Custom implementation of Support Vector Machines using Python and NumPy, as part of the Combinatorial Decision Making and Optimization university course (Master in Artificial Intelligence, Alma Mater Studiorum - University of Bologna).
Mattia Orlandi
Lorenzo Mario Amorosa
This project requires the following libraries:
numpyfor basic operations on matrices;cvxoptfor the quadratic convex optimization;scikit-learnfor generating and splitting the dataset, to assess accuracy, and to confront our implementation with SVC;matplotlibfor plotting graphs.
The complete list of the packages used in the virtual environment is in requirements.txt; to install all those modules, it is sufficient to issue the command pip install -r requirements.txt (better if done in an Anaconda environment).
The repository is structured in the following way:
- the module
custom-svm/svm.pycontains the implementation of SVM for binary classification, with support to kernel functions and soft margin. - the module
custom-svm/multiclass_svm.pycontains the implementation of SVM for multiclass classification. - the notebook
custom-svm/svm_usecase.ipynbshows the usage of the SVM for many different purposes. - the package
custom-svm/datacontains generators and datasets.
We provided also a script version (custom-svm/svm_usecase.py) of the Jupyter notebook which can be run either in a terminal or in Spyder (recommended). For more clarity, it is suggested to at least read the notebook comments.
The Lagrangian problem for SVM is formulated as follows:

To integrate the soft margin in the formulation, for each data point  a variable
a variable  is introduced; such variable represents the distance of from the corresponding class margin if lies on the wrong side of such margin, otherwise they are zero. In other words, represents the penalty of the misclassified data point , and
is introduced; such variable represents the distance of from the corresponding class margin if lies on the wrong side of such margin, otherwise they are zero. In other words, represents the penalty of the misclassified data point , and  controls the trade-off between the amount of misclassified samples and the size of the margin.
controls the trade-off between the amount of misclassified samples and the size of the margin.
Every point must satisfy the following constraint:

By integrating it into the Lagrangian, the following is obtained:

Its dual problem is formulated as follows:

subject to:
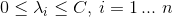

It is a quadratic optimization problem that can be solved using the quadratic library cvxopt in python, so it is necessary to match the solver's API which, according to the documentation, is of the form:

subject to:


Let  be a matrix such that
be a matrix such that  , then the function to optimize becomes:
, then the function to optimize becomes:

We then convert the sums into vector form and multiply both the objective and the constraint by −1, which turns this into a minimization problem and reverses the inequality in constaints. The optimization problem can be written as:

subject to:



It is now necessary to convert the numpy arrays that express the optimization problem accordingly to cvxopt format. Supposed m the number of samples and using the same notation as in the documentation, this gives:
 a matrix of size m×m
a matrix of size m×m a vector of size m×1
a vector of size m×1 a matrix of size 2m×m, such that a diagonal matrix of -1s of size m×m is concatenated vertically with another diagonal matrix of 1s of size m×m
a matrix of size 2m×m, such that a diagonal matrix of -1s of size m×m is concatenated vertically with another diagonal matrix of 1s of size m×m a vector of size 2m×1, with zeros in the first m cells and C in the other m cells
a vector of size 2m×1, with zeros in the first m cells and C in the other m cells the label vector of size m×1
the label vector of size m×1 a scalar
a scalar






It has to be noticed that in case of hard margin the constraints on the upper bound of the Lagrangian multipliers are not given, hence  and
and  are smaller in that case.
are smaller in that case.
Since the hyperplane is a linear function, the SVM model defined so far is suited only to linearly separable datasets, which is not very useful in real-world scenarios.
To enable the correct classification in the non-linear case, the data to classify is mapped by  into a new space, in which the data is linearly separable and thus in which SVM can be applied.
into a new space, in which the data is linearly separable and thus in which SVM can be applied.
However, computing the mapping for every  is computationally expensive; therefore, since only the product
is computationally expensive; therefore, since only the product  is relevant as far as fitting and classification are concerned, only the mapping of such product is considered (kernel trick):
is relevant as far as fitting and classification are concerned, only the mapping of such product is considered (kernel trick):

