A major part of adopting DevOps is creating a better working relationship between development and operations teams. Some suggestions to do this include sitting the teams together, involving them in each other's processes and workflows, and even creating one cross-functional team that does everything. In all these methods, Dev is still Dev and Ops is still Ops.
The term DevOps Engineer tries to blur this divide between Dev and Ops and suggests that the best approach is to hire engineers who can be excellent coders as well as handle all the Ops functions.
In short, a DevOps engineer can be a developer who can think with an Operations mindset and has the following skillset:
- Familiarity and experience with a variety of Ops and automation tools.
- Great at writing scripts.
- Comfortable with dealing with frequent testing and incremental releases.
- Understanding of Ops challenges and how they can be addressed during design and development.
- Soft skills for better collaboration across the team.
The key to being a great DevOps Engineer is to focus on the following:
- Know the basic concepts of DevOps and get into the mindset of automating almost everything.
- Know about different DevOps tools like AWS, GitHub, Puppet, Docker, Chef, New Relic, Ansible, Shippable, JIRA, Slack, etc.
- Have an organization-wide Ops mindset. There are many common Ops pitfalls that developers need to consider while designing software. Reminding developers of these during design and development will go a long way in avoiding these altogether rather than running into issues and then fixing them. Try to standardize this process by creating a checklist that is part of a template for design reviews.
- End-to-end collaboration and helping others solve issues are key.
- You should be a scripting guru — Bash, Powershell, Perl, Ruby, JavaScript, Python, you name it. You must be able to write code to automate repeatable processes.
- Deployment frequency.
- Lead time for code changes.
- Rollback rate.
- Usage of automation tools for CI/CD.
- Test automation.
- Meeting business goals.
- Faster time-to-market.
- Customer satisfaction percentage.
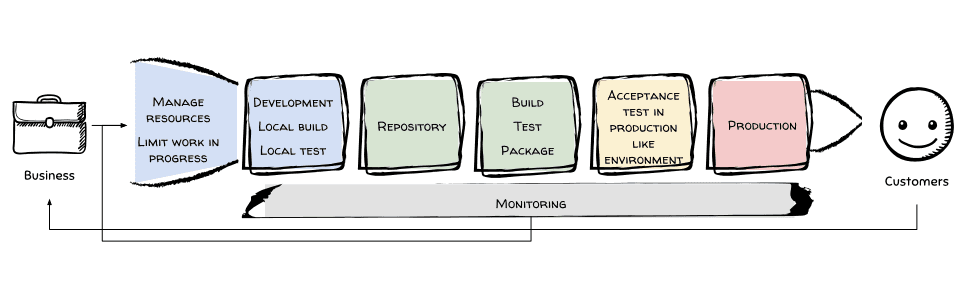
A typical assembly line in my projects looks like this:
- Kanban board to plan work and visualize work in progress (i.e., Trello).
- Developer environment.
- Editor.
- Local build.
- Local test.
- The CI/CD pipeline.
- Code repository (AWS CodeCommit).
- Artifact repository (Amazon S3, Amazon EC2 Container Registry).
- Pipeline (AWS CodePipeline).
- Build and test (AWS CodeBuild).
- Deploy acceptance environment (AWS CloudFormation).
- Run acceptance tests (AWS CodeBuild).
- Deploy production environment (AWS CloudFormation).
- Monitoring (AWS CloudWatch).
- Logging.
- Metrics.
- Alerting.
Docker Adoption Pathway - Part 1 https://dzone.com/articles/docker-adoption-pathway-part-1
Docker Adoption Pathway - Part 2 https://dzone.com/articles/docker-adoption-pathway-part-2
Docker Adoption Pathway - Part 3 https://dzone.com/articles/docker-adoption-pathway-part-3
Docker Adoption Pathway: Part IV https://dzone.com/articles/docker-adoption-pathway-part-4
- You catch build breaks early on.
- In a distributed development environment where developers do not always communicate with one another, continuous integration is a great way to assure the developer that the build he or she is building is the latest one.
- Continuous integration also causes less regression
- The feedback loop is smaller.
- A developer does not have to wait for the end of the day or week to find out how the check-in affected the build.
- Integration testing moves up in the chain.
- Every check-in goes through the integration testing where problems are caught early.
- Continuous integration enforces better development processes.
- Each developer is held accountable.
- You always have a latest-and-greatest build to use in demos, showcases, etc.
- Maintenance overhead often increases.
- Some teams find that the level of discipline required for continuous integration causes bottlenecks. * This often requires a shift in the developer mindset.
- The immediate impact of a check-in often causes a backup because programmers cannot check in partially completed code.
The following procedure shows the recommended steps to check code into source control. To check in code to source control
- Verify that the CI build is working and passing all the unit tests. If it is not, notify the development lead. Do not check in code until the issue is resolved.
- Test all code modifications in a local development environment. Make sure that the unit tests are passing.
- Get the latest code from source control. Resolve any merge conflicts.
- Verify that the unit tests are still passing in the local development environment.
- Check in the modified files. There should be no merge conflicts because you synchronized them in step 3.
- Review the code for missing comments while the CI build is running. After the CI build completes and passes all the unit tests, you can move on to next task. If the CI build fails, fix the issue because you are now blocking other developers from integrating their code.
