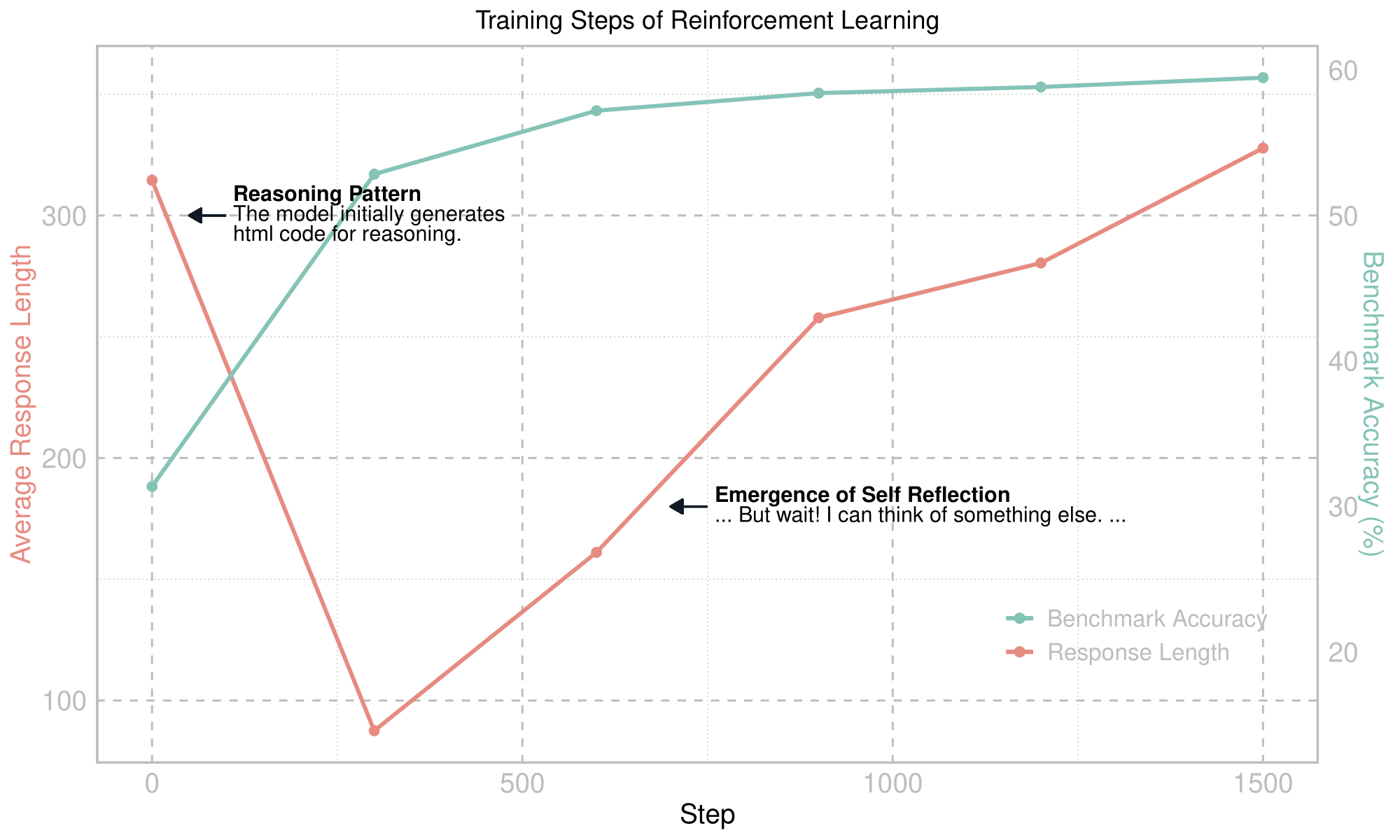
Training dynamics of our VisionThinker-R1-Zero training starting from the Qwen-VL-2B, without SFT or reward models. An aha moment and increasing response length is ever observed at a multimodal model.
DeepSeek R1 has demonstrated how Reinforcement Learning (RL) with well-designed rule-based rewards can enable a large language model to build unique reasoning capabilities autonomously. Since then, many researchers have attempted to extend this success to multimodal reasoning. However, recent efforts primarily struggle to reproduce the increasing response length and thinking pattern exhibited by DeepSeek R1.
VisionThinker-R1-Zero is a replication of DeepSeek-R1-Zero training on small multimodal models. We are the first to successfully observe the emergent “aha moment” and increased response length on multimodal tasks. Through applying GRPO on the 2B base LM develops self-verification autonomously and exhibits an emergent ability to "take another look" at the image and correct its mistakes.
-
We are the first to replicate the key characteristics of R1 success (”aha moment” and increasing reasoning length) on multimodal reasoning tasks.
-
We showed that vision-centric tasks could also benefit from improved reasoning capabilities.
Similar to DeepSeek R1, self reflection behavior is also observed during our RL training on vision-centric reasoning tasks. The model exhibits an emergent ability to rethink and correct its mistakes:
. . .
Therefore, dark brown wooden bed with white blanket is not above the doorway.
But wait! I can think of something else.
Maybe it's just higher than above the doorway, but slightly lower than above the doorway.
. . .
Full experiment log: Upcoming
Models CKPT: Upcoming
- 2025-02-26: We share our main findings in this notion blog.
- 2025-02-26: We release the VisualThinker R1 Zero repo.
bash setup.shcd src/data/SAT
bash prepare_dataset.shTo reproduce the multimodal aha moment, run the following code to train the unaligned base model with GRPO on SAT:
cd src/open-r1-multimodal
bash run_grpo_SAT.sh # Adjust open-r1-multimodal/configs/zero3.yaml or zero2.yaml accordinglyTo obtain SFT model for comparison, run the following code to train the unaligned base model on SAT:
cd src/open-r1-multimodal
bash run_sft.sh # Adjust open-r1-multimodal/configs/zero3.yaml or zero2.yaml accordinglyFirst change to evaluation directory:
cd src/eval To evaluate Base + GRPO (VisualThinker R1 Zero) model:
python evaluate_Qwen2_VL_CVBench-base.py --model_path <path_to_your_model> \
--bs 8 \
--use_reasoning_promptTo evaluate Base model:
python evaluate_Qwen2_VL_CVBench-base.py --model_path <path_to_your_model> \
--bs 8 \
--no-use_reasoning_promptTo evaluate Instruct + GRPO model:
python evaluate_Qwen2_VL_CVBench.py --model_path <path_to_your_model> \
--bs 8 \
--use_reasoning_promptTo evaluate Instruct model:
python evaluate_Qwen2_VL_CVBench.py --model_path <path_to_your_model> \
--bs 8 \
--no-use_reasoning_promptWe are always open to engaging discussions, collaborations, or even just sharing a virtual coffee. To get in touch or join our team, visit TurningPoint AI's homepage for contact information.
We sincerely thank DeepSeek, Open-R1, QwenVL, Open-R1-Multimodal, R1-V, SAT, and CV-Bench for providing open source resources that laid the foundation of our project.
If you find our work useful for your projects, please kindly cite the following BibTeX:
@misc{zhou2024visualthinkerr1,
title={The Multimodal “Aha Moment” on 2B Model},
author={Hengguang Zhou and Xirui Li and Ruochen Wang and Minhao Cheng and Tianyi Zhou and Cho-Jui Hsieh},
journal= {arXiv preprint arXiv:XXXX.XXXXX},
year={2025},
url={https://arxiv.org/abs/XXXX.XXXXX}
}