Models
GPT-Neo is an implementation of model & data-parallel GPT-3-like models by Eleuther AI and specially designed for TPUs. A sample input-output of the model is shown below:
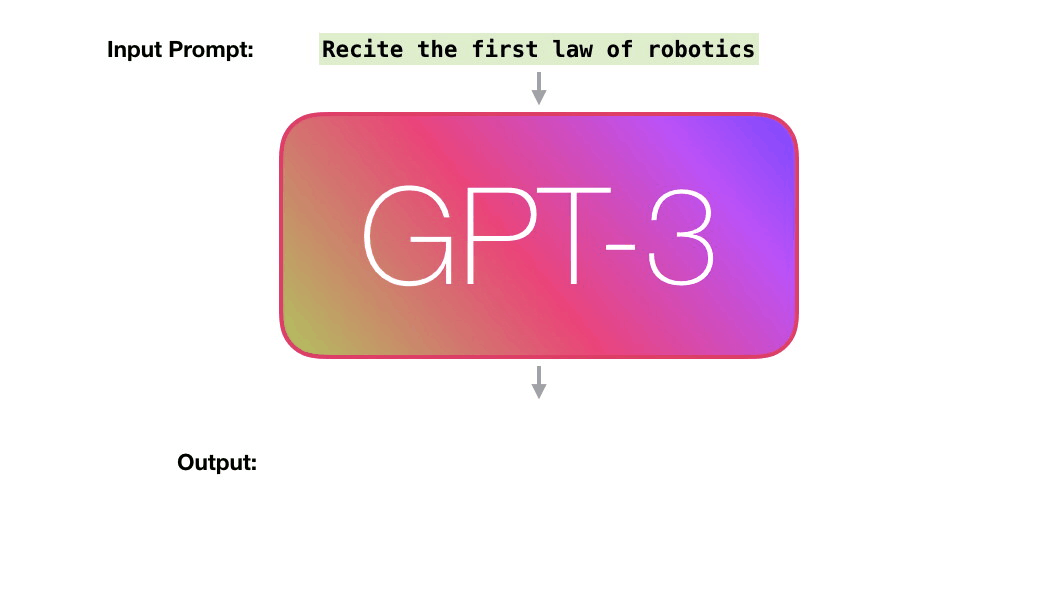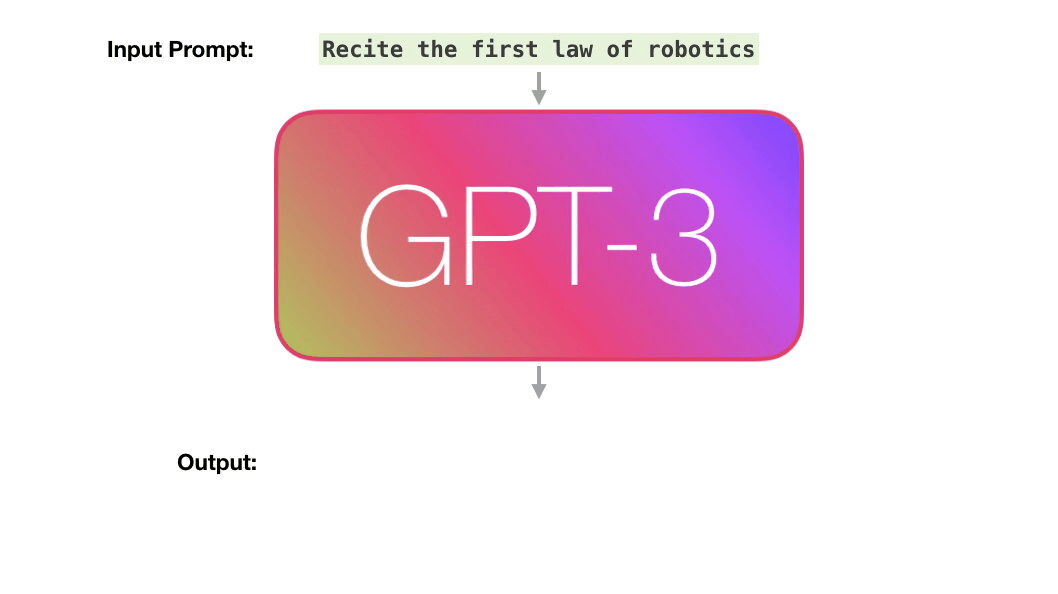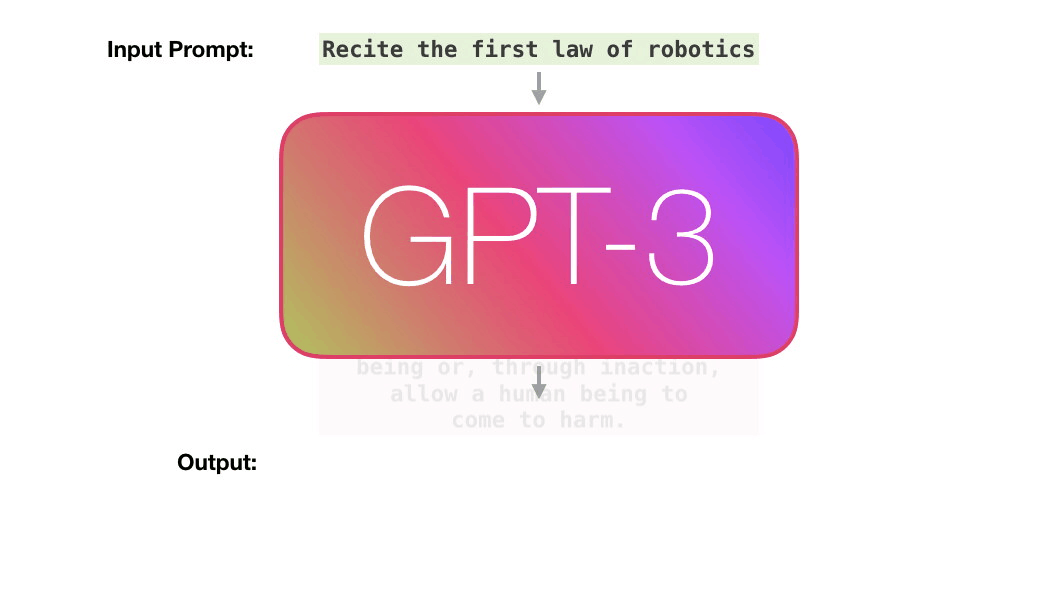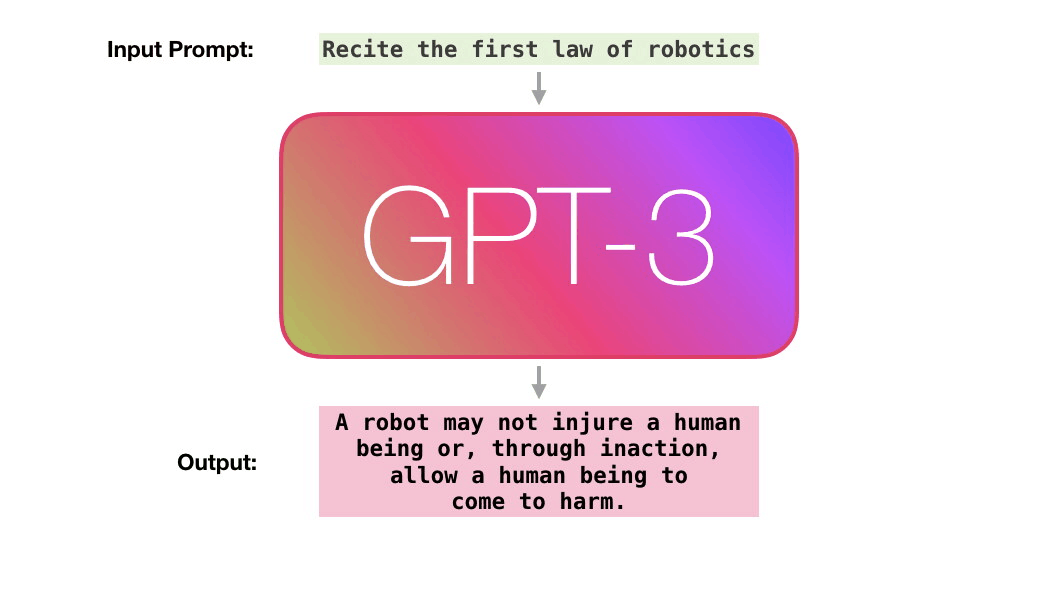
Source: https://jalammar.github.io/how-gpt3-works-visualizations-animations/
In our case of code generation, we feed in a problem statement and some starter code as the input and the output is the solution or the code generated in addition to the starter code:

Causal language modelling (CLM) is the task of predicting the token following a sequence of tokens. In this situation, the model only attends to the left context (tokens on the left of the mask) (HuggingFace (n.d.)) and thus is useful for generation tasks. Since we have framed our code generation task such that problem statement and starter code is provided and the code following that is being predicted (left context), CLM was appropriate for us
Training is done using the training scripts available here.