-
SecDevOps: Embracing the Speed of DevOps and Continuous Delivery in a Secure Environment
-
Continuous Security: Implementing the Critical Controls in a DevOps Environment
-
Understanding Docker, Containers and Safer Software Delivery
https://www.cloudbees.com/sites/default/files/jenkins2-harpreet-blog2-1.png http://cdn.electric-cloud.com/wp-content/uploads/sdlc-tools.jpg
{kind=link}
{kind=link}
https://devops.com/wp-content/uploads/2015/04/cd-devops.png
{kind=link}
http://www.adventone.com.au/wp-content/files_mf/1460512945Devopsfordummies.pdf https://devops.com/31-reference-architectures-devops-continuous-delivery/
All their code is in a single, shared repository, made up of billions of files, all being continuously built and integrated, with 50% of their code being changed each month. Some other impressive statistics on their performance include:
- 40,000 code commits/day.
- 50,000 builds/day (on weekdays, this may exceed 90,000).
- 120,000 automated test suites.
- 75 million test cases run daily.
- 100+ engineers working on the test engineering, continuous integration, and release engineering tooling to increase developer productivity (making up 0.5% of the R&D workforce).
- How do you enforce developers can deploy only services they are allowed to?
- Do you want your developers to view other deployment processes?
- Are you going to purchase a tool or a set of tools or going to check out open-source solutions, or maybe, do you need to develop an in-house solution? Which deployment tools are available? Will they answer my needs?
- How do you integrate with all internal already-existing services (source control, bug tracker, service deployment tracking, and any other already existing services which are affected by such a new process)?
- This deployment tool that we are going to build, enhance, note that it’s another service and thus should be installed also with a deployment tool, should this deployment tool be deployed by the deployment tool itself?
- Do we need infrastructure alerts? (Those are both alerts tightly related to the deployment tool itself it’s stuck or down.)
- Applicative alerts — we want to have alerts on the status of the microservices itself, so do we need any new alerts as part of automating the deployment process?
- How do we validate that a micro service has been installed successfully? What if it has started up, but in the wrong version?
- Which stronger validations to we want to enforce once we let developers deploy their services (obviously, developers come from different places)?
- What if we want to block deployments for a certain region, segment, or certain teams? How can we achieve that? Who should have access to this block?
- Do we want a project per microservice deployment or do we want a global deployment tool where developers can choose the project they want to deploy from a list?
- Are there new conventions and enforcements we might want to enforce? Should RND project names, for example, match RPM name? Or do we rather configuration?
- How do we support gradual rollout?
- Should we allow deployment to cross the datacenter or let the developer deploy the datacenter by datacenter?
- Should developer care we have multiple data centers? (All he wants is to run his code.)
- Should our tool support both legacy platforms and modern ones such as Kubernetes and Swarm or do we solve one problem at a time? Should we have a shared interface?
- How do we integrate users management with existing user and group management already existing?
- What if a developer post-deployment needs to access (SSH) one of his services and do an operation? Should we enable him or her to do that? Or direct him or her to the production team for such access?
- Which additional visibility on services should we enable to the developer?
- How do we manage rollback? Now that developers are going to run much more deployments we need to support a quick rollback, possibly one-click rollback, is it the same process as upgrade-only a different version or it's actually a different rollback. What if rollback fails? Do we provide enough tools for developers to mitigate such problems? Or should we not?
- What is the discovery mechanism? Do we let developers deploy to specific services or only by general discovery mechanism (such as service name deployment)?
- If a developer has a pull request, should he merge it externally to the deployment process or have the deployment pipeline do it for him?
- Which info should we show the deployer prior to him making a deployment? Should we show warnings?
- If a deployment failed in one of the stages, how do we make sure the taget deployment environment get’s clean?
- If deployment process involves changes to database how will the deployment pipeline support that? Should it support it at all?
- How can the deployment process support both standard microservices and other types of jobs such as Hadoop jobs, Spark jobs? should we mess with jobs at all? maybe at future phases?
- Should the deployment process support the deployment of intrastructure- and production-related changes such as network configuration?
- How will the deployment pipeline be integrated with an already-existing system and end-to-end tests?
- Would you like to make sure the same deployment pipeline is run on production, QA, CI, local development environment, or going to fall into the trap of having it a production only tool?
- Which insights and analytics do you want to derive from such a deployment pipeline?
- Which system tests and end-to-end tests are you going to create for this deployment pipeline and how are you going to run them? (Testing the deployment tool itself.)
- How do you create such a pipeline process without introducing yet another layer to manage, could this layer save other deployments layers from happening or would it add an additional one?
- Which resiliency mechanisms do you need in this deployment tool? When would you want to retry, for example? Which timeouts do you need in place?
- Is the deployment pipeline a microservice? Is it a set of microservices? A monolith, God forbid (or God bless)?
- Many more. But you get the idea.
CALMS is a conceptual framework for the integration of development and operations (DevOps) groups, functions and systems within an organization; the acronym stands for: Culture Automation Lean Measurement Sharing
What DevOps Is and What It Is Not https://dzone.com/articles/what-devops-is-and-is-not
Its core values are Culture, Automation, Lean, Measurement and Sharing (CALMS). http://www.ranger4.com/ranger4-devops-blog/i-got-devops-certified
Why Continuous Delivery Is Key for Developer Career Success https://dzone.com/articles/why-continuous-delivery-is-key-for-developer-caree
Starting and Scaling DevOps in the Enterprise: The Basic Deployment Pipeline https://dzone.com/articles/starting-and-scaling-devops-in-the-enterprise-the https://devops.com/get-devops-right-standout-technologies/ https://www.atlassian.com/blog/devops/how-to-choose-devops-tools https://dzone.com/articles/what-to-know-about-the-devops-journey-of-your-orga?