[Chapter 10] 应用机器学习的建议 Advice for Applying Machine Learning
10.1 决定下一步做什么
- 要学习如何诊断模型
10.2 评估一个假设(模型)
- 7:3 = training set: data set
- 3分test数据 除了求损失函数值, 可能还需要增加误分类的比率计算(逻辑回归)
10.3 模型选择和交叉验证集
如何选择合适的模型? 方法?- 数据: 分成训练数据60%, 交叉验证集20%, 测试集20%
10.4 诊断 偏置和方差
- 高偏差 high bias: underfit 欠拟合
- 高项(多项式幂值) high variance: overfit 过拟合
- variance: 是多项式的 幂值, variance 翻译是方差=平方差, 差不多就是个幂值
10.5 正则化 和 偏置/方差
- 正则化的加入, 解决的是防止过拟合问题
- 跟# 10.4, 正则化的有损函数,
$\lambda$ 和$J_{cv}(\theta)$ 的关系 -
如何选择合适的正则化$\lambda$ 值?
10.6 学习曲线
-
识别高bias和高variance的曲线, 训练损失函数和交叉损失函数, 如何随着样本数量值变大, 而变化的? - 高bias, 样本数量增多, 对模型有帮助吗?
- 高variance(多参数(多项式)), 样本数量增多, 对模型有帮助吗?
10.7 总结
- 出现问题后,
* 如果有效的调整我们的模型
Deciding What to Try Next
训练模型, 你需要做的是如何优化他们, 如何改进你的算法
正则化的Cost Function

- 多些training data 训练样本, 代价较大
- 减少 x1,x2... 特征值
- 增加 x1,x2... 特征值
- 增加多项式, 例如:
$x_2^2, x_2^3$ ... - 减少或增加
$\lambda$ 值
接下来会介绍, 机器学习诊断法 有效评价你的学习算法效率。
Evaluating a Hypothesis
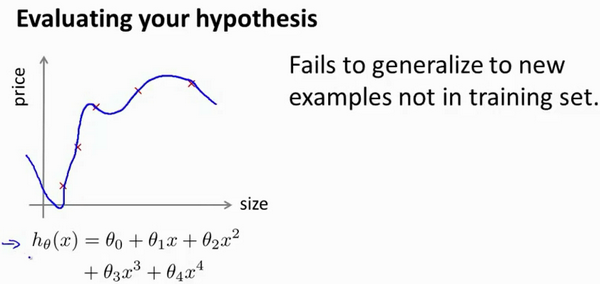
- 7分: 作为 training set
- 3分: 作为 data set Typically, the training set consists of 70 % of your data and the test set is the remaining 30 %.
对一个过拟合的$J(\theta)$ 来说,
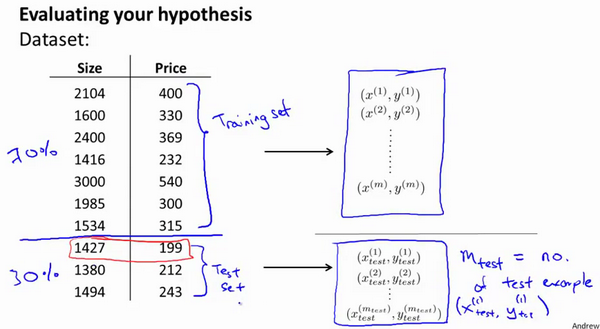
训练数据 Train data:
[过程]
(1) 用70%的训练(train)数据
- Learn Θ and minimize Jtrain(Θ) using the training set
(2) 用30%的测试(test)数据
- 来评估你的模型是否ok, 对每个用测试数据的预测结果$y_{predict}, y_{true}$ 进行
- Compute the test set error Jtest(Θ)
(3) 代价函数
- (3.1) 线性回归, 求代价函数即可
- (3.2) 逻辑回归, 求代价函数外,
还需要求个误分类的比率计算
每个样本
Model Selection and Train/Validation/Test Sets
我们需要在这是个多项式之间选择, 我们最终要的模型。
- 这种多项式,
$x^{10}$ 会 过拟合overfit 数据,$x^{1}$ 可能会 underfit数据
问题是???
越高次幂的多项式模型, 可能会很好的适应我们的训练模型, 但是如何推广呢? 随便来个测试数据, 我们的模型能适应一般情况吗?
- Training set: 60%
- Cross validation set: 20% 交叉验证集
- Test set: 20%


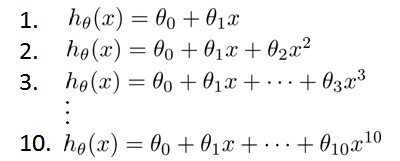
图上,

用来计算出推广的误差
(1) 假设函数 只是被 训练集, 很好的预测。我们用是个多项式, 去训练模型 by 训练集。
(2) 再用交叉验证去验证, cost function最小的那个多项式$J(\theta)$
(3) 用测试集, 再去测试$J(\theta)$的cost function
Diagnosing Bias vs. Variance
我们对10个(使用60%的训练数据训练的)模型 进行诊断(通过20%的交叉验证集)
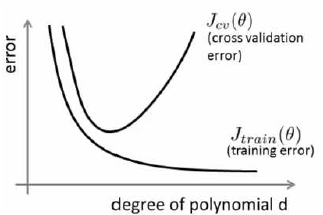
- 多项式 过拟合程度越高, 肯定对于60%训练数据来说, 损失值越小。
- 但用20%的交叉验证集来验证, 适合交叉验证集的多项式, 是图上
凸形图像: 从凸形上升后, 就是过拟合的开始 - 就像上面# 10.3例子
$J_{test}(\theta^{(4)})$ 有损值是最小的
方差 variance:
假设
是高偏差的问题 还是 高方差的问题?
(1) High bias (underfitting)
- high bias 是 underfit 欠拟合
-
$J_{train} \approx$ $J_{cv}(\theta)$ 数值都很大, 但他们的数值 接近。 - 训练集误差和交叉验证集误差近似时:偏差/欠拟合
(2) High variance (overfitting)
- high variance 是 overfit 过拟合
-
$J_{train}$ $J_{cv}(\theta)$ 数值差距很大,$J_{train}$ <<$J_{cv}(\theta)$ (<< 远大于) - 交叉验证集误差远大于训练集误差时:方差/过拟合
Regularization and Bias_Variance
通常我们是使用正则化 Regularization, 来避免过拟合的情况。
模型
正则化的损失函数如图所示