where  is called kernel function, and it can be:
is called kernel function, and it can be:
- dot product (linear case);
- polynomial;
- radial basis function;
- sigmoid.
In the python code the parameters needed by the solver are defined as follows, using the guideline previously provided:
K = np.zeros(shape=(n_samples, n_samples))
for i, j in itertools.product(range(n_samples), range(n_samples)):
K[i, j] = self.kernel_fn(X[i], X[j])
P = cvxopt.matrix(np.outer(y, y) * K)
q = cvxopt.matrix(-np.ones(n_samples))
# Compute G and h matrix according to the type of margin used
if self.C:
G = cvxopt.matrix(np.vstack((-np.eye(n_samples),
np.eye(n_samples))))
h = cvxopt.matrix(np.hstack((np.zeros(n_samples),
np.ones(n_samples) * self.C)))
else:
G = cvxopt.matrix(-np.eye(n_samples))
h = cvxopt.matrix(np.zeros(n_samples))
A = cvxopt.matrix(y.reshape(1, -1).astype(np.double))
b = cvxopt.matrix(np.zeros(1))
sol = cvxopt.solvers.qp(P, q, G, h, A, b)The support vectors can be get exploiting the variable sol, which are those with positive Lagrangian multipliers.
lambdas = np.ravel(sol['x'])
is_sv = lambdas > 1e-5
self.sv_X = X[is_sv]
self.sv_y = y[is_sv]
self.lambdas = lambdas[is_sv]It is possible to compute then 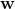 , if the kernel is linear, and
, if the kernel is linear, and  , which are the parameters of the "hyperplane" which separates the classes, in fact:
, which are the parameters of the "hyperplane" which separates the classes, in fact:

And given  as the set of the support vectors:
as the set of the support vectors:

In the python code the computation is made as follows:
self.w = np.zeros(n_features)
for i in range(len(self.lambdas)):
self.w += self.lambdas[i] * self.sv_X[i] * self.sv_y[i] self.b = 0
for i in range(len(self.lambdas)):
self.b += self.sv_y[i]
self.b -= np.sum(self.lambdas * self.sv_y * K[sv_index[i], is_sv])
self.b /= len(self.lambdas)Supposed S the number of support vectors, an input is assignment to a class label  with the following formula. As a side node, in case of linear kernel taking simply the dot product between input and support vectors is enough.
with the following formula. As a side node, in case of linear kernel taking simply the dot product between input and support vectors is enough.

In code:
y_predict = 0
for lamda, sv_X, sv_y in zip(self.lambdas, self.sv_X, self.sv_y):
y_predict += lamda * sv_y * self.kernel_fn(X, sv_X)
y_predict = np.sign(y_predict + self.b)The module multiclass_svm.py contains the implementation of Support Vector Machine for multi-classification purposes based on one-vs-one strategy.
It offers full support to kernel functions and soft margin, in fact the signature of its __init__ method is the same of the binary SVM.
Given N different classes to classify, the algorithm provides  SVM binary classifiers from the module
SVM binary classifiers from the module svm.py.
Each classifier is trained to correctly classify 2 of the N given classes. In the training process there are used only the entries in the dataset to which it corresponds a label of the 2 classes.
Given an unseen example, the prediction of the class is computed deploying a voting schema among the binary SVM classifiers.
The voting process is based on the standard predict function for binary SVM classifiers, so the tested entry is assigned to the class which wins the highest number of binary comparisons. In addition, it is available a mechanism to counteract the possible risk of draw in voting, based on the raw values predicted by the binary classifiers before the application of 'sign' function.
- The SVM model is initially created by specifying the type of kernel ('rbf'/'poly'/'sigmoid') and the value of the associated parameters ('gamma', 'deg' and 'r'); also, the parameter 'C' regulating the soft margin is specified.
- When the 'fit' method is called (passing a supervised training set), the model learns the correct parameters of the hyperplane by minimizing the dual lagrangian function discussed in the previous section.
- When the 'predict' method is called, new instances are classified according to the learnt parameters.
Tristan Fletcher, Support Vector Machines Explained
Humboldt-Universität zu Berlin, Lagrangian formulation of the SVM