Kafdrop
Kafdrop [1] is a sleek, intuitive, and robust Web UI tool designed for Kafka. It allows developers and administrators to easily view and manage key metadata of Kafka clusters, including Topics, Partitions, Consumer Groups, and their offsets. By providing a user-friendly interface, Kafdrop significantly simplifies the monitoring and management of Kafka clusters, enabling users to quickly obtain cluster status information without relying on complex command-line tools.
Thanks to AutoMQ's full compatibility with Kafka, it can seamlessly integrate with Kafdrop. By leveraging Kafdrop, AutoMQ users can also enjoy an intuitive user interface to monitor Kafka cluster status in real-time, including key metadata such as Topics, Partitions, Consumer Groups, and their offsets. This monitoring capability not only improves the efficiency of problem diagnosis but also helps optimize cluster performance and resource utilization.
This tutorial will teach you how to start the Kafdrop service and use it alongside an AutoMQ cluster to achieve cluster status monitoring and management.
-
A functional Kafdrop environment.
-
A functional AutoMQ cluster.
You can refer to the AutoMQ official documentation for the deployment of the AutoMQ cluster: Cluster Deployment on Linux Hosts | AutoMQ [2]
In the above process, the AutoMQ cluster has been set up, and the addresses and ports of all broker nodes are known. Next, we will start the Kafdrop service.
Note: Ensure that the address where the Kafdrop service is located can access the AutoMQ cluster; otherwise, it will result in connection timeouts and other issues.
Kafdrop can be deployed via JAR package, Docker, and protobuf. Refer to the official documentation [3] 。
In this example, we use the JAR package to start the Kafdrop service. The steps are as follows:
- Pull the Kafdrop repository source code: Kafdrop GitHub
git clone /~https://github.com/obsidiandynamics/kafdrop.git
- Use Maven to locally compile and package Kafdrop to generate a JAR file. Execute the following in the root directory:
mvn clean compile package
- To start the service, you need to specify the addresses and ports of the AutoMQ cluster brokers:
java --add-opens=java.base/sun.nio.ch=ALL-UNNAMED \
-jar target/kafdrop-<version>.jar \
--kafka.brokerConnect=<host:port,host:port>,...
-
kafdrop-<version>.jarNeeds to be replaced with a specific version, such as:kafdrop-4.0.2-SNAPSHOT.jar。 -
--kafka.brokerConnect=<host:port,host:port>The host and port need to be specified as the actual cluster broker nodes.
The console startup output is as follows:
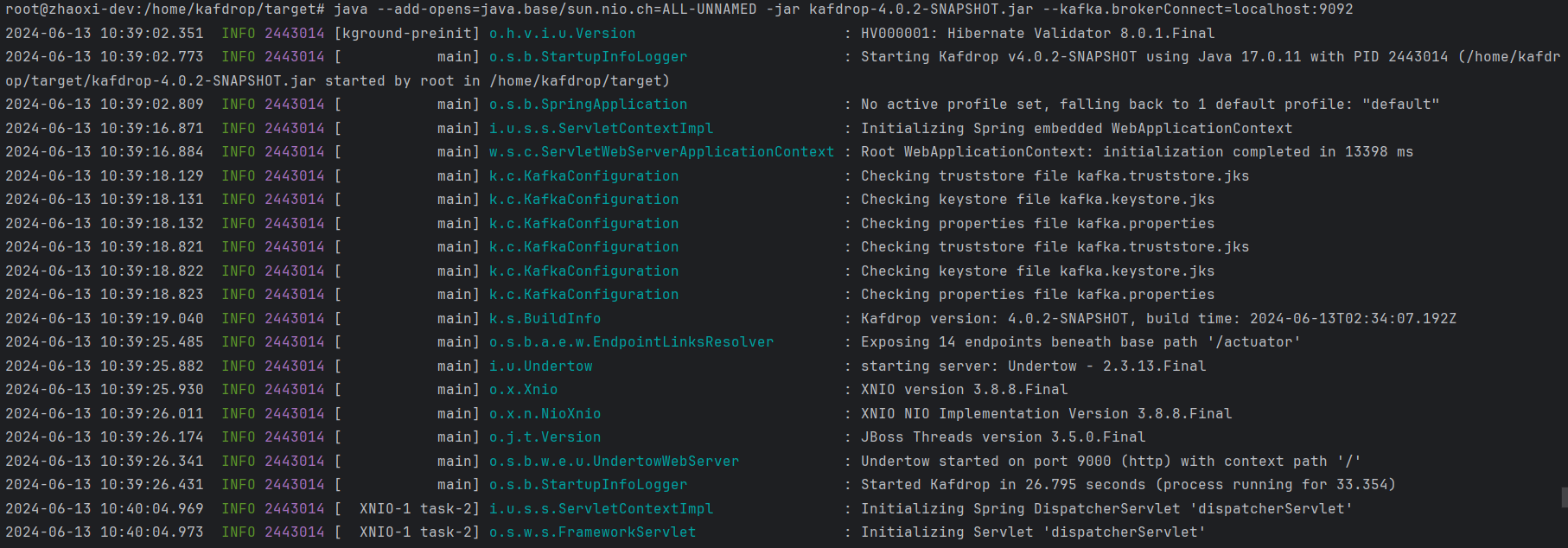
If not specified, kafka.brokerConnect defaults to localhost:9092.