- 目标:
$J(\theta)$ 值小 - 如果$\lambda$ 很大
-
$\theta \approx 0$ , 对于$h(x) = a_0$ 可能就只有bias了。 - 所以它是个 高bias, 欠拟合情况
- 对于
$J_{cv}$ 来说, 偏差就很大 - 对于
$J_{train}$ 来说, 拟合过差(欠拟合), 偏差也很大
- 目标:
$J(\theta)$ 值小 - 如果$\lambda$ 很小, 相当于没有正则化
- 会出现过拟合现象, 因为此时训练到位,
$\theta$ 拟合情况非常的好 - 对于
$J_{cv}$ 来说, 偏差就很大 - 对于
$J_{train}$ 来说, 拟合过好(过拟合), 偏差小
所以, 如何获取合适的的 正则化
(1) 选定一个模型后, 尝试使用不同的
- Create a list of lambdas (i.e. λ∈{0,0.01,0.02,0.04,0.08,0.16,0.32,0.64,1.28,2.56,5.12,10.24});
(2) 分别用cross validation set 带入到模型中, 学习$\theta$, 算出每个不同$\lambda$正则函数的
(3) 选出$J_{min}{cv}(\theta)$ 最小
(4) 将test set 带入到模型中

自己思考, 不懂, 看## 10.5.1 左图右图那里就会明白

Learning Curves

(1) 当训练样本数量少
-
$J_{train}(\theta)$ : 错误error值小 - 对$J_{cv}(\theta)$ 交叉验证集数据或测试集数据 并不友好
- 就是说,
预测程度低。
(2) 当训练样本数量越来越大
-
$J_{train}(\theta)$ 损失, 肯定是越来越大的 -
$J_{cv}(\theta)$ : 但对于 交叉验证集数据或测试集数据, 会稍好些 也就说,预测程度高了些。

模型
只有一个$\theta$ 数据拟合程度不会好的
(1)
- 训练样本少: 误差小。
- 训练样本多:
$J_{train}(\theta)$ 和$J_{cv}(\theta)$ 预测效果就很接近 -
因为只有一个$\theta_1$,
拟合程度不高, 最终趋于某个样子
(2)
- 训练样本少:
$J_{cv}(\theta)$ 肯定误差很大 (此时预测情况不好) - 训练样本多: 但是, 因为是一条直线, 无论如何都无法很好的拟合训练数据, 所以最后趋于平缓。
最终,
= 也就是说在高偏差/欠拟合的情况下,增加数据到训练集不一定能有帮助。


(1)
- 很好理解, 对着数据量增加, 错误会增大, 但是整个趋势是平缓的. 因为拟合训练集更好。
(2)
- 随着数据量增加, 多项式, 高参数(high variance), 最后还是会下降, 但很缓慢的下降。
= 也就是说在高方差/过拟合的情况下,增加更多数据到训练集可能可以提高算法效果。

Deciding What to Do Next Revisited
目标: debug a learning algorithm
高variance: 会出现过拟合情况
(
1. 获得更多的训练样本——解决高variance 对bias无用, 详见## 10.6.2 高偏置 (high bias)
2. 尝试减少特征的数量——解决高variance 存在过拟合情况
3. 尝试获得更多的特征——解决高bias 减少bias的影响
4. 尝试增加多项式特征——解决高bias 多项式增加拟合性, 减少bias的影响
5. 尝试减少正则化程度λ——解决高bias
λ值很大,
6. 尝试增加正则化程度λ——解决高variance λ值很小, 相当于没有加入正则化, 没有解决过拟合问题。(正则化解决过拟合问题)
(1) NN结构, 如果单层, 还节点少, 容易导致高偏差和欠拟合。 A neural network with fewer parameters is prone to underfitting. It is also computationally cheaper.
(2) 很多parameters, 会 导致高方差和过拟合,虽然计算代价比较大,但是可以通过正则化手段来调整而更加适应数据。 A large neural network with more parameters is prone to overfitting. It is also computationally expensive. In this case you can use regularization (increase λ) to address the overfitting.
通常选择较大的神经网络并采用正则化处理会比采用较小的神经网络效果要好。
对于神经网络中的隐藏层的层数的选择,通常从一层开始逐渐增加层数,为了更好地作选择,可以把数据分为训练集、交叉验证集和测试集,针对不同隐藏层层数的神经网络训练神经网络,
-
Lower-order polynomials (low model complexity) have high bias and low variance. In this case, the model fits poorly consistently.
-
Higher-order polynomials (high model complexity) fit the training data extremely well and the test data extremely poorly. These have low bias on the training data, but very high variance.
-
In reality, we would want to choose a model somewhere in between, that can generalize well but also fits the data reasonably well.