Data Preprocessing Steps and Inspiration
Future Possibilities of the Project
This project involves creating a movie recommender system using various recommendation algorithms. The system includes simple recommenders, content-based filtering, and collaborative filtering techniques to provide movie recommendations.
The project utilizes two datasets:
- Ratings Dataset (ratings_small.csv): Contains user ratings for collaborative filtering.
- Entries: 100,004
- Columns: userId, movieId, rating
- Movie Metadata and Credits Datasets: Contains movie metadata and credits for content-based and simple recommenders.
- userId: Unique identifier for each user.
- movieId: Unique identifier for each movie.
- rating: Rating given by the user to the movie.
- budget: Budget of the movie.
- genres: List of genres associated with the movie.
- homepage: URL of the movie's homepage.
- id: Unique identifier for each movie.
- keywords: Keywords related to the movie.
- original_language: Original language of the movie.
- original_title: Original title of the movie.
- overview: Brief description of the movie plot.
- popularity: Popularity score of the movie.
- production_companies: Production companies involved in making the movie.
- production_countries: Countries where the movie was produced.
- release_date: Release date of the movie.
- revenue: Revenue generated by the movie.
- runtime: Duration of the movie.
- spoken_languages: Languages spoken in the movie.
- status: Release status of the movie.
- tagline: Tagline of the movie.
- title: Title of the movie.
- vote_average: Average rating of the movie.
- vote_count: Number of votes received by the movie.
- movie_id: Unique identifier for each movie.
- title: Title of the movie.
- cast: List of main cast members.
- crew: List of crew members.
-
Python: Data Cleaning and Analysis
-
Jupyter Notebook: For interactive data analysis and visualization
Libraries
Below are the links for details and commands (if required) to install the necessary Python packages:
Below are the links for details and commands (if required) to install the necessary Python packages:
- pandas: Go to Pandas Installation or use command:
pip install pandas - numpy: Go to NumPy Installation or use command:
pip install numpy - matplotlib: Go to Matplotlib Installation or use command:
pip install matplotlib - seaborn: Go to Seaborn Installation or use command:
pip install seaborn - scikit-learn: Go to Scikit-Learn Installation or use command:
pip install scikit-learn - surprise: Go to Surprise Installation or use command: pip install scikit-surprise`
- Data loading and initial exploration
- Data cleaning and manipulation
- Checking for missing values and duplicates
- Merging the movies and credits datasets
- Handling Missing Values: Identified and handled missing values in the dataset.
- Merging Datasets: Merged the movies and credits datasets on the id column.
- Feature Extraction: Extracted relevant features such as cast, crew, genres, and overview for content-based filtering.
- Creating Weighted Ratings: Calculated weighted ratings for movies using the IMDB formula.
-
Simple Recommender - IMDB Weighted Rating: Uses a formula to calculate weighted ratings based on average rating, number of votes, and a minimum vote threshold.
-
Simple Recommender - Trending Movies: Recommends trending movies based on popularity.
-
Content-Based Filtering:
- Overview Based: Recommends movies based on plot similarity using TF-IDF and cosine similarity. TF-IDF (Term Frequency-Inverse Document Frequency) is a statistical measure used to evaluate the importance of a word in a document relative to a collection of documents.
- Credits, Genres, and Keywords Based: Recommends movies based on similarity in cast, crew, genres, and keywords using CountVectorizer and cosine similarity. Count Vectorize converts a collection of text documents to a matrix of token counts, helping in text analysis and feature extraction.
- Collaborative Filtering: Singular Value Decomposition (SVD): Uses matrix factorization to predict user ratings for movies based on past user ratings.
- Ratings provided by users are reliable.
- User preferences are consistent over time.
- Movies with higher ratings are preferred by users.
- MAE (Mean Absolute Error): Measures the average magnitude of errors in a set of predictions, without considering their direction.
- RMSE (Root Mean Squared Error): Measures the square root of the average squared differences between predicted and observed values.
