This project involves the development of a lexer and parser using Python, aimed at providing foundational components for a compiler or interpreter. The primary goals are to implement a lexical analyzer (lexer) that tokenizes input strings based on predefined rules and a parser that performs syntax analysis using LR(1) parsing techniques.
- Sepehr Bazmi
- Ardalan SoltanZadeh
- Lexer and Parser Implementation using Python
- Authors
- Objectives
- Lexer Implementation (Part 1)
- Main NFA
- Main DFA
- Parser Implementation (Part 2)
- Implement a Lexer: Develop a lexer to tokenize input strings based on predefined rules for operators, keywords, identifiers, and other components.
- Develop an LR(1) Parser: Construct an LR(1) parser to analyze and validate the syntax of tokenized input strings using LR(1) parsing techniques.
- Visualization: Provide visual diagrams to aid in understanding the lexer and parser components, including NFAs, DFAs, and parsing tables.
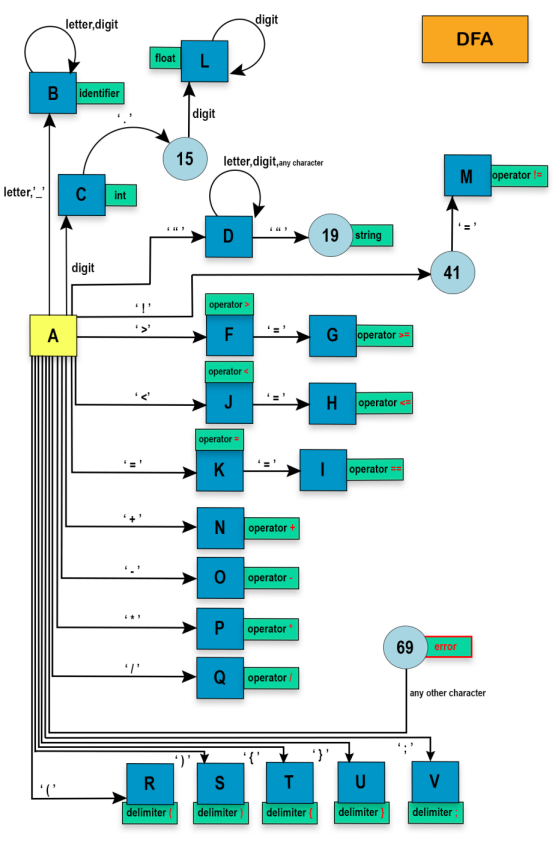
The lexer processes an input string and categorizes its components into tokens. The primary elements identified by the lexer include:
- Operators:
=,/,-,*,+,==,!=,<=,<,>=,> - Single Characters:
=,/,\\,-,*,+,.,",_,>,<,! - Keywords:
int,float,scan,print,if,else,while - Separators:
(,),{,},; - Identifiers: Combinations of letters, digits, and underscores, starting with a letter or underscore
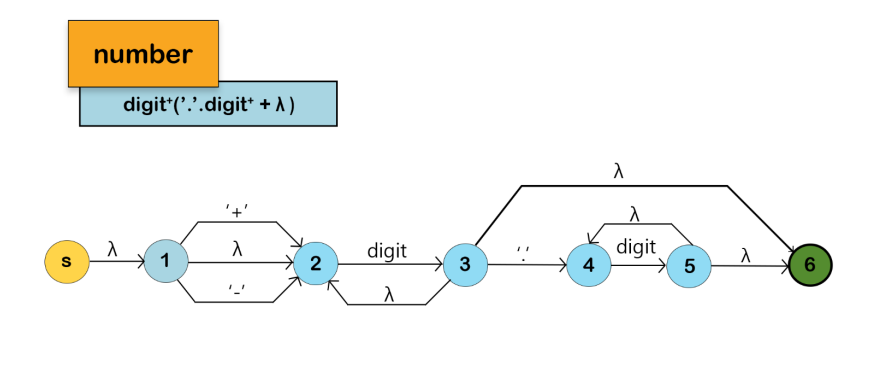
- Integers and Floats: Numeric literals, with or without decimal points
- Strings: Sequences of characters enclosed in double quotes
The lexer assigns a specific class to each token it identifies. These classes include:
OPENPARENTHESISCLOSEPARENTHESISOPENCURLYBRACECLOSECURLYBRACESEMI-COLONFLOATINTSCANPRINTIFELSEWHILEOPERATORIDENTIFIERSTRINGERROR
A lexical analyzer, also known as a scanner or tokenizer, is a component of a compiler that breaks down the source code into a sequence of tokens. Its purpose is to recognize and extract the smallest meaningful units of the programming language, such as keywords, identifiers, literals, and operators.