For fine-tuning GPTNeo-125M on CodeClippy dataset we used AdamW optimizer (beta1=0.9, beta2=0.95) with GPT3-like learning rate schedule (4k warmup steps from 0 to 5e-5 followed by 50k cosine decay steps to 5e-6), weight decay 0.1 and batch size 1024, sequence length 2048. The choice of relatively large batch size and low LR with long warmup is made to avoid aggressive updates and preserve the knowledge contained in pretrained GPTNeo weights.
For fine-tuning GPTNeo-125M on APPS dataset, we used AdamW optimizer (beta1=0.9, beta2=0.98) with linear learning rate schedule (800 warmup steps from 0 to peak LR followed by linear decay to 0, a range of value for peak LR was [1e-5; 1e-4]), weight decay 0.1 and batch size 256, sequence length 1024. We trained the model for 5 epochs selecting the best checkpoint judging by validation loss. The language modelling objective for APPS dataset is modified to backpropagate loss only for the tokens corresponding to code solution (refer to Hendrycks et al for more details).
For fine-tuning GPTNeo-1.3B on APPS dataset, we used Adafactor optimizer with linear learning rate schedule (5k warmup steps from 0 to 2e-5 followed by linear decay to 0), weight decay 0.1 and batch size 24, sequence length 1024. The choice of hyperparameters for 1.3B model is in part determined by hardware limitations. We trained model for 5 epochs selecting best checkpoint judging by validation loss.
Below is a table containing the base model we started from, the dataset we used to finetune/pretrain the model, and the model's performance on the HumanEval Benchmark. Due to limited compute constraints and time we were not able to evaluate the large 1.3B models. So, those contain TBD as we plan to evaluate them in the future. Additionally, you can view the model cards of each model we trained by clicking on the links provided in the Model column below.
pass@k refers to how many samples were considered when determining if the model generated a solution that passed the unit tests. For example, pass@1 means only one of the generated text was tested against the unit tests, pass@10 means ten were tested.
| Model | Dataset Used | pass@1 | pass@2 | pass@5 | pass@10 |
|---|---|---|---|---|---|
| gpt-neo-125M | The Pile | 0.12% | 0.24% | 0.61% | 1.22% |
| gpt-neo-125M | APPS (Train) | 0.06% | 0.12% | 0.30% | 0.61% |
| gpt-neo-125M | APPS (Train + Test) | TBD... | |||
| gpt-neo-1.3B | APPS (Train) | TBD... | |||
| gpt-neo-1.3B | APPS (Train + Test) | TBD... | |||
| gpt-neo-125M | Code Clippy Data | 0.00% | 0.00% | 0.00% | 0.00% |
| gpt-neo-125M | Code Clippy Data (Deduplicated) | 0.00% | 0.00% | 0.00% | 0.00% |
| gpt-neo-125M | Code Search Net Challenge (All) | 0.00% | 0.00% | 0.00% | 0.00% |
| gpt-neo-125M | Code Search Net Challenge (Python) | 0.00% | 0.00% | 0.00% | 0.00% |
| gpt-neo-125M (trained from scratch) | Code Clippy Data (Deduplicated) (~1% of the data) | 0.00% | 0.00% | 0.00% | 0.00% |