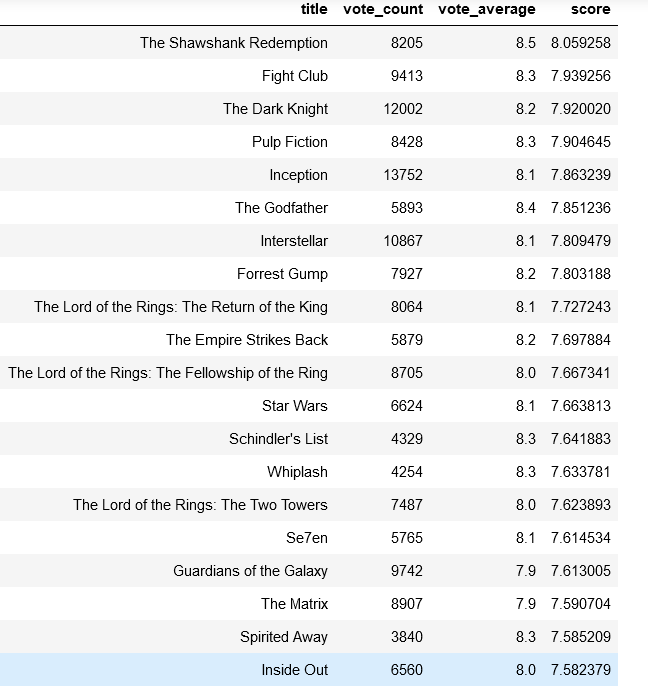
Findings: Weighted ratings calculated using IMDB formula, top 20 movies sorted by score.
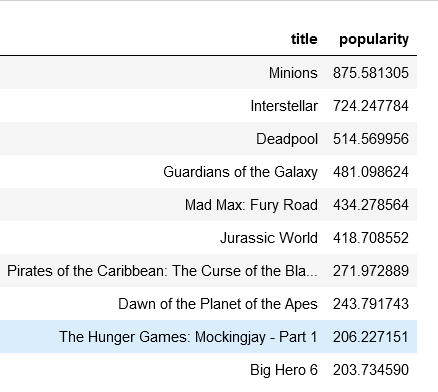
Findings: Top 10 movies sorted by popularity.
Findings: Recommends movies based on plot similarity using TF-IDF and cosine similarity.

Findings: Recommends movies based on similarity in cast, crew, genres, and keywords using CountVectorizer and cosine similarity.

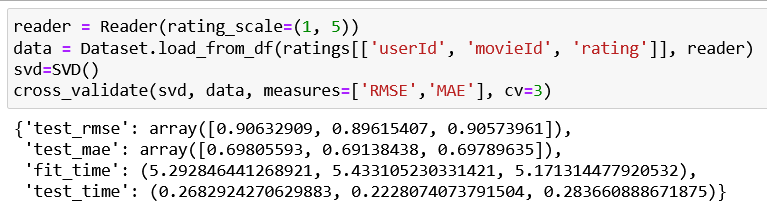
Findings: Predicted user ratings for movies using SVD with evaluation metrics MAE and RMSE.
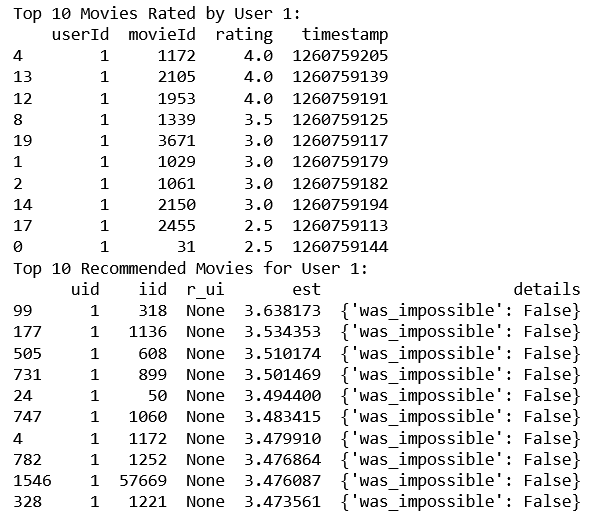
Findings: Top 10 recommended movies for a given user(Example - user 1)
- Further data collection and feature engineering could improve the recommendation accuracy.
- Regularly updating the model with new movie data can help maintain recommendation relevance.
- Implementing user feedback mechanisms to continuously improve recommendations.
- The dataset may contain biases that could affect the recommendations.
- The recommendation performance is limited by the quality and quantity of the available data.
- Exploring additional recommendation algorithms and ensemble methods.
- Implementing deep learning models for better performance.
- Developing real-time recommendation systems based on user interactions.