This is a Data Science project for the Udacity's Data Scientist Nanodegree. In this project, we build a complete NLP pipeline, composed by an ETL and ML pipelines, along with a model deployment into a web app.
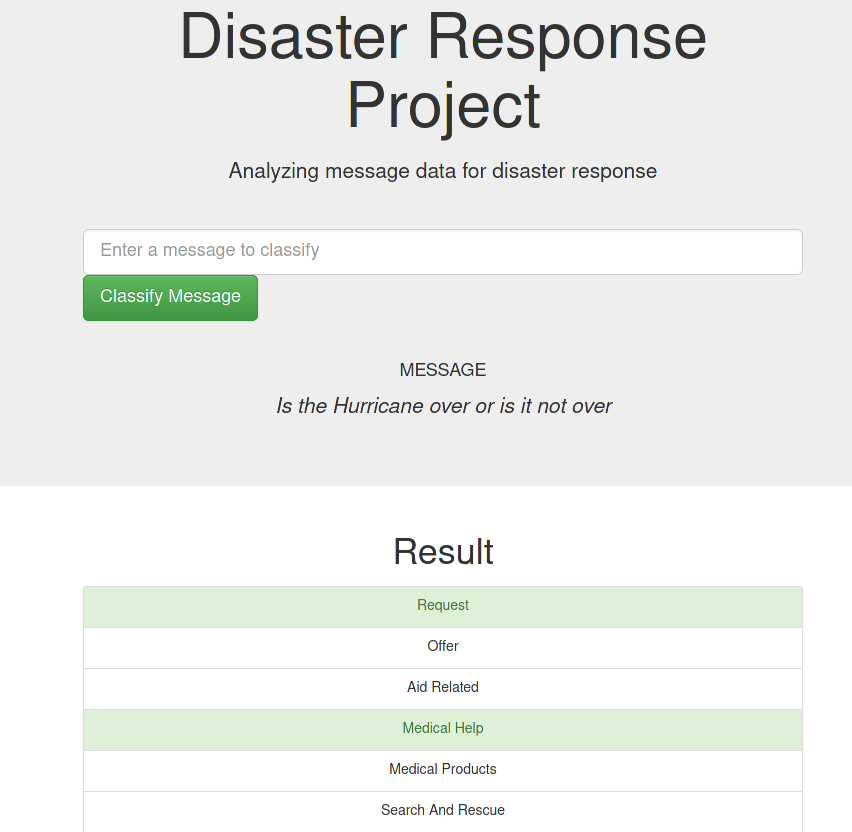
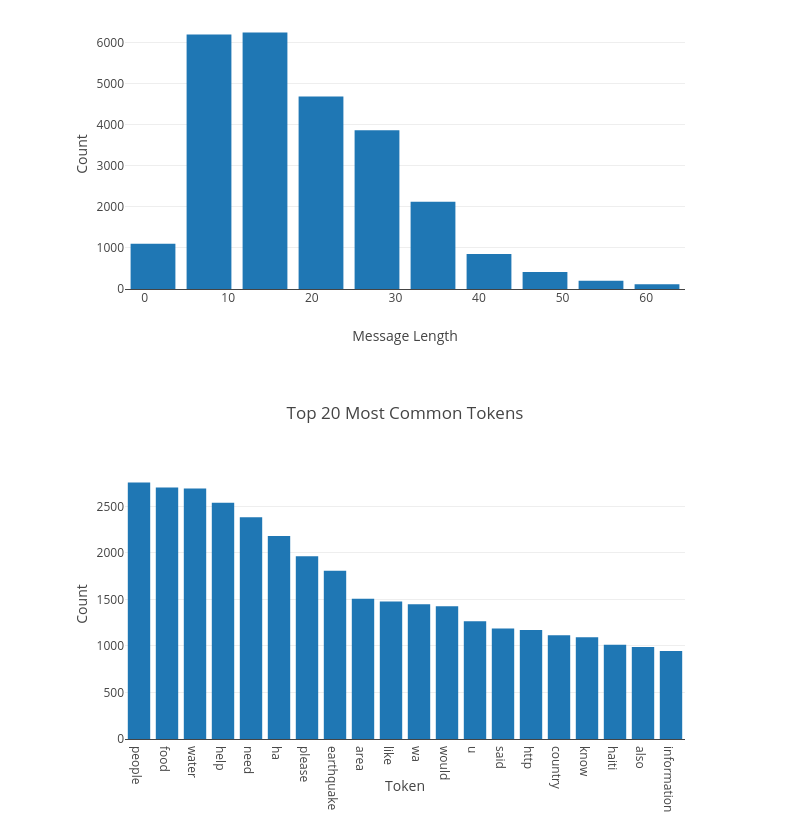
Our model was built to classify emergency messages into well-defined categories so these messages may be sent to an appropriate disaster relief agency. The messages were extracted from real disaster data, provided by Figure Eight. The app also provides some visuals and insights on the dataset.
- python 3.9.5
- flask 2.0.1
- matplotlib 3.4.2
- numpy 1.20.3
- nltk 3.6.2
- plotly 5.1.0
- scikit-learn 0.24.2
- seaborn 0.11.1
- sqlalchemy 1.4.22
- stopwords 1.0.0
app: directory with the web app html files and the flask code.
data: directory with the csv dataset files and some Jupyter notebooks that were used to prototype the ETL and ML pipelines. In this directory, you can also find the process_data.py which is an important script that runs the complete ETL pipeline.
models: directory with the train_classifier.py script, which runs the ML pipeline.
pictures: hosts the pictures that appear in the README.md file.
-
Run the following commands in the project's root directory to set up your database and model.
- To run ETL pipeline that cleans data and stores in database
python data/process_data.py data/disaster_messages.csv data/disaster_categories.csv data/DisasterResponse.db - To run ML pipeline that trains classifier and saves
python models/train_classifier.py data/DisasterResponse.db models/classifier.pkl
- To run ETL pipeline that cleans data and stores in database
-
Run the following command in the app's directory to run your web app.
python run.py -
Go to http://0.0.0.0:3001/
The majority of the project's boilerplate code was provided by Udacity, as a base template.
The ETL and ML pipelines, along with two of the three visuals, were written by the project's author. Some inspiration was taken from sarasun97.
At last, the data was provided by Figure Eight.