This repository is the final project to complete the Telkom Digital Talent Incubator 2020 program. This research project was created as our contribution as a Telkom DTI 2020 Data Scientist to the UN Sustainable Development Goals 2030 program in the social justice and humanities fields to realize racial equality in communities worldwide.

The dataset used is a collection of racist tweets in Indonesian. This dataset contains 511 rows labeled Non-Racism and 175 rows labeled Racism. You can see the dataset in the following link:
https://raw.githubusercontent.com/asthala/racism-detection/master/datasetfix.csv
This how the dataset looks like in wordcloud :


Text data needs to be cleaned and encoded to numerical values before giving them to machine learning models. This process of cleaning and encoding is called text preprocessing. The following are the preprocessing stages carried out in this project:
- Data Cleaning: aims to remove HTML tags, username, URL, and other unnecessary symbols.
- Case Folding: aims to change the capital letter to a lowercase
- Tokenization: aims to separate sentences into word pieces called tokens for later analysis
- Stopword Removal: aims to remove any word tokens that contain stopword words (unnecessary words)
- Stemming: aims to transform tokens into basic words by removing all word affixes
- TF-IDF: aims to give weight to the terms of the dataset
- SMOTE Oversampling: aims to balance data classes
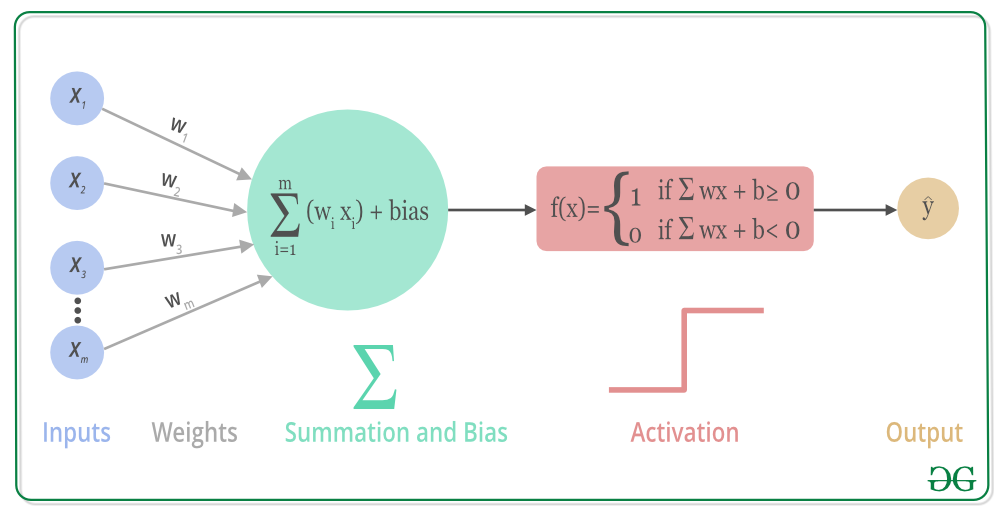
The model is build using the Multi Layer Perceptron or MLP architecture. The activation function that will be used for hidden neurons is the Rectified Linear Unit (ReLU).
{kind=link}
{kind=link}
{kind=link}
- Make sure you already have python and pip installed on your computer
- Install all requirements
pip install -r requirements.txt - Run app
python app.py - Go to your browser and run
127.0.0.1:5000
- Muhammad Alfhi Saputra
- Tigas Adrian Wahyuindrajati
- Crisnandra Rahmita Mardiantien
- La Ode Muhamad Sofyan Syarafa