Note: Starting from Kafdrop 3.10.0, a ZooKeeper connection is no longer required. All necessary cluster information is retrieved via the Kafka management API.
Open your browser and navigate to http://localhost:9000. You can override the port by adding the following configuration:
--server.port=<port> --management.server.port=<port>
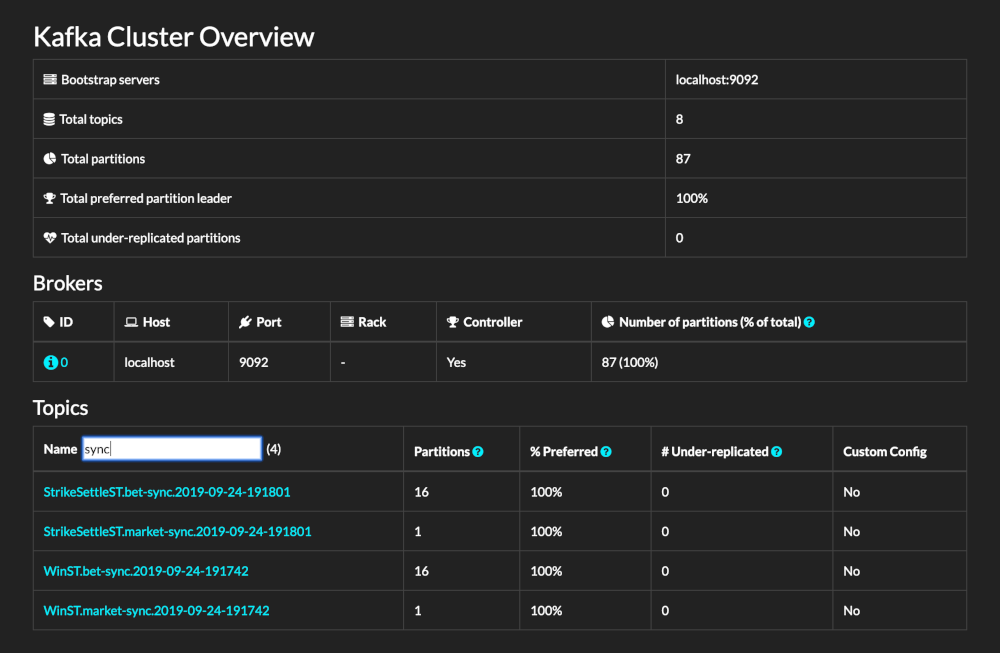
- Full Interface
Displays the number of partitions, topics, and other cluster status information.
