This is a PyTorch project for facial keypoint detection and I have tried to recreate the Instagram filters by augmenting objects like hat and mustache on the detected keypoints.
Facial Recognition has large scale applications which include: facial tracking, facial pose recognition, facial filters, and emotion recognition.
These set of image data has been extracted from YouTube Faces Dataset, which includes videos of people in YouTube videos. These videos have been fed through some processing steps and turned into sets of image frames containing one face and the associated keypoints.
This facial keypoints dataset consists of 5770 color images. All of these images are separated into either a training or a test set of data.
- 3462 of these images are training images, for you to use as you create a model to predict keypoints.
- 2308 are test images, which will be used to test the accuracy of your model.
The marking coordinates are given in the seperate csv files. This can be visualized in the below image.

This artice from PyTorch documentation was of great help.Though there are few changes made in order to speedup the training process.
Pre-processing on the the Images
Image is first resized converting the larger dimension to 250px maintaining the aspect ratio for the other dimension, then randomly cropped and converted to 224 * 224 size image, further it is normalized such that value of each pixel is between [0,1], finally it is converted to torch tensor.
Pre-processing on the the keypoints
Keypoints are normalized by subtracting the mean and dividing by the standard deviation.
- All the transformation are done on the fly during the training in order to carry out data augmentation.
- The same transforms are available readily with the PyTorch library but as keypoints also need to be transformed base on the dimensions of the image they are manually coded.
- Here the outputs are the values of the pixels which are large numbers and can lead to exploding gradient problem. Hence they are suppressed to smaller values by the means of normalizing.
The details about the model can be found here.
The architecture is inspired from NaimishNet link to which can be found here.
Hyper-Parameters of the training process.
- Epochs : 10
- Batch Size : 16
- lr : 0.001
- optimizer : Adam
- Random cropping is the most important transformation here.The reason is as in all the images faces are close to the center.Hence I believe CNN is rather learning to get the points at the center rather than getting them on the faces.
- The transformation that are done during the training are CPU intensive but they cannot to done before hand as randomity is the main point of data-augmentation.
- The Layers are initialized with weights from Kaiming He normal distribution which is widely considered good for non-symmetric activation funcition ReLU. And indeed it showed fast convergence.
- Here the output is 138 values indicating the pixel coordinates and the MSELoss function give average loss accross each individual output not for the entire set of 138 values(Well I didn't knew that before!!)
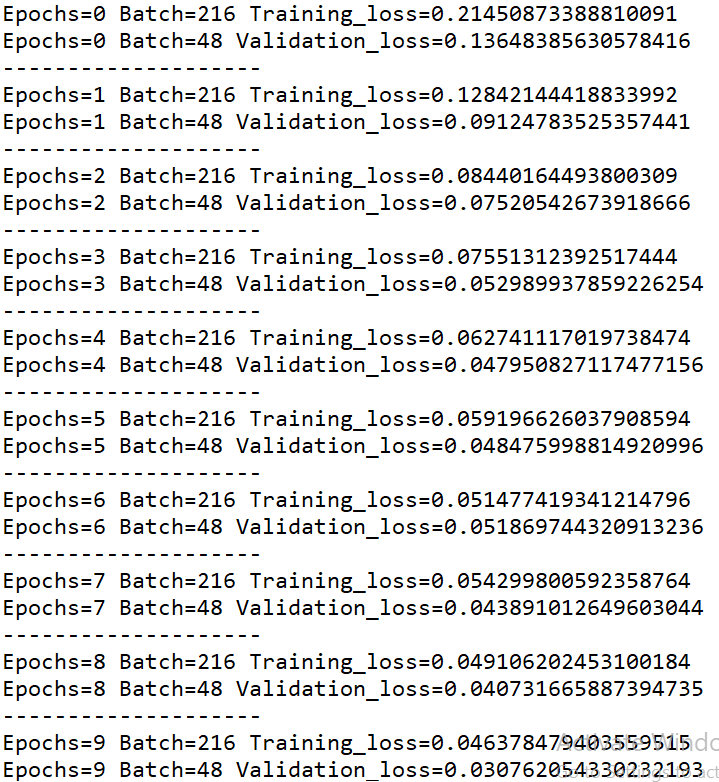
Here is the picture of the training process.I cannot understand why is the validation loss less than training loss all the time.For now I came to a conclusion that test data is easy compared to train data

This is the sample taken from the test set which is not used for training. Left side image is marked with correct values while right side image is marked with the predicted values.


(Ohh by the way that's me)
Different objects(here sun-glasses and mustache) can be augmented on the detected keypoints.Width, Height and Orientation are set based on keypoints detected.Also this entire system works in real time on a cpu.

- Train model only for points correspoding to eyes and nose