Excelerated .xlsx generation that can create a basic .xlsx file with virtually no memory (~10MB), and in very little time (~1s for 1.5 million cells).
poetry add excelr
or
pip install excelrThe function excelr takes a stream, or filename to output to and an iterable of iterables which yields the cell values. You should prefer generators to reduce memory usage.
>>> from excelr import to_excel
>>> to_excel('example.xlsx', ['abc', '123'])
It is also possible to specify the format code which should be used for formatting each column, for example to display the second column (1234.59) as 1234.6 one could pass the following (see here):
>>> from excelr import to_excel
>>> to_excel('example.xlsx', ['abc', '1234.59'], column_format_codes={1: '####.#'})More information about the number formatting can be found in the specification, however it is often hard to find exactly the format code you need. Normally an easier way to figure out what the specific format code should be for your use case is to create a simple excel file with a single column in the desired format. You can then unpack this excel file (an .xlsx is simply a zip file with a different extension) and find the styles.xml file. The tag numFmt in styles.xml should show the format code you need for a specific format
The column formats are optional, when not specified the "General" format is used.
This is useful when you have the following requirements...
- You want to create a simple excel file without any bells or whistles, i.e. no fonts, no colours, freeze panes, a single sheet etc.
- You are working with a large dataset, and you want to use as little memory as possible (for example if you are providing an excel export from a web api)
Normally in these circumstances JSON or CSV are good choices, but for our use case these are problematic. Our users want to just open the downloaded file in excel, so JSON is not really an option. CSV files can be opened in excel, but since it is primarily a text format problems can arise with different locales.
Therefore we implemented this small library that can be used to generate a basic excel file extremely quickly (~1s for 1.5 million cells) and using very little memory (~10MB). Since it uses a temporary file to prevent having to materialize the whole file in memory, this speed is dependent on the type of hard disk in use, but when working with SSDs this is extremely fast.
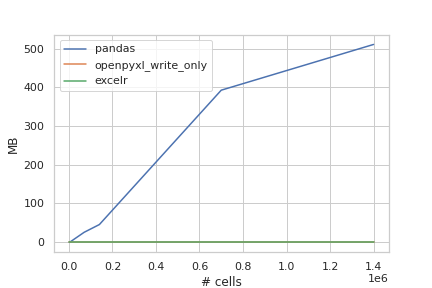
Here we compare the generation of an excel file from various sized datasets. We look at pandas, openpyxl (using the optimized write_only mode) and excelr. The tests look at wall time and memory usage. We can see that both openpyxl and excelr perform very well from a memory perspective, while excelr outperforms openpyxl when looking at run time.
The poor performance of the pandas test can be explained by the fact that we
first need to create a DataFrame before it can export to excel. Also pandas
does not take advantage of the write_only mode of openpyxl. Of course if you
already have a DataFrame, using the pandas to_excel function is probably
the best choice.
| Memory usage | Run Time |
|---|---|
 |
 |
(To generate these images run the benchmark.ipynb)
BSD 3-Clause License
- Use signed commits (git commit -S -m "commit message")
- Add pypi api token (https://pypi.org/help/#apitoken)...
poetry config pypi-token.pypi my-token
- To create a release...
./release