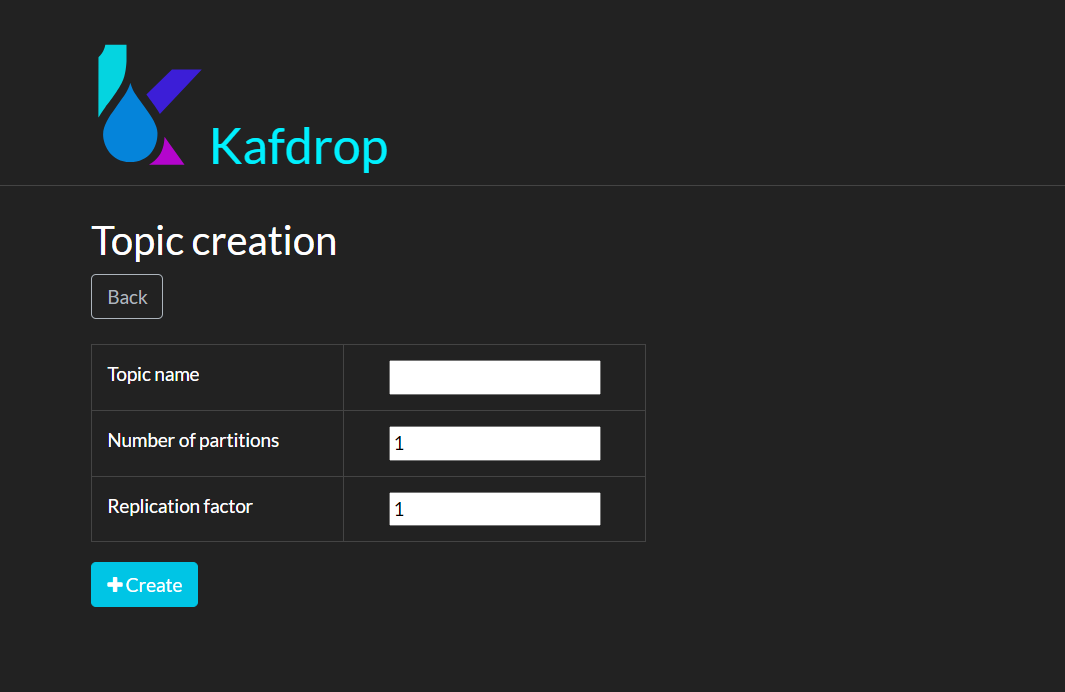
- Create New Topic Feature
- Broker Node Details
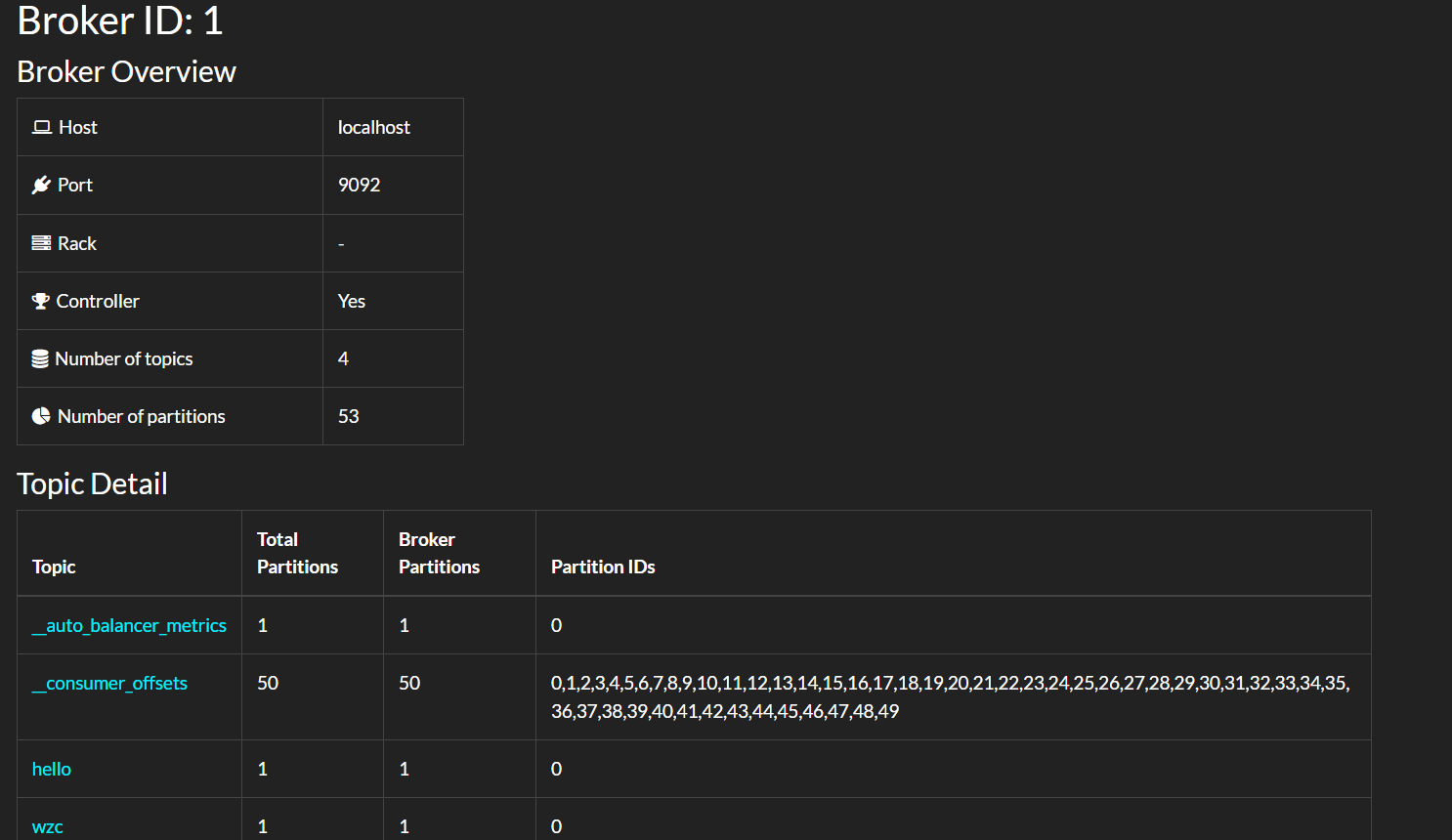
- Topic Details
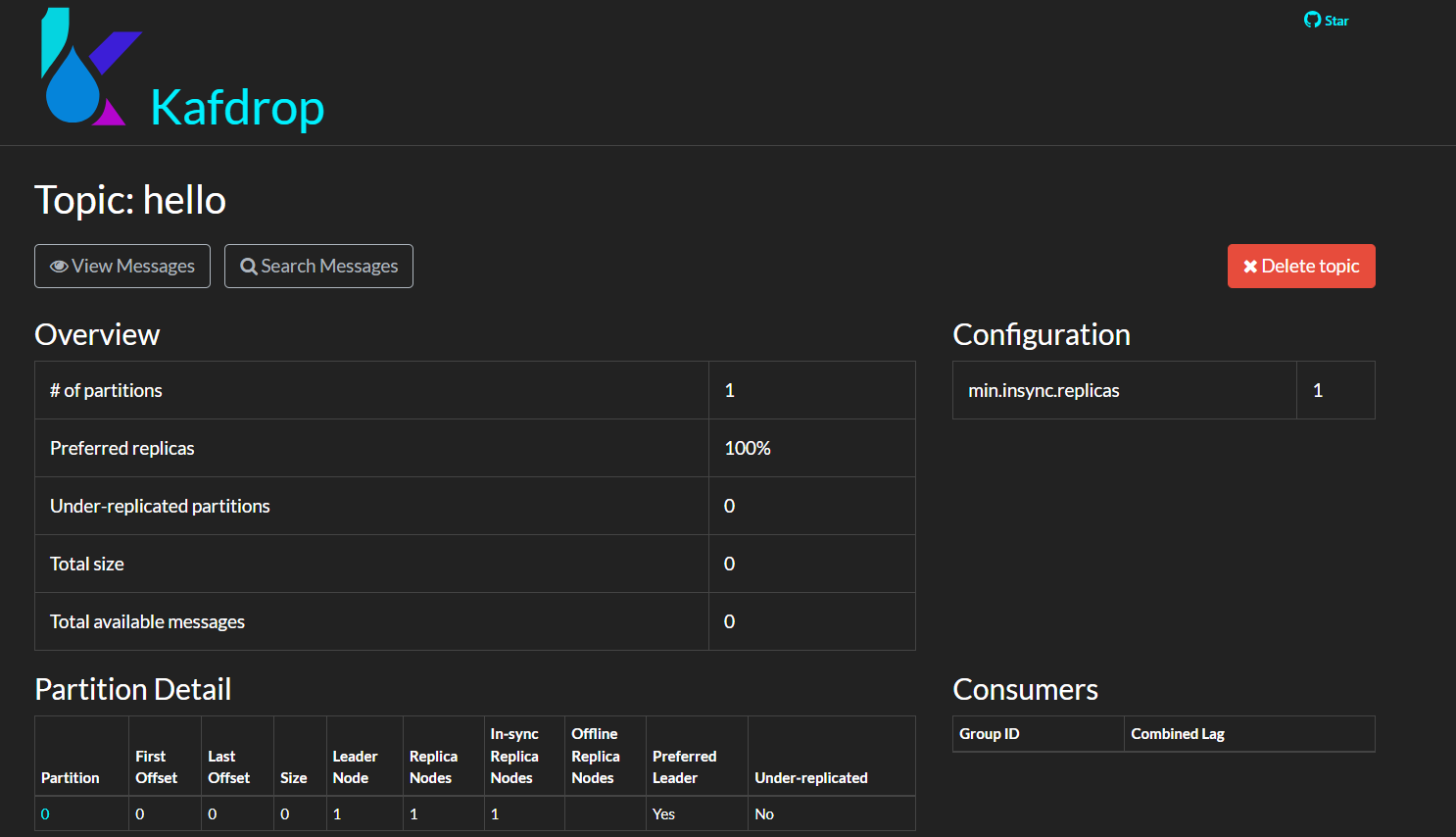
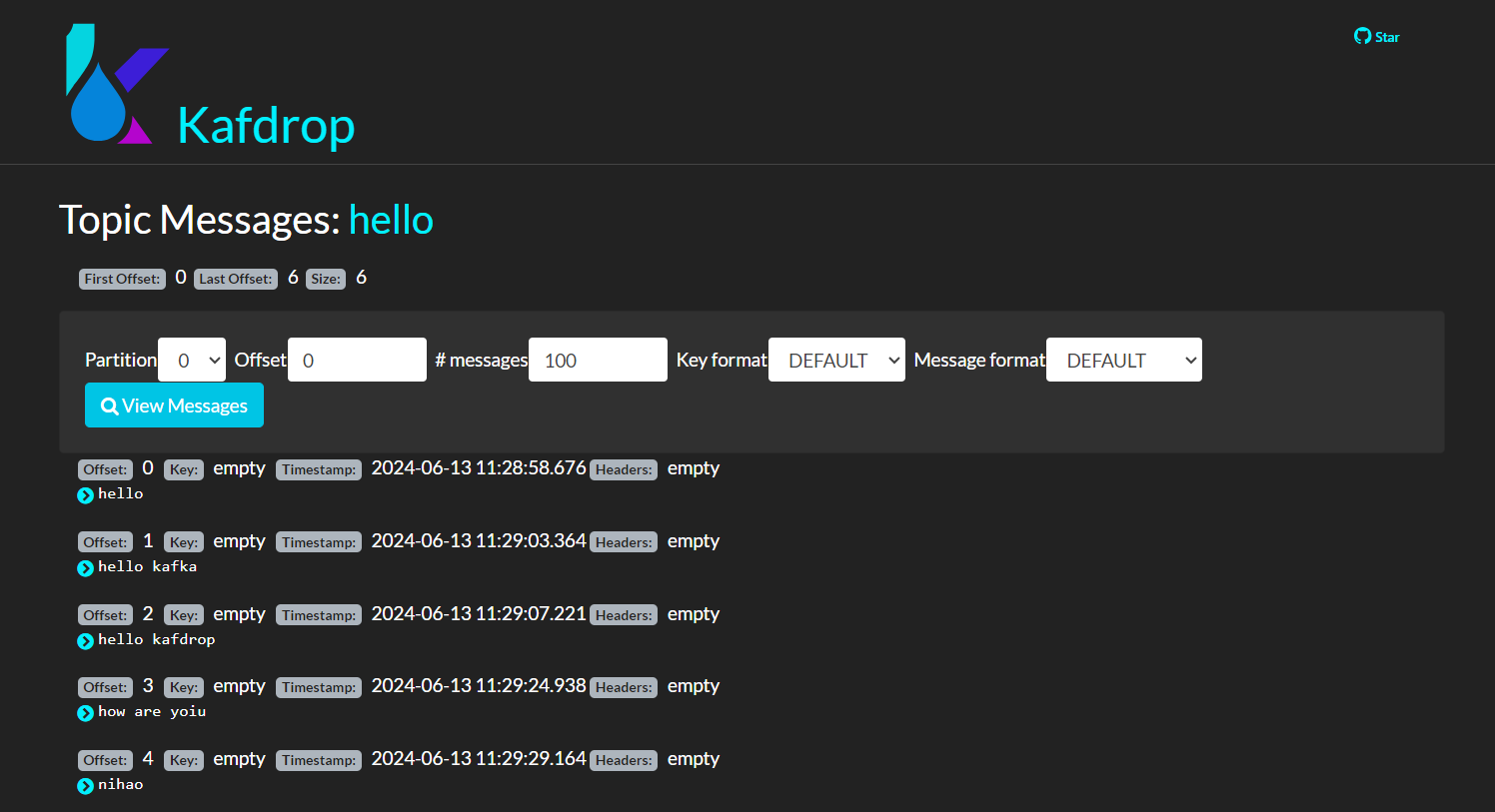
- Message Information under Topic
This tutorial explores the key features and functionalities of Kafdrop, as well as the methods for integrating it with the AutoMQ cluster, demonstrating how to easily monitor and manage the AutoMQ cluster. The use of Kafdrop not only helps teams better understand and control their data flow but also improves development and operational efficiency, ensuring the efficient and stable processing of data. I hope this tutorial provides valuable insights and assistance when using Kafdrop with the AutoMQ cluster.
[1] Kafdrop: /~https://github.com/obsidiandynamics/kafdrop
[2] Cluster Deployment on Linux Hosts | AutoMQ: https://docs.automq.com/automq/getting-started/cluster-deployment-on-linux
[3] Kafdrop Deployment Method: /~https://github.com/obsidiandynamics/kafdrop/blob/master/README.md#getting-started
[4] Kafdrop Project Repository: /~https://github.com/obsidiandynamics/kafdrop