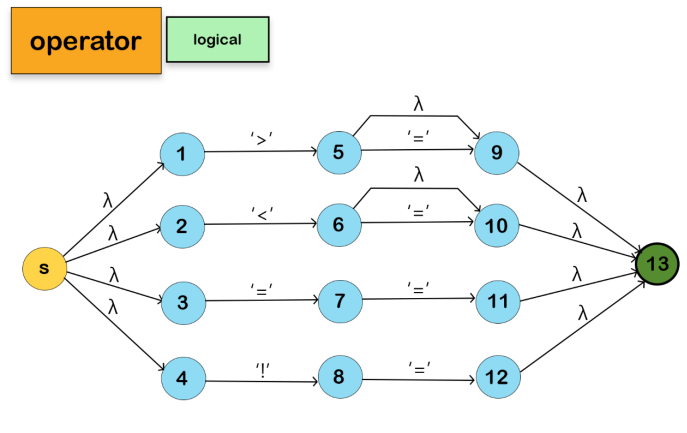
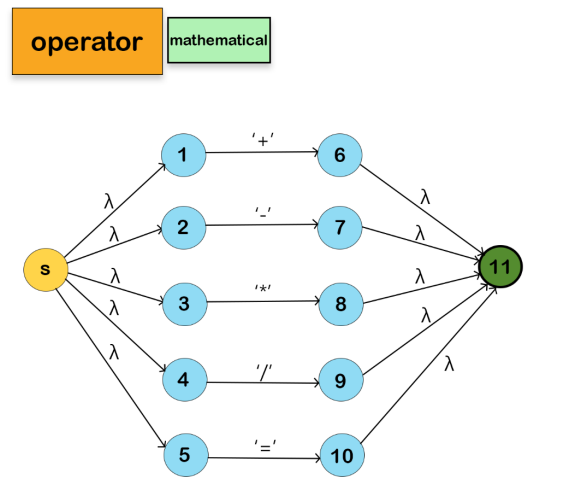
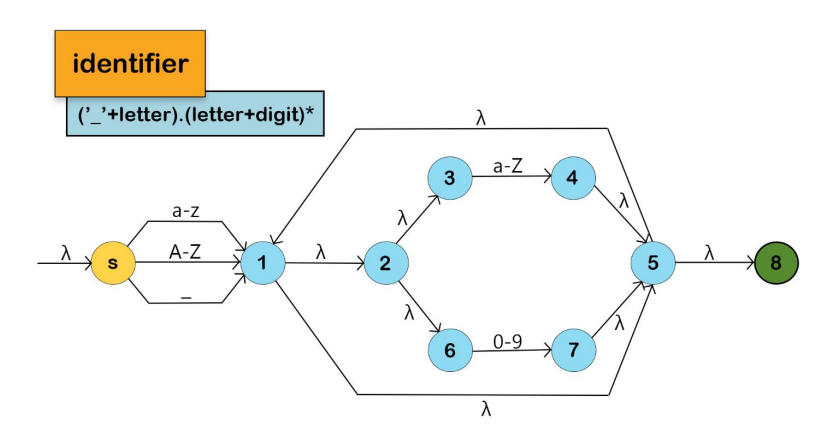
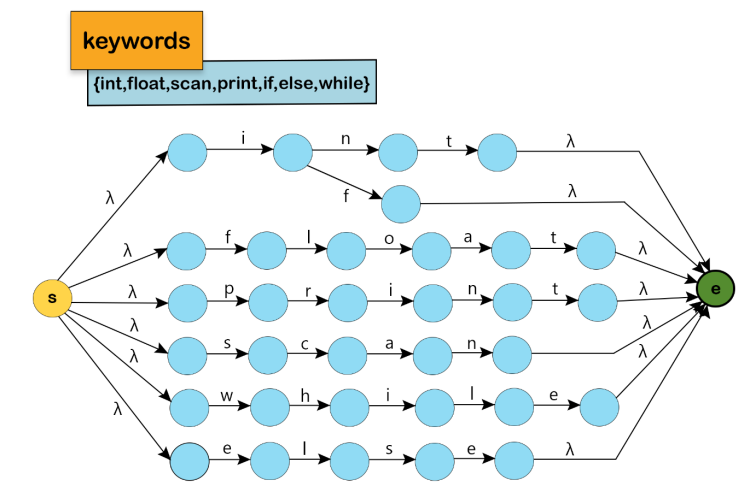
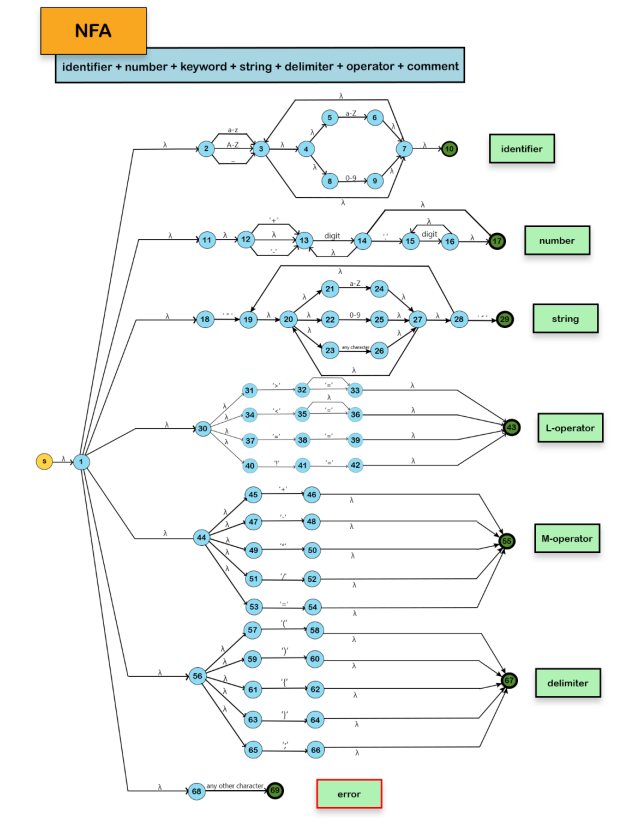
We won't include the Keyword NFA in the Main NFA for the reason mentioned below: The program identifies all the keywords as identifiers; then, if the lexeme is a keyword, it will be returned as a keyword; otherwise, it will be returned as an identifier.
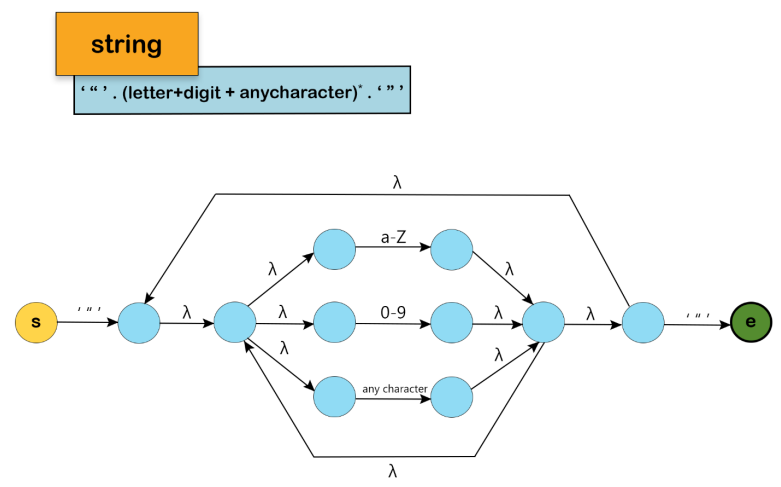
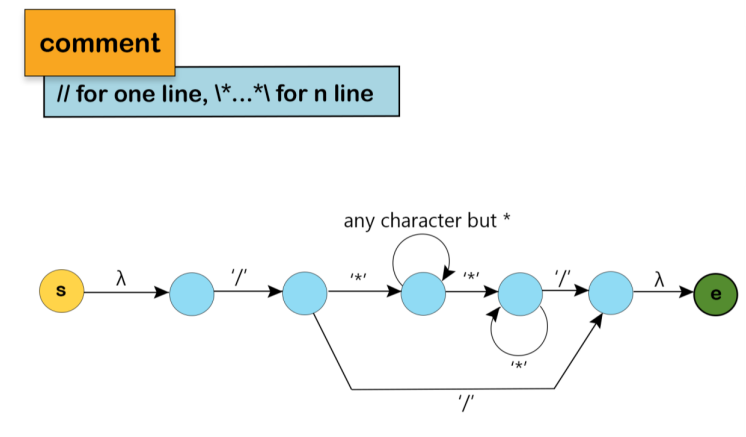
To reduce the lookahead of the main NFA or DFA, comments are excluded from the main NFA or DFA.
Now that we created an NFA for each token, we combine them to create the Main NFA of the scanner. Note that Keyword and comment are not present in the Main NFA, as explained above.
Each square is a combination of several states generated through the epsilon-closure process. For example, the state A in this DFA contains {1,2,11,12,13,18,30,31,34,37,40,44,45,47,49,51,53,56,57,59,61,63,65,58} from the main NFA.
LR(1) parsing is a bottom-up parsing technique used to analyze and validate the syntax of a programming language or any other context-free language. The "LR" stands for "left-to-right" scanning of the input string and "rightmost derivation" of the parse tree, while the "(1)" indicates that the parser considers one lookahead symbol to make parsing decisions.
