% compared to the original Apache Kafka.
-
**No need for independent storage and computing resource pools: ** With the stateless feature of AutoMQ nodes, the resource pool of AutoMQ clusters can be switched in minutes, eliminating the need for independent static storage machine resource pools, further reducing resource waste.
-
**Higher cold read bandwidth & elimination of side effects of cold read/write: ** Object storage can provide higher read bandwidth than the original disk-based Kafka cluster, and cold reading does not affect the real-time write traffic of the cluster. This further improves the stability of the service.
-
**Stateless architecture significantly reduces operation and maintenance costs: ** With regular monitoring, there are no additional operation and maintenance costs. AutoMQ's automatic load balancing capability, combined with Zhihu's self-developed K8s control plane, reduces the need for manual involvement in operations.
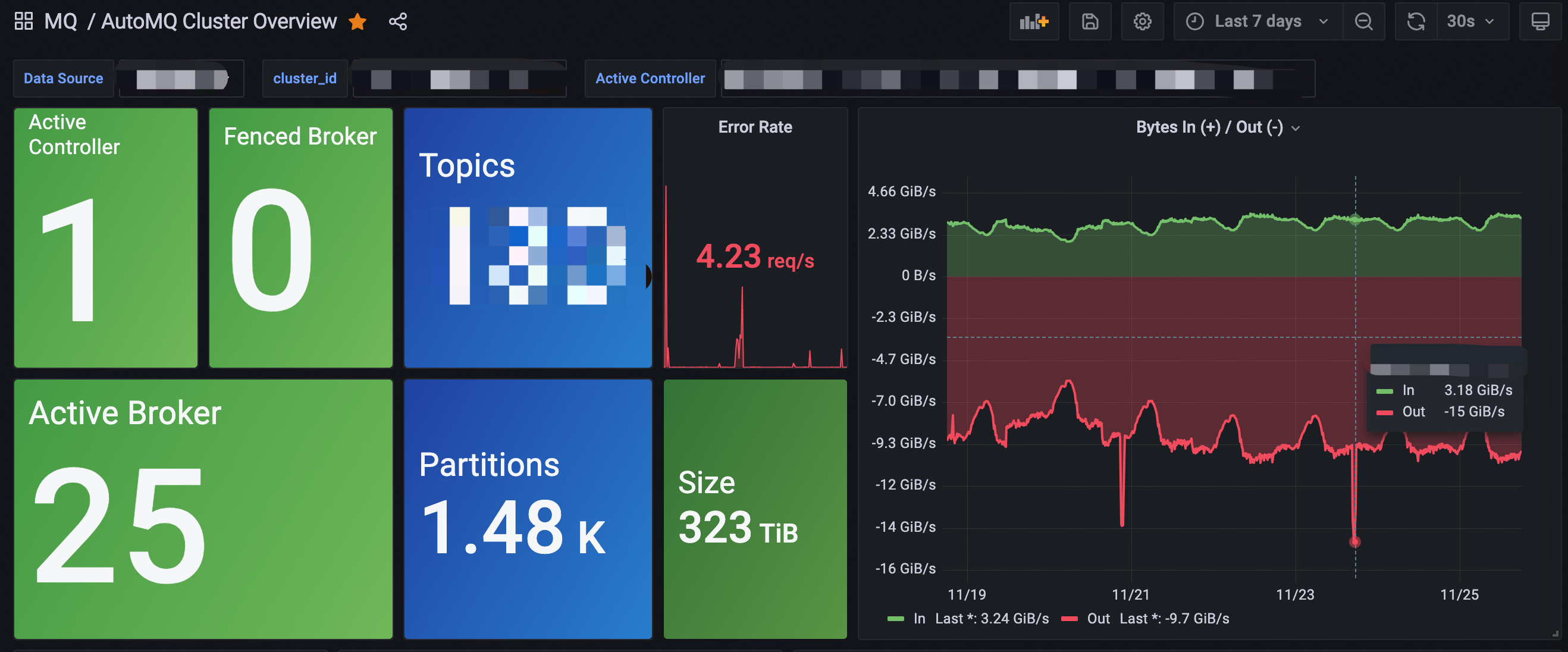
Currently, Zhihu has deployed AutoMQ on a large scale on its bare-metal self-built K8s cluster, with the peak traffic load of the cluster nearing 20 GiB/s, as shown in the figure below.
[1] AutoMQ Shared Stream Storage based on S3:https://docs.automq.com/automq/architecture/s3stream-shared-streaming-storage/overview
[2] AutoMQ Cold-Hot Isolation Architecture & 5x Efficiency Improvement in Cold Reading:https://docs.automq.com/automq/architecture/technical-advantage/5x-catch-up-read-efficiency