AutoMQ Kafka: 10x Cost Efficiency via AWS Auto Scaling
As cloud computing technology continues to evolve and the concept of cloud-native becomes more ingrained, a variety of foundational deployment models continually emerge. Despite being a relatively "traditional" cloud technology concept, Auto Scaling Groups may still be unfamiliar to many. Today, we talked about this foundational product that has grown alongside cloud computing, using AWS, the pioneer of cloud computing, as an example.
Elastic Scaling Group is a category of cloud products introduced in the late stages of IaaS infrastructure development. Similar to Kubernetes (k8s), where elastic scaling based on containers is not a novel concept, Elastic Scaling Group can be understood as a product designed to address the need for dynamic scaling based on cloud virtual machines. AWS launched the EC2 product in August 2006. Due to the inherent need for dynamic scaling, various third-party elastic scaling software emerged starting from April 2008, including Scalr and RightScale. On May 18, 2009, AWS introduced its own elastic scaling feature [1].
In summary, the primary aim of Elastic Scaling Group is to address the demand for variable traffic, and its core concepts can be broken down into two parts: "elastic scaling" and "group."
Focusing on "elastic scaling" and "group," the main functions of the Elastic Scaling Group can be divided into two major parts:
The core resource in managing an auto-scaling group remains our compute nodes. Essentially, an auto-scaling group is a node group that manages a set of homogeneous or heterogeneous nodes. Proper node management is naturally the fundamental capability of this product. AWS has defined several basic concepts around node management:
- Launch Template
To address the need for flexible scaling up and down, it is essential to support the quick addition and removal of nodes. Since nodes grouped together inevitably share some commonalities, a template that enables the quick creation of nodes is the best choice. AWS launch templates support the configuration of most EC2 parameter attributes, providing a foundational attribute template for the auto-scaling group.
- Desired, Maximum, Minimum Counts

When manually managing node capacity, users can set a desired node count to control the number of nodes. When the actual number of nodes does not equal the desired count, the auto-scaling group will automatically create and terminate nodes to match the desired count.
When using an automatic elastic strategy, it essentially controls scaling by adjusting the desired quantity.
The maximum and minimum quantities serve as constraints to limit the range of the desired quantity, preventing issues such as low cluster watermarks or high server costs.
- Health Check
The premise for adjusting the desired quantity is that the nodes are in a 'healthy' state. For 'unhealthy' nodes, the elastic scaling group will replace them to ensure that all nodes in the group are healthy and able to provide normal services.
There are generally two methods to identify whether a node is in a healthy state.
-
When configuring a load balancer, its health check determines the health status of the nodes.
-
The health status of the nodes can be manually set through the API, which is often suitable for custom health check logic.
-
Machine type management policy
A highly available cluster typically requires service nodes across multiple availability zones. However, due to differences in inventory and instance types across these zones, it is challenging to pre-configure an instance type to fit all availability zones. This necessitates more intelligent strategies for managing instance types.
AWS provides two methods for managing instance types:
-
Manual instance configuration: Manually specify several instance types and select the ones with sufficient inventory based on certain rules.
-
Priority Mode: Select the first available model with sufficient stock based on configuration order.
-
Price Priority Mode: Select the model with the lowest price among those with sufficient stock.
-
-
Auto Model Filtering: Configure CPU cores, memory, and other metrics to dynamically filter suitable models.
- Scheduled Policy
When an application's traffic exhibits distinct periodic characteristics, a scheduled policy can be used to achieve periodic scaling up and scaling down.
- Metrics-Based Automatic Scaling Policy
Based on monitoring metrics provided by the cloud, automatic scaling up is triggered as metrics rise, and automatic scaling down is triggered as metrics fall.
- Cooldown Period
Frequent changes to the number of clusters do not improve the quality of the service; instead, they can lead to cluster instability. To prevent such issues, a cooldown period is enforced to implement a minimum change interval.
In addition to the basic capabilities mentioned above, AWS Auto Scaling also offers advanced features to provide a better experience.
When performing state transitions within the group nodes, users can incorporate custom logic to execute additional operations during the node state switch, such as resource initialization or cleanup.
There are several main ways to implement custom operations:
-
Using cloud-init to execute custom scripts—this method, strictly speaking, does not fall under the concept of lifecycle hooks and can only operate during the startup cycle. However, it is one of the simplest available solutions for implementing custom operations.
-
Using Lambda services to achieve custom operations by listening to EventBridge events, which trigger the configured Lambda actions.
-
Using self-developed programs to listen for SNS or SQS events, which then execute custom program workflows.
Custom operations generally have a configured timeout period, allowing users to define the operation’s behavior upon timeout. Therefore, after executing custom programs, it is necessary to call the AWS API to notify the Auto Scaling group that the lifecycle hook logic is complete.
To enhance the agility of node scaling, AWS introduced the concept of a Warm Pool, separate from the nodes in the Auto Scaling group, aimed at minimizing the warm-up time required for nodes to be ready for service and improving responsiveness to sudden capacity demands.
Nodes within a Warm Pool can be in three states:
-
Stopped: Nodes are in a shut-down state to save the time needed for node creation.
-
Hibernated: The node's memory state is saved to disk as a snapshot, reducing boot time even further.
-
Running: The node is in a running state and can almost instantly join the elastic scaling group, be added to load balancing, and provide services (of course, if lifecycle hooks are set, there is additional time for executing custom logic). Naturally, you must also pay the full node operation costs.
When basic instance metrics cannot accurately describe a node's service capability, AWS allows users to set weights for specified instance types to represent their relative service capabilities.
For example, both instance type a and b have a configuration of 2 cores and 4GB of memory, but due to other comprehensive metrics and results from stress testing, the service capability of instance type a is twice that of instance type b. In this case, we can set the weight of instance type a to 2 and b to 1. The desired, maximum, and minimum capacity of the elastic scaling group would then represent abstract service capabilities rather than the number of nodes. When a desired value of 8 is specified, using instance type a would require 4 nodes, whereas using instance type b would require 8 nodes. This approach more accurately describes the total service capability or ensures capability balance across multiple availability zones.
Due to AutoMQ's decoupled storage and computation architecture, almost all state information is stored in object storage (with some write-buffer data stored on EBS volumes. The version without EBS, [Direct S3 version][3], has already been released). We can consider that nodes can be terminated and replaced at any time. This provides the prerequisite for managing clusters using elastic scaling. As the load varies, elastic scaling can achieve capacity increases or decreases within minutes or even seconds.
When using elastic scaling groups, we differentiate between Kafka controllers and broker nodes by placing them in different scaling groups. Here, we introduce a concept: nodes that serve both controller and broker functions are called server nodes. As the cluster scales, we further segment pure broker nodes into different elastic scaling groups based on their characteristics.
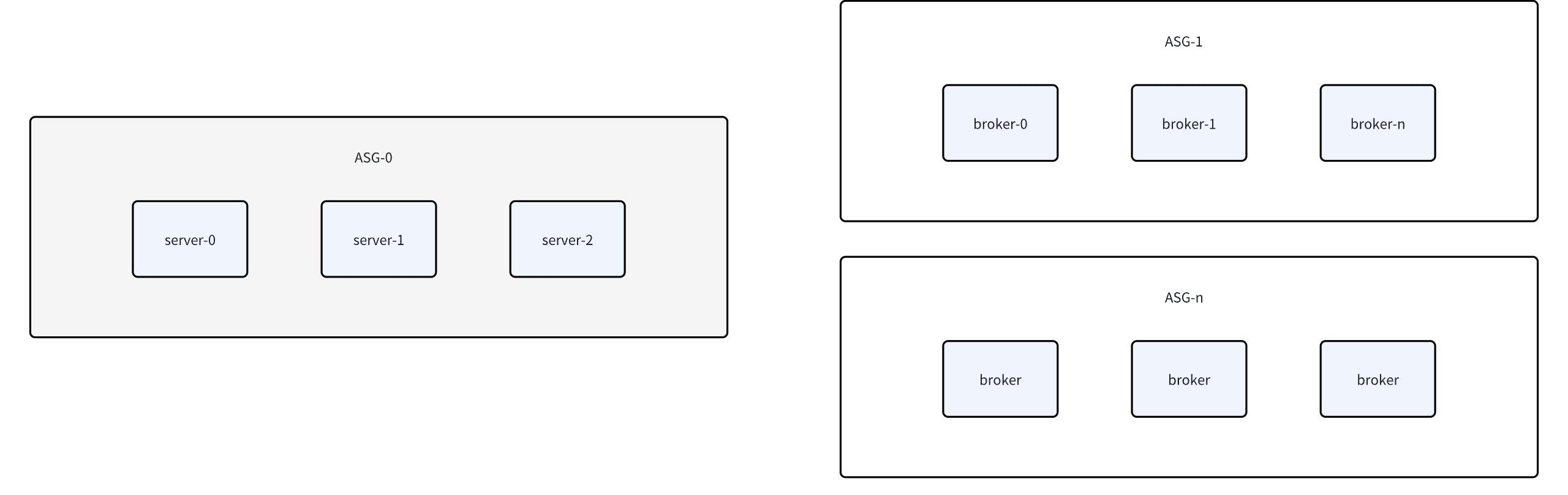
Taking the two types of instances currently used by AutoMQ as an example, both r6in.large and r6i.large are 2-core, 16GB memory instances. However, in actual comprehensive tests, there is a fundamental difference in service capabilities between the two. The service capability of r6in.large can almost be considered twice that of r6i.large. Moreover, their distribution across different regions and availability zones is not uniform. When we choose a high-availability layout across multiple availability zones, it's challenging to balance the service capabilities across these zones.
Therefore, using instance weighting can effectively solve such issues. Setting the weight of r6in.large to be twice that of r6i.large allows us to achieve the same level of service capability with half the number of nodes in the availability zones using r6in.large under a multi-availability zone balancing strategy.
For regular web applications, using the automatic health check of a load balancer is the most efficient method. However, for applications like Kafka, the node health evaluation mechanism is often more complex. Therefore, we need to adopt customized solutions to ensure the health of cluster nodes.
We will conduct health evaluations for nodes based on internal inspections and some additional mechanisms. If a node is found to be in an unhealthy state, we will manually change the node's health status using AWS's health status setting interface. At this point, the auto-scaling group will automatically execute the node replacement operation. Thanks to AutoMQ's stateless architecture, node replacement can be carried out smoothly.
Through lifecycle hooks during node shutdown, we can ensure data integrity and durability under boundary conditions.
As Kafka is primarily used in large data volume and high throughput scenarios, its operational characteristics differ from conventional compute-intensive applications. CPU and memory metrics are not particularly sensitive, and the core metric determining its load is network throughput. Therefore, we need to focus elasticity metrics on the network inbound and outbound bandwidth of the server.
As discussed earlier about the architecture of multiple auto-scaling groups, we also need to utilize a key feature of AWS: using the elasticity metrics of one scaling group to scale another group. For instance, a smaller cluster typically includes only server nodes and is assigned to one scaling group. When traffic volumes reach a certain proportion and the average traffic exceeds the safety threshold, more nodes need to be added. Since the number of server nodes is usually fixed and cannot be increased simply by adding more server nodes to improve the overall cluster's node count, we create two auto-scaling groups during the initialization of the cluster, setting the capacity of the other scaling group to 0. This way, by leveraging the metrics of the server scaling group, we can increase the number of nodes in the other scaling group, thus lowering the average traffic of the entire cluster to a reasonable level.
Today, we briefly introduced the basic concepts of AWS Auto Scaling Groups and how AutoMQ uses Auto Scaling Groups to implement product features. Next, we will delve into how AutoMQ leverages cloud infrastructure. Please stay tuned.