The LR(1) parser builds a deterministic finite automaton (DFA) known as an LR(1) automaton or LR(1) item set. This automaton represents the state transitions that occur during the parsing process. The DFA is constructed based on a set of augmented grammar rules and their corresponding LR(1) items.
An LR(1) item is a production rule with a dot (.) marker that represents the current position in the production. It also includes a lookahead symbol, which is the symbol that immediately follows the dot.
The LR(1) DFA is then used during the parsing process to perform shift and reduce actions. Shift actions correspond to moving to the next state based on the current input symbol, while reduce actions involve applying a production rule and replacing a group of symbols with a non-terminal.
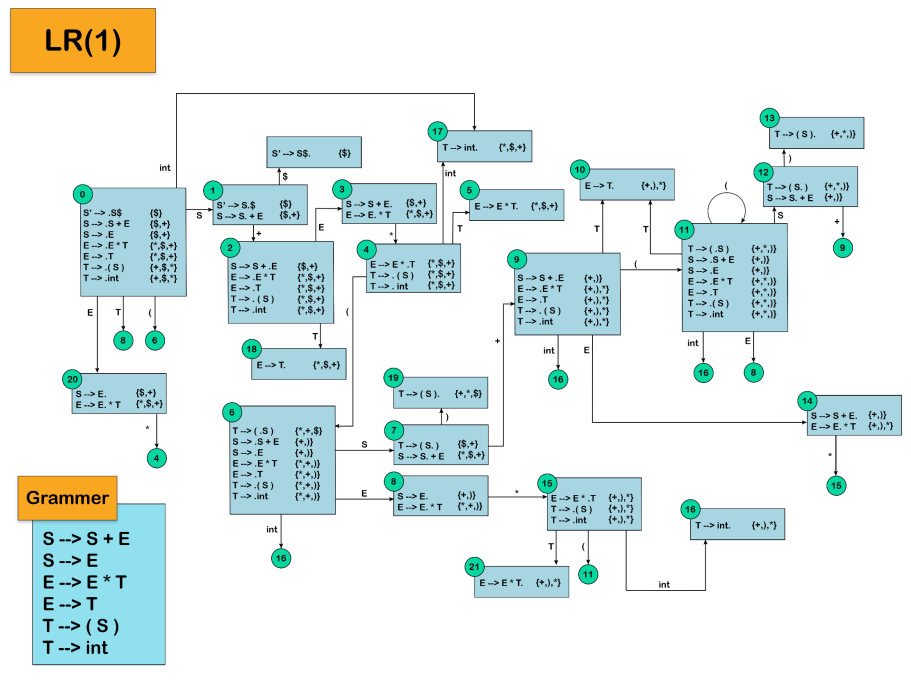
The grammar rules used by the parser are defined as follows:
| Rule ID | Non-terminal | Production |
|---|---|---|
| 0 | S | S → S + E |
| 1 | S | S → E |
| 2 | E | E → E * T |
| 3 | E | E → T |
| 4 | T | T → ( S ) |
| 5 | T | T → int |
The action table defines what action to take based on the current state and the lookahead token.
| State/Token | int | ( | ) | + | * | $ |
|---|---|---|---|---|---|---|
| 0 | S,17 | S,6 | ||||
| 1 | S,2 | - , Accept | ||||
| 2 | S,17 | S,6 | S,4 | |||
| 3 | R,0 | R,0 | S,4 | R,0 | ||
| 4 | S,17 | S,6 | ||||
| 5 | R,2 | R,2 | ||||
| 6 | S,16 | S,11 | ||||
| 7 | S,9 | S,19 | ||||
| 8 | R,1 | S,15 | R,1 | |||
| 9 | S,16 | S,11 | ||||
| 10 | R,3 | R,3 | R,3 | |||
| 11 | S,16 | S,11 | ||||
| 12 | S,9 | S,13 | ||||
| 13 | R,4 | R,4 | R,4 | |||
| 14 | R,0 | S,15 | R,0 | |||
| 15 | S,16 | S,11 | ||||
| 16 | R,5 | R,5 | R,5 | |||
| 17 | R,5 | R,5 | R,5 | |||
| 18 | R,3 | R,3 | R,3 | |||
| 19 | R,4 | R,4 | R,4 | |||
| 20 | S,4 | R,1 | ||||
| 21 | R,2 | R,2 |
The Goto table defines the state transitions based on the current state and the non-terminal being processed.
| State/Non-terminal | S | E | T |
|---|---|---|---|
| 0 | 1 | 20 | 18 |
| 2 | 3 | 18 | |
| 4 | 5 | ||
| 6 | 7 | 8 | 10 |
| 9 | 14 | 10 | |
| 11 | 12 | 8 | 10 |
| 15 